Vector embeddings are the backbone of modern AI systems, encapsulating complex patterns from text, images, audio, and other data types. However, even the best embeddings are essentially useless without solid systems in place to store, retrieve, and manage them efficiently at scale.
This often-overlooked aspect, known as Vector Search & Management (VS&M), is crucial for turning your data into something that actually drives value. Without it, systems can’t live up to their full potential. This article presents a systematic approach to vector search and management based on three key pillars: (1) access patterns, (2) performance requirements, and (3) data characteristics.
By evaluating your system through this framework, you’ll make informed architectural decisions that balance speed, accuracy, cost, and scalability. In Part 1 we explored how to work with the right Data Sources. Now we’ll tackle the next layer: transforming those embeddings into actionable systems through effective vector search and management.
A Systematic Approach to Vector Search & Management
Over the past few years building ML systems, I’ve seen teams put serious efforts into generating sophisticated vector embeddings. They capture subtle patterns across text, images, audio — you name it. But too often, that potential gets stuck. Because no matter how good your embeddings are, they’re only as useful as your ability to retrieve and act on them — fast, accurately, and at scale.
Without proper vector search and management:
-
You can’t surface relevant results
-
Embeddings go stale instead of improving with feedback
-
Latency and costs spiral out of control as your data grows
This is the part that makes the system work. It’s the engine behind semantic search, recommendations, and all the smart features users expect. Skip it, and you’ve built a brain without a nervous system. Before diving into technical details, let’s establish the decision framework that will guide our implementation choices:
(1) Define System Requirements
- Performance targets (latency, throughput, recall)
- Data characteristics (volume, dimensionality, update frequency)
- Operational constraints (cost, infrastructure, team expertise)
(2) Choose Access Patterns
- Static in-memory (small, stable datasets)
- Dynamic access (large or frequently changing datasets)
- Batch processing (offline analytics and index building)
(3) Select Technical Implementation
- Search algorithms (exact vs. approximate)
- Optimization techniques (quantization, filtering)
- Storage and indexing strategies
(4) Establish Evaluation Framework
- System metrics (throughput, latency, resource utilization)
- Quality metrics (recall, precision, relevance)
- Operational metrics (build time, update latency)
This framework ensures that technical decisions align with your specific use case and business requirements.
Core Concepts
Vector Search & Management consists of two interconnected components:
- Vector Management: The infrastructure for storing, indexing, updating, and maintaining vector embeddings and associated metadata. Getting this right ensures data freshness, accessibility, and prepares vectors for downstream tasks.
- Vector Search: The query engine that enables fast and relevant retrieval from potentially massive vector datasets. This is where the magic of finding similar items happens at scale.
Why Mastering Vector Search & Management is Non-Negotiable
Effective vector search and management capabilities unlock three key benefits:
- Embedding Evaluation and Improvement: How do you know if your embeddings are truly performing well in practice? To answer this, you need to query them against representative datasets and evaluate them using metrics like recall@k. Without efficient vector search, evaluating embeddings across millions or billions of items becomes prohibitively slow, restricting tests to small samples or simple cases. Without robust vector search and management, you’re left with a limited understanding of embedding performance in production.
- Fresh, Relevant Inputs to ML Models: Models performing Transfer Learning, RL, Recommendations, Anomaly Detection, or Active Learning rely on embeddings as input. Moreover, vector search capabilities allow for the efficient retrieval of specific vectors needed for complex training tasks (such as finding hard negatives for active learning). Without solid vector search and management, models can underperform, and training processes become inefficient.
- Real-Time Applications Capabilities: User-facing applications like semantic search, recommendations, and visual similarity search require low-latency and high-throughput query responses, especially as the data is constantly changing. While embeddings define similarity, it’s the vector search engine that delivers results in milliseconds, at scale. Traditional databases struggle to meet these demands, making specialized vector search and management systems. Without these capabilities, user experience suffers significantly.
Navigating the Design Trade-offs for Vector Search & Management
Successfully implementing Vector Search & Management requires balancing competing priorities. Let’s examine the key design dimensions:
Performance Requirements
Every vector search system makes tradeoffs between:
(1) Speed/Latency: How quickly must the system respond? Is sub-100ms latency required, or is a second acceptable? Lower latency requirements typically demand more computational resources and may require compromises in accuracy.
(2) Accuracy/Recall: What level of precision is required? Is finding 95% of relevant results sufficient, or must you capture 99.9%? Higher recall requirements typically increase computational costs and may reduce speed.
(3) Cost: What budget constraints exist? Higher performance generally requires more resources, leading to increased costs. Understanding your economic constraints is essential for sustainable design.
(4) Scalability: How must the system scale as data grows? Does it need to handle millions of queries across billions of vectors? Scalability requirements influence architecture choices from the start.
Data Characteristics
Understanding your data is crucial for vector search design:
(1) Data Volume: The number of vectors in your dataset fundamentally impacts architecture choices. Systems handling thousands, millions, or billions of vectors require different approaches.
(2) Vector Dimensionality: Higher dimensions (1024+) versus lower dimensions (128) affect memory usage, computational requirements, and algorithm selection.
(3) Update Frequency: How often vectors change shapes your entire pipeline:
- Real-time streaming: Immediate updates requiring continuous indexing
- Frequent batches: Regular updates (hourly/daily) allowing periodic reindexing
- Infrequent bulk loads: Rare updates enabling static optimization
Query Access Patterns
Consider how users and systems interact with your vector data determines architecture:
(1) High-throughput single lookups: Quick individual queries requiring optimized retrieval paths
(2) Complex batch queries: Analytical workloads processing multiple vectors simultaneously
(3) Filtering before search: Scenarios requiring metadata filtering before or alongside vector similarity
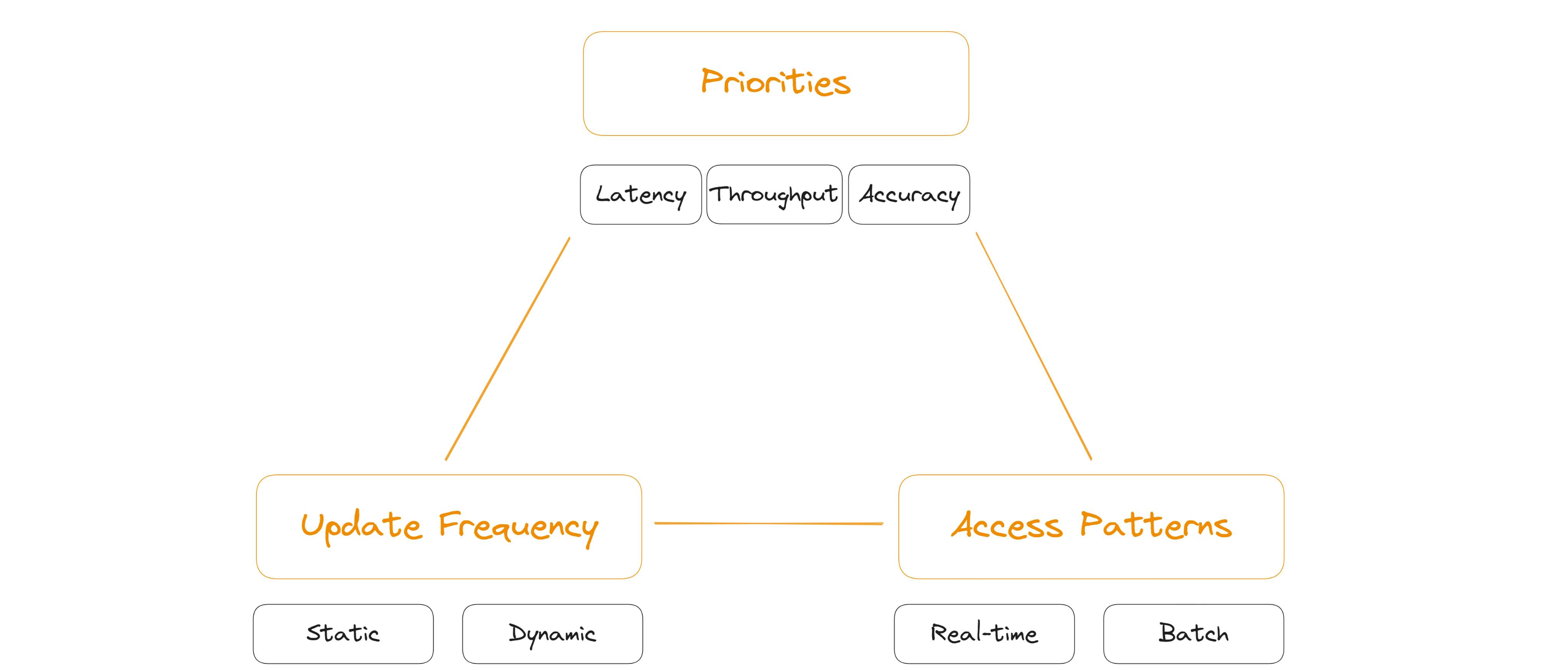
One way to think about the design process is to visualize it as a triangle, where each of these factors forms one corner, and the optimal design lies at the intersection of all three:


Every project involves making conscious trade-offs, especially when defining your priorities and deciding which aspects to prioritize. For example, in an e-commerce recommendation system, the need for low latency (speed) and real-time updates may take precedence. This would require prioritizing fast retrieval of vectors as soon as a user interacts with the system. However, this could mean accepting slightly lower recall rates or higher infrastructure costs due to the demands of maintaining up-to-date, fast, and relevant data.
On the other hand, in an offline analytical system, you may prioritize accuracy over latency, with batch processing and deeper analysis becoming the primary focus. Understanding how your use case’s priorities affect performance and architecture choices is vital.
So, how do we achieve the desired speed and accuracy within these constraints? This brings us squarely to the engine room of Vector Search.
The Core Engine: Nearest Neighbor Search Algorithms
Vector search hinges on speed — the ability to quickly scan a dataset and calculate the similarity between vectors. At the core of this task is Nearest Neighbor (NN) search. The goal is straightforward: given a query vector, find the vectors in your indexed dataset that are closest according to a chosen distance metric (such as Cosine Similarity or Euclidean Distance). There are multiple ways to perform nearest neighbor search. Let’s start with the most straightforward approach.
Full Scan (Brute Force Approach)
Imagine we have a dataset of 1 million 1000-dimensional vectors and need to find similar vectors for a given query. A naive approach would compare the query vector to every single vectors— performing 1 billion operations (1M vectors * 1000 dimensions) per query.
Full scan is a brute-force method, sequentially checking every data point in the dataset to ensure it finds the absolute nearest neighbors. It’s simple to implement and doesn’t require complex indexing. For smaller datasets — under a million vectors, especially those that don’t change often — this approach may work fine and can even be a good starting point. It guarantees perfect recall.
However, as the dataset grows or if data freshness becomes crucial, the practicality of full scan quickly diminishes. Once you surpass the million-vector mark or need frequent updates, the computational cost of each query increases significantly. What was once an acceptable latency becomes a bottleneck, making it unsuitable for real-time or interactive applications.
Performance characteristics:
- Latency: O(n×d) where n=number of vectors and d=dimensions
- Memory: O(n×d) — requires full dataset in memory for optimal performance
- Accuracy: 100% recall (guaranteed to find true nearest neighbors)
- Build time: O(1) — no indexing required
In my experience, relying solely on full scan for large, dynamic production systems is rarely a viable option. We need faster alternatives.
Approximate Nearest Neighbor (ANN) Algorithms
This is where Approximate Nearest Neighbor (ANN) algorithms enter the picture. ANN algorithms introduce approximations for dramatically improved speed. Here are key approaches:
(1) Tree-based methods (KD-trees, Ball trees)
These split the vector space into nested regions, so you don’t have to search everything.
- Great for low-dimensional data (think ≤20 dimensions)
- Struggle badly in high dimensions due to the “curse of dimensionality”
- Best for small or structured datasets where exact partitioning pays off
(2) Locality-Sensitive Hashing (LSH)
This hashes vectors so that similar ones land in the same bucket more often than not.
- Scales well with both dimension count and dataset size
- Doesn’t need to scan the whole space
- But: requires careful tuning of hash functions and thresholds to get good recall
(3) Graph-based methods
These build a graph where each node (vector) connects to its nearest neighbors — search becomes fast traversal.
- HNSW (Hierarchical Navigable Small World): Builds a multi-layer graph to navigate large datasets efficiently
- NSG (Navigable Spreading-out Graph): Focuses on building a well-pruned graph to minimize hops and reduce search cost
- DiskANN: Optimized for billion-scale datasets, designed to run off SSDs instead of keeping everything in RAM
The key advantage of ANN over brute-force search is its ability to handle large-scale datasets efficiently. Benchmarking results, such as those from ANN-benchmarks, consistently show this tradeoff: brute force provides the highest precision but supports fewer queries per second (QPS). ANN algorithms, on the other hand, enable much higher QPS, making them ideal for real-time systems — though there’s usually a slight reduction in recall, depending on the algorithm and how it’s tuned.


Code Example: Full Scan vs. ANN
To make these concepts more concrete, let’s demonstrate a basic comparison between a full scan (linear search) and an ANN approach using the IVFFlat index using the popular Faiss library.
import numpy as np
import faiss
import time
# 1. Create a synthetic dataset
num_vectors = 1000000 # One million vectors
vector_dim = 1000 # 1000 dimensions
print(f"Creating dataset with {num_vectors} vectors of dimension {vector_dim}...")
dataset = np.random.rand(num_vectors, vector_dim).astype('float32')
# 2. Define a sample query vector
query_vector = np.random.rand(vector_dim).astype('float32')
query_vector_reshaped = query_vector.reshape(1, vector_dim)
# --- Linear Scan (Full Scan) Example ---
print("n--- Linear Scan (using IndexFlatL2) ---")
# 3. Create a Faiss index for exact L2 distance search (Full Scan)
index_flat = faiss.IndexFlatL2(vector_dim)
# 4. Add the dataset vectors to the index
print("Adding vectors to IndexFlatL2...")
index_flat.add(dataset)
print(f"Index contains {index_flat.ntotal} vectors.")
# 5. Perform the search
print("Performing linear scan search...")
start_time = time.time()
distances_flat, indices_flat = index_flat.search(query_vector_reshaped, k=1)
end_time = time.time()
# On typical hardware, this might take 1-2 seconds for this dataset size
print(f"Linear scan time: {end_time - start_time:.4f} seconds")
print(f"Nearest neighbor index (Linear): {indices_flat[0][0]}, Distance: {distances_flat[0][0]}")
# --- Approximate Nearest Neighbor (ANN) Example ---
print("n--- ANN Scan (using IndexIVFFlat) ---")
# 6. Define and create an ANN index (IVFFlat)
# IVF1024 partitions the data into 1024 clusters (voronoi cells)
nlist = 1024 # Number of clusters/cells
quantizer = faiss.IndexFlatL2(vector_dim)
index_ivf = faiss.IndexIVFFlat(quantizer, vector_dim, nlist)
# 7. Train the index on the dataset (learns the cluster centroids)
# This is a one-time operation that can be slow but improves query performance
print(f"Training IndexIVFFlat with {nlist} clusters...")
index_ivf.train(dataset)
print("Training complete.")
# 8. Add the dataset vectors to the trained index
print("Adding vectors to IndexIVFFlat...")
index_ivf.add(dataset)
print(f"Index contains {index_ivf.ntotal} vectors.")
# 9. Perform the ANN search
# nprobe controls search accuracy vs. speed tradeoff
# Higher values = better recall but slower search
index_ivf.nprobe = 10 # Search within the 10 nearest clusters
print(f"Performing ANN search (nprobe={index_ivf.nprobe})...")
start_time = time.time()
distances_ivf, indices_ivf = index_ivf.search(query_vector_reshaped, k=1)
end_time = time.time()
# On typical hardware, this might take 10-20ms - about 100x faster than brute force
print(f"ANN scan time: {end_time - start_time:.4f} seconds")
print(f"Nearest neighbor index (ANN): {indices_ivf[0][0]}, Distance: {distances_ivf[0][0]}")
# Expected recall rate at nprobe=10 is approximately 90-95%
# To verify, we could compute overlap between exact and approximate results
In this example we first create a large dataset of random vectors. We use IndexFlatL2 for the linear scan. This index simply stores all vectors and compares the query to each one during search — our brute-force baseline.
Next, we switch to IndexIVFFlat, a common ANN technique. This involves an extra training step where the index learns the structure of the data partitioning it into cells (or Voronoi cells). During the search, the nprobe parameter determines how many partitions are checked, allowing the algorithm to intelligently sample only a subset of the data, significantly reducing the number of comparisons needed.
Running this code (actual times depend heavily on hardware) typically demonstrates that the ANN search (IndexIVFFlat), despite the initial training overhead, performs the search operation significantly faster than the linear scan (IndexFlatL2), highlighting the practical speed advantage of ANN methods for large datasets.
However, it’s important to note that different ANN implementations come with their own optimization tradeoffs. IndexIVFFlat is just one option, and selecting the right method involves evaluating tradeoffs in speed, accuracy, memory usage, and indexing time. Each approach has its strengths, so benchmarking various methods is crucial for finding the optimal balance based on your dataset and query patterns.
As vector datasets grow massive, memory consumption becomes a significant challenge, especially when dealing with millions or billions of high-dimensional vectors. When the dataset exceeds the available RAM on a single machine, engineers often resort to sharding the index across multiple machines, introducing operational complexity and increasing infrastructure costs.
One effective solution to this problem is quantization, a technique designed to reduce memory footprint by compressing the vector data. The goal is to represent high-precision floating-point vectors with less data, typically using methods that map continuous values to a smaller set of discrete representations. By doing so, quantization reduces storage space requirements, which can help fit large indexes onto fewer machines or even a single machine. There are several approaches to vector quantization, with three common types being:
(1) Scalar Quantization
This technique reduces the precision of each dimension in a vector. Instead of using high-precision 32-bit floats, each dimension may be stored using fewer bits, like 8-bit integers. SQ offers a solid balance between compression, search accuracy, and speed, making it a popular choice for reducing memory usage.
Performance impact:
- Memory reduction: 4x (32-bit → 8-bit)
- Speed impact: Minimal (sometimes faster due to reduced memory bandwidth)
- Accuracy impact: Typically 1–3% recall reduction
- Use case: Good general-purpose option for initial memory optimization
(2) Binary Quantization
Takes compression further by representing vector components with binary codes, often using just 1 bit per component or group of components. This results in high compression and very fast distance calculations (e.g., Hamming distance). However, BQ can lead to significant information loss, which can reduce accuracy, so it is best suited for cases where speed is critical and the data is well-suited for binary representation.
Performance impact:
- Memory reduction: 8–64x depending on configuration
- Speed impact: Complex distance calculations can be slower
- Accuracy impact: 5–15% recall reduction (configuration dependent)
- Use case: Large-scale systems where memory is the primary constraint
(3) Product Quantization
This technique takes a different approach. It splits each high-dimensional vector into smaller sub-vectors, which are quantized independently using clustering techniques like k-means. Each sub-vector is represented by a code from a codebook, leading to substantial compression. While PQ achieves low memory usage, the process of calculating distances and performing searches can be more computationally intensive than SQ, resulting in slower query times and possibly lower accuracy at similar compression levels.
Performance impact:
- Memory reduction: 32x compared to 32-bit floats
- Speed impact: Very fast using hamming distance calculations
- Accuracy impact: Significant (20%+ recall reduction)
- Use case: Ultra-high throughput applications where speed trumps perfect accuracy
Quantization techniques are often used in conjunction with ANN search methods, not as alternatives. For instance, Faiss indexes like IndexIVFPQ combine an IVF structure (for fast candidate selection using ANN) with Product Quantization (to compress the vectors within each list). This hybrid approach enables the creation of high-performance vector search pipelines that efficiently handle large datasets in both speed and memory. Selecting the right quantization strategy, like choosing the optimal ANN method, requires understanding the tradeoffs and aligning them with your system’s needs and data characteristics.
Filtering Strategies
In most real-world scenarios, combining vector similarity with metadata filtering is essential. Think about queries like “find similar products that are in stock and under $50.” This hybrid search presents its own set of challenges:
Filtering Approaches
(1) Pre-filtering
This approach filters the data based on metadata before diving into vector similarity. It works best when the metadata filter is highly selective (e.g., finding products under $50). This requires an integrated approach, where both vectors and metadata are indexed together.
Example: You first filter out products that are under $50, then compute the similarity only on the subset that meets that criterion.
(2) Post-filtering
With post-filtering, you perform the vector similarity search first, then apply your metadata filters afterward. This is a solid option when the metadata filter isn’t particularly selective. The downside? It can get inefficient when working with large datasets that have strict filters.
Example: Find the top 1000 similar products, then narrow them down to those under $50.
(3) Hybrid filtering
Hybrid filtering strikes a balance — using metadata to reduce the search space before fine-tuning it with vector search. This approach often uses a combination of inverted indexes and vector indexes to get the best of both worlds. It’s usually the most efficient and flexible option for most applications.
Example: Use metadata (like category and price range) to limit the search space, then zero in on the best matching vectors.
Implementation Strategies
(1) Inverted Index + Vector Index
With this strategy, you create separate indexes for metadata and vectors. First, the metadata index helps you identify a smaller set of candidates. Then, you apply the vector search only to those candidates, saving time. This method is ideal when your filters are really selective.
(2) Joint Indexing
Here, you combine metadata directly into the vector index. Imagine IVF clusters that also include metadata attributes. This enables the system to efficiently prune irrelevant candidates during the search. Joint indexing works best when there’s a close relationship between metadata and vector similarity.
(3) Filter-Aware ANN
This method goes deeper by modifying the ANN algorithm itself to take the metadata filter into account during graph traversal. It’s a bit more complex but can significantly speed up your queries. More and more vector databases are starting to offer this as a built-in feature, making it easier to implement at scale.
Key Access Patterns
How your application accesses vector data has a major impact on performance, storage design, and overall system architecture. Matching the access pattern to the needs of your application is key to building an efficient retrieval system. Let’s examine some common patterns.
Static In-Memory Access
One of the most straightforward access patterns for vector search is static in-memory access. This approach is ideal when working with relatively small datasets — typically under a million vectors — that don’t change frequently. In this setup, the entire vector index is loaded into memory at application startup. Because all vector comparisons happen locally within the process, there’s no need to communicate with external storage during queries. The result is extremely fast retrieval, with minimal system complexity.
Static in-memory access is well-suited for use cases that demand low-latency responses and can fit their vector data comfortably within a single machine’s RAM. It’s a practical choice when the dataset is small and stable, and simplicity and speed are top priorities.
Implementation Considerations
- For lightweight setups — say, under 100,000 vectors — NumPy might be enough. It allows for efficient in-memory operations like cosine similarity using simple arrays. This is a good option when query complexity is low and performance needs are modest.
- As datasets approach the million-vector range, performance demands tend to increase. In those cases, libraries like Faiss offer more efficient indexing and similarity search, including support for ANN and quantization, while still operating entirely in memory.
- If your application needs to filter by metadata alongside vector similarity — or if your in-memory dataset is large but still fits in RAM — tools like LanceDB or Chroma can be a better fit. These “in-process vector databases” run inside your application, combining the speed of local memory access with the structure and flexibility of a database, without the overhead of network calls.
Service Restart Implications
One downside of this pattern is what happens when the service restarts. Because all data lives in memory, the full vector dataset must be reloaded on startup. This can introduce noticeable delays, especially with large indexes, and temporarily impact system availability during initialization. If startup time is critical, you’ll need to account for this when designing your deployment strategy.
Dynamic Access
Dynamic access patterns are built for production-scale systems where vector datasets are too large or too volatile for static in-memory approaches. This becomes especially important when working with more than a million vectors or when embeddings are constantly being added, updated, or replaced — like in use cases involving live sensor data, real-time user behavior, or streaming analytics.
Unlike static setups, where data is loaded and held in memory, dynamic access offloads storage and retrieval to external vector databases or search engines. These systems are purpose-built for handling high-dimensional data at scale, offering features like persistent storage, incremental updates, and real-time indexing. They’re designed to maintain responsiveness even as data evolves rapidly.
Different categories of systems support dynamic access, each with its own performance characteristics and tradeoffs. Choosing the right one depends on your specific requirements — data volume, query patterns, latency tolerance, and operational complexity
-
Vector-Native Vector Databases (e.g., Weaviate, Pinecone, Milvus, Vespa, Qdrant): are optimized specifically for storing, indexing, and conducting fast similarity searches on high-dimensional vector data. Their design focuses on vector operations, making them highly efficient for this purpose. However, they may lack the comprehensive features found in general-purpose databases for handling traditional structured or unstructured data.
-
Hybrid Databases (e.g., MongoDB Atlas Vector Search, PostgreSQL with pgvector, Redis with redis-vss): are well-established databases (NoSQL, relational, key-value) that have incorporated vector search through extensions or built-in features. They offer the benefit of managing both vector and traditional data types in one system, providing flexibility for applications that require both. However, their vector search performance may not always match the specialized capabilities of vector-native databases.
-
Search Tools with Vector Capabilities (e.g., Elasticsearch, OpenSearch): originally built for text search and log analytics, these search engines have integrated vector search features. For organizations already using them, this enables the possibility of leveraging existing infrastructure for both text and vector similarity searches. However, their vector search performance and available algorithms might not be as specialized or efficient as those found in dedicated vector databases.


Batch Access
While dynamic access focuses on live queries against constantly changing data, batch access is the go-to pattern for handling large vector datasets that require offline, non-real-time processing. This approach is ideal when dealing with massive datasets (usually over one million vectors) where queries are processed in large, collective batches rather than interactively.
Batch processing is particularly valuable for foundational Vector Management tasks critical for efficient Vector Search services, such as:
- Initial index building for very large datasets.
- Periodic model training or retraining using vector representations.
- Precomputing nearest neighbors or other analyses across the entire dataset.
- Data cleaning, transformation, or enrichment tasks applied to vectors in bulk.
To optimize batch processing for your application, it’s crucial to consider several factors:
(1) Storage Technologies
Reliable storage is essential for housing large vector datasets and ensuring they are accessible for batch processing. The choice of storage technology impacts scalability, access speed, and integration with processing pipelines. Below are some common options:
- Object Storage (e.g., Amazon S3, Google Cloud Storage, Azure Blob Storage): This storage solution is highly scalable and cost-effective, making it suitable for storing large, static vector sets. It integrates well with cloud-based processing engines like Spark and Flink. However, its primary drawback is higher access latency compared to file systems, making it less ideal for I/O-intensive operations that require rapid, low-latency reads or writes. Object storage is best suited for data at rest rather than real-time processing.
- Distributed File Systems (e.g., HDFS, GlusterFS): These systems are designed for storing massive datasets across multiple servers, offering high-throughput access ideal for big data frameworks like Hadoop and Spark. They provide data redundancy and are optimized for sequential reads. However, they come with the complexity of setup, management, and maintenance, which can be more cumbersome than managed cloud object storage solutions.
(2) Data Serialization Formats
To store vectors efficiently for batch processing, it’s crucial to select data formats that reduce storage space and enable fast read/write operations. Here are two commonly used serialization formats:
- Avro and Parquet: These are binary serialization formats widely used in the big data ecosystem (e.g., Hadoop, Spark). Both offer excellent compression and support schema evolution, which is particularly useful if vector dimensions or metadata change over time. Avro is typically preferred for row-oriented operations or write-heavy workloads, while Parquet, with its columnar format, is optimized for read-heavy analytical queries, which is ideal for batch processing jobs. These formats also integrate seamlessly with distributed processing engines and cloud storage, making them versatile options for large-scale data operations.
- Compressed NumPy Arrays: For simpler, Python-based pipelines, serializing NumPy arrays using formats like .npz or custom serialization with compression libraries such as zlib or lz4 is an effective approach. This method is particularly useful in scientific Python environments and integrates easily with libraries like NumPy and SciPy. However, it may not be as portable or performant for large-scale, multi-language environments, where formats like Parquet would typically offer better scalability and performance.
(3) Execution Environment
When choosing where and how your batch jobs will run, you must decide between self-managed infrastructure and cloud services:
- On-Premise Execution: Using tools like Apache Hadoop or Apache Spark on your own infrastructure gives you complete control over the environment, security, and configuration. However, this comes with significant costs related to infrastructure setup, maintenance, and the need for operational expertise. Additionally, scaling resources can be less flexible and more complex compared to cloud solutions.
- Cloud Services: Platforms like Amazon EMR, Google Cloud Dataproc, or Azure HDInsight provide managed batch processing solutions based on popular frameworks like Spark. These services abstract away much of the infrastructure management, offering scalability on a pay-as-you-go basis and easy integration with other cloud services, such as object storage. The tradeoff here is that you may lose some fine-grained control over your environment and could face potential vendor lock-in.


In summary, choosing the right storage technology, data serialization format, and execution environment for batch vector processing is a complex decision. It depends on factors like:
- The size of your vector dataset.
- Whether the data is static or dynamic (i.e., how often it changes).
- Scalability needs for your workloads.
- Whether the dataset is distributed across multiple servers.
- The requirement (or lack thereof) for real-time querying alongside batch jobs.
- Integration needs with other big data processing tools or frameworks.
- The level of control you need over the processing environment.
- Available resources (time, budget, expertise) for setup and maintenance.
Conclusion: Building Effective Vector Search Systems
As we’ve discussed, Vector Search & Management is the critical operational layer that transforms abstract embeddings into valuable applications. By systematically addressing the three pillars of our framework — access patterns, performance requirements, and data characteristics — you can build systems that deliver both technical excellence and business value.
Putting It All Together: Key Implementation Checklist
(1) Define clear requirements:
- Document latency, throughput, and recall targets
- Establish update frequency needs
- Identify filtering and querying patterns
(2) Choose appropriate architecture:
- Select access pattern (static, dynamic, batch)
- Determine vector database or storage solution
- Design for appropriate scale and growth
(3) Optimize for your use case:
- Select and tune ANN algorithms
- Implement appropriate quantization
- Design efficient filtering strategies
(4) Implement comprehensive evaluation:
- Establish quality metrics baseline
- Monitor system performance
- Track business impact metrics
(5) Plan for operational excellence:
- Design for observability
- Implement error handling
- Create testing and validation framework
In the next part of The AI Engineer’s Playbook, we’ll explore how to effectively leverage these vector capabilities in real-world AI applications.




{kind=link}