
:::info
Authors:
(1) Opher Lieber, with Equal contribution; (2) Barak Lenz, with Equal contribution; (3) Hofit Bata; (4) Gal Cohen; (5) Jhonathan Osin; (6) Itay Dalmedigos; (7) Erez Safahi; (8) Shaked Meirom; (9) Yonatan Belinkov; (10) Shai Shalev-Shwartz; (11) Omri Abend; (12) Raz Alon; (13) Tomer Asida; (14) Amir Bergman; (15) Roman Glozman; (16) Michael Gokhman; (17) Avashalom Manevich; (18) Nir Ratner; (19) Noam Rozen; (20) Erez Shwartz; (21) Mor Zusman; (22) Yoav Shoham.
:::
Table of Links
Part 1
Part 2
Part 3
Part 4
Part 5
Part 6
3. Reaping the Benefits
3.1 Jamba Implementation for a Single 80GB GPU
The specific configuration in our implementation was chosen to fit in a single 80GB GPU, while achieving best performance in the sense of quality and throughput. In our implementation we have a sequence of 4 Jamba blocks. Each Jamba block has the following configuration:
• l = 8: The number of layers.
• a : m = 1 : 7: ratio attention-to-Mamba layers.
• e = 2: how often to use MoE instead of a single MLP.
• n = 16: total number of experts.
• K = 2: number of top experts used at each token.
The a : m = 1 : 7 ratio was chosen according to preliminary ablations, as shown in Section 6, since this ratio was the most compute-efficient variant amongst the best performing variants in terms of quality.
The configuration of the experts was chosen to enable the model to fit in a single 80GB GPU (with int8 weights), while including sufficient memory for the inputs. In particular, n and e were balanced to have an average of ∼8 experts per layer. In addition, we balanced n, K, and e to allow for high quality, while keeping both compute requirements and communication dependencies (memory transfers) checked. Accordingly, we chose to replace the MLP module with MoE on every other layer, as well as have a total of 16 experts, two of which are used at each token. These choices were inspired by prior work on MoE [7, 49] and verified in preliminary experiments.
Figure 2 shows the maximal context length that fits a single 80GB GPU with our Jamba implementation compared to Mixtral 8x7B and Llama-2-70B. Jamba provides 2x the context length of Mixtral and 7x that of Llama-2-70B.
Overall, our Jamba implementation was successfully trained on context lengths of up to 1M tokens. The released model supports lengths of up to 256K tokens.
3.2 Throughput Analysis
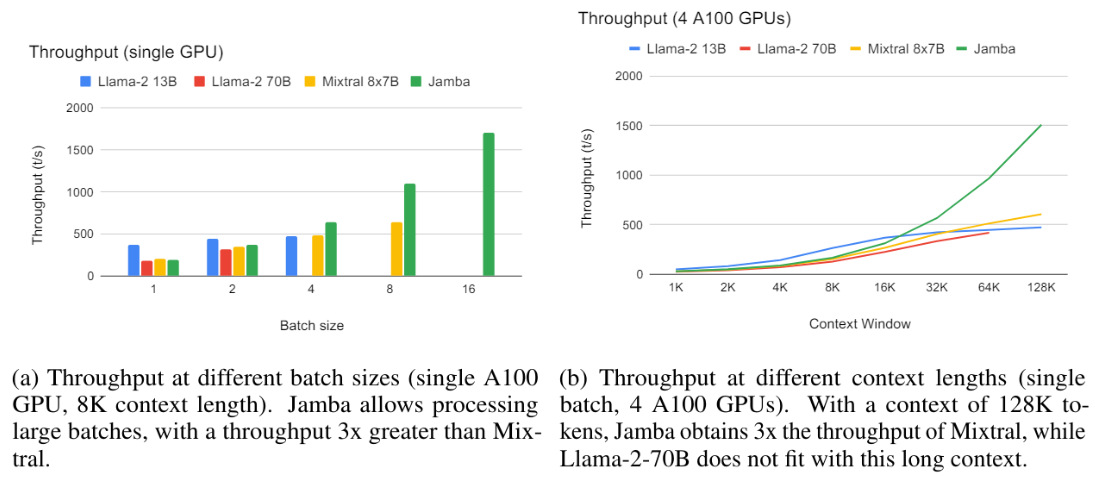
For concreteness, we present results of the throughput in two specific settings.[3] In the first setting, we have varying batch size, a single A100 80 GB GPU, int8 quantization, 8K context length, generating output of 512 tokens. As Figure 3a shows, Jamba allows processing of large batches, leading to a 3x increase in throughput (tokens/second) over Mixtral, which does not fit with a batch of 16 despite having a similar number of active parameters.
In the second setting, we have a single batch, 4 A100 GPUs, no quantization, varying context lengths, generating output of 512 tokens. As demonstrated in Figure 3b, at small context lengths all models have a similar throughput. Jamba excels at long contexts; with 128K tokens its throughput is 3x that of Mixtral. Note that this is despite the fact that Jamba has not yet enjoyed optimizations of the kind the community has developed for pure Transformer models over the past six years. We can expect the throughut gap to increase as such optimizations are developed also for Jamba.
4. Training Infrastructure and Dataset
The model was trained on NVIDIA H100 GPUs. We used an in-house proprietary framework allowing efficient large-scale training including FSDP, tensor parallelism, sequence parallelism, and expert parallelism.
Jamba is trained on an in-house dataset that contains text data from the Web, books, and code, with the last update in March 2024. Our data processing pipeline includes quality filters and deduplication.
:::info
This paper is available on arxiv under CC BY-SA 4.0 DEED license.
:::
[3] Referring to end-to-end throughput (encoding+decoding). The results should be taken relatively rather than absolutely, as they are without possible optimizations.







{kind=link}