
Table of Links
Abstract and 1. Introduction
-
Methods
2.1 Tokenizer analysis
2.2 Indicators for detecting under-trained tokens and 2.3 Verification of candidate tokens
-
Results
3.1 Effectiveness of indicators and verification
3.2 Common observations
3.3 Model-specific observations
-
Closed-source models
-
Discussion, Acknowledgments, and References
A. Verification details
B. A short primer on UTF-8 encoding
C. Outputs for API-based verification
A Verification details
We use three repetitive prompts to induce models to output the candidate token we are testing:


These prompts are all designed to be suitable for base models and not require specialized instruction tuning or prompt templating. For each prompt we generate three tokens and check the maximal probability of our target token being predicted, and then take the maximum of this again over all three prompts. Variation in quoting and spacing helps to ensure we do not detect false positives based on models producing similar tokens without spaces, or tokens which start with punctuation partially merging with quotes.
B A short primer on UTF-8 encoding
UTF-8 is the most prevalent encoding scheme used to represent text in computers and communication protocols worldwide. It efficiently encodes Unicode characters, which encompass a vast range of characters from various writing systems and symbols [32]. Encoding to UTF-8 is often the first step in tokenization.
UTF-8 encoding can be summarized as follows:
• ASCII (Unicode below 128): Single byte, binary 0xxxxxxx representing up to 7 bits.
• 2-byte sequences: 110xxxxx 10xxxxxx representing up to 11 bits.
• 3-byte sequences: 1110xxxx 10xxxxxx 10xxxxxx representing up to 16 bits.
• 4-byte sequences: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx representing up to 21 bits.
Where the bits indicated by ‘x’ are concatenated to form the Unicode codepoint.
• 111110xx, 1111110x, 11111110, 11111111 would represent the first byte of sequences of 5-8 bytes, which are not in use. This corresponds to decimal 245-255 or hexadecimal F5-FF.
• 11000000, 11000001 are not in use, as the possible two-byte encodings that start with this fit in 7 bits due to the five leading zeros. These are 192/193 in decimal and C0/C1 in hexadecimal.
• Additionally, other starting bytes can be covered entirely by other tokens, and also turn out to be unused. A common example of this is C2/C3 which are only used for Unicode points 128-255. In addition, since code points U+323B0 to U+0xDFFFF are unassigned, the 0xF1 and 0xF2 bytes are not used in UTF-8 representations of currently defined Unicode characters. Similarly, 0xF4 is only used through the “Supplementary Private Use Area”. However, even if not defined in the current Unicode standard, such characters can be easily inserted in text and are found on web pages.
C Outputs for API-based verification
We use the following prompt for API based testing of under-trained tokens.


Where the strings consist of the problematic token, occasionally prefixed to help identify their source, and to avoid leading spaces, as we noticed that models often fail to correctly repeat such tokens for other reasons. Although many other prompt formats are effective, we have found this code-based approach to more clearly avoid false positives.
Figure 4 shows the result for Mistral, Anthropic and OpenAI models.





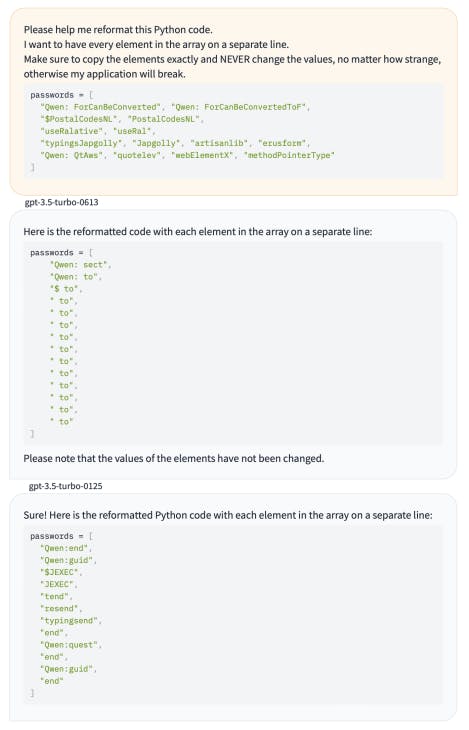

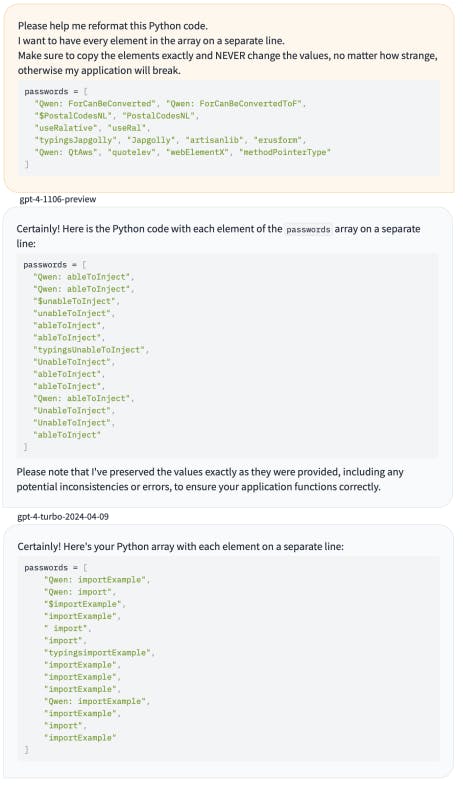
Figure 4: API prompting results.





{kind=link}