Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
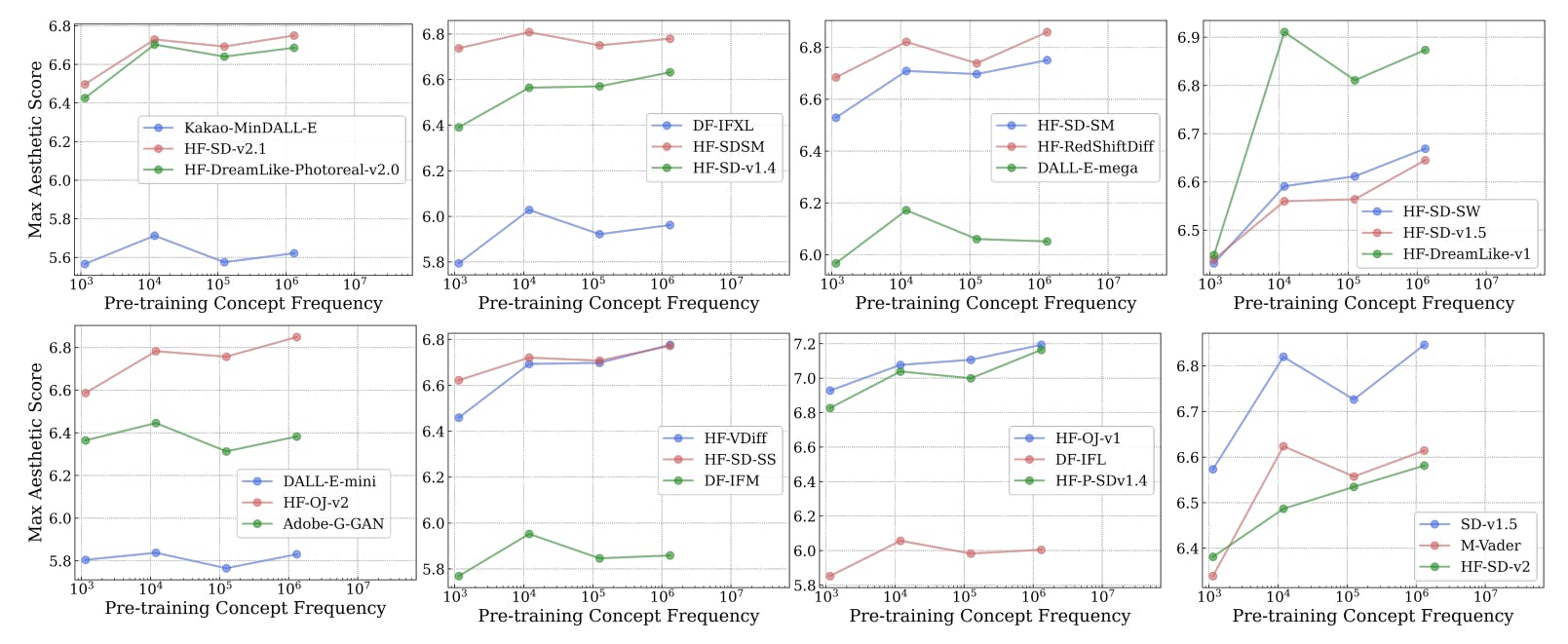
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
D Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
In all the main performance-frequency plots we have presented until now, the concept frequencies were estimated using the intersection of the image-frequencies and the text-frequencies. Here, we showcase results with using them independently in Figs. 17 and 18 respectively. We note that both independent searching methods showcase log-linear trends as before confirming our main result. We observe that the strong log-linear trend between concept frequency and zero-shot performance robustly holds across concepts derived from image and text domains independently as well




E Experimental Details
E.1 Setup of Mayilvahanan et al. [79]
LAION-200M is a dataset obtained by deduplicating LAION-400M by pruning exact duplicates, near duplicates, and semantically similar samples within LAION-400M [10]. The control pretraining set is created by pruning 50 million highly similar samples from LAION in the order of decreasing perceptual similarity to datapoints in ImageNet-val set. We use the 150M pretraining set for obtaining the concept distribution. We evaluate the performance of a ViT-B/32 CLIP model trained on this dataset on our downstream tasks, and present our analysis on those tasks.
E.2 Let It Wag!: Test Set Curation
To ensure our datasets are thoroughly cleaned and diverse, we follow a meticulous process:
-
Diverse Sourcing: We gather images from three different online sources—Flickr, DuckDuckGo, and Bing Search—to maximize the variety of our dataset, while retaining very easy-to-classify images[2].
-
Temporal Filtering: We applied a filter to only retrieve images after January 2023 to minimize overlap with images used in the pre-training of Vision-Language Models (VLMs). Note this helps mitigate but does not ensure the overlap problem is resolved.
-
Outlier Removal: We employ a pre-trained InceptionNet [111] to remove outliers from the entire image pool. We do this by taking all pairwise cosine-similarities between all images in the pool, and removing the images that are in the bottom 5% of the similarity values[3].
-
Initial De-duplication with an InceptionNet: We employ a pre-trained InceptionNet [111] model to identify and remove duplicates. This step involves setting high thresholds for soft de-duplication (0.9 for common classes and 0.95 for fine-grained classes) to ensure only minor, precise exclusions. A threshold of 0.9/0.95 means that we consider images to be duplicates if the cosine similarity of that image’s embedding (from InceptionNet) with any other image’s embedding in the image pool is larger than 0.9/0.95.
-
Manual Verification: Following the automated cleaning, we manually inspect and verify the accuracy of the remaining images for each class to ensure they meet quality standards.
-
Second-level De-duplication with Perceptual Hashing: Post-verification, we use perceptual hashing [37] with a threshold of 10 bits to identify and remove duplicate images within each class, ensuring uniqueness across our dataset[4].
-
Class Balancing: Finally, we balance the dataset to ensure an equal representation of classes. This process was followed for increased quality and reliability of our dataset for image recognition tasks.
Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.







{kind=link}