
Table of links
Abstract
1 Introduction
2 Related Work
2.1 Fairness and Bias in Recommendations
2.2 Quantifying Gender Associations in Natural Language Processing Representations
3 Problem Statement
4 Methodology
4.1 Scope
4.3 Flag
5 Case Study
5.1 Scope
5.2 Implementation
5.3 Flag
6 Results
6.1 Latent Space Visualizations
6.2 Bias Directions
6.3 Bias Amplification Metrics
6.4 Classification Scenarios
7 Discussion
8 Limitations & Future Work
9 Conclusion and References
6 Results
This section presents results from implementing our framework and flagging the existence or change in bias when conducting a simple mitigation method. The goal of this evaluation was to test whether our methodologies were successful in capturing and understanding user gender attribute association bias from our case study’s model.
6.1 Latent Space Visualizations
Figures 1 & 2 show latent space visualizations of user and podcast embeddings with and without user gender as a model feature respectively. In both cases, our first principal component had a high cosine similarity to the centroid difference (0.89 and 0.91, with gender and without gender as a feature, respectively). We observed both user clusters and podcast clusters emerge along the first principal component for the embeddings trained with and without user gender as a feature. When we projected the entity embeddings trained without gender, we observed a similar pattern of clustering as in the case of podcasts trained with gender. Both the user and podcast embeddings trained without gender have flipped directionality for the gender direction due to being trained separately from the with-gender embeddings. However, we observe the same relationship of gendered clustering for users along the first principal component in both contexts. Our projections demonstrate that user and podcast embeddings trained without a gender vector still have latent gendered meanings encoded. In the case of podcasts, we observe a weaker separation along this axis, although it is still possible that feature clusters could be derived.
6.2 Bias Directions
When testing the resulting bias directions for significance, we found that all possible direction methods, except for the PCA bias direction, resulted in significant results for our three recommended statistical tests. With the Bonferroni correction, statistical tests were considered significant if p < 0.0033. Beyond the PCA direction, bias directions were significant regardless of if user gender was or was not an explicit attribute used during model training. However, numeric test statistics were greater for our statistical tests when user gender was present during training.
We found that the PCA direction created from random pairings between male and female user vectors failed the test comparing the cosine similarities between the entity and bias direction versus that of random vectors and the bias direction. Since the other two tests were significant, this pointed to the bias direction capturing a significant difference between the attribute entity groups and a significant direction in the space but not a significant relationship between the entity attribute and the bias direction. This result means that the bias direction should not be used for further analysis of gender attribute association bias in the space, since it could easily capture other attribute behavior within the latent space and thus result in inaccurate observations of attribute association bias. It is essential to statistically test one’s bias directions since acting on inaccurate results could inadvertently introduce more harm instead of lowering harm in subsequent mitigation.
In addition to our proposed flagging methodology, we evaluated the SVC direction based on its model’s test accuracy. We split our data into training and test data on an 80-20 split; the results are in Table 1. Our first iteration SVC model trained on a random subset of users achieved 99.3% test accuracy in our with-gender user vectors and 82.2% test accuracy in our non-gender user vectors. Our mixed-method Centroid-SVC direction (CSVC-1) trained on the 200 “most biased” users achieved 96.0% with-gender test accuracy and 73.6% non-gender test accuracy. The other mixed-method CSVC direction (CSVC-2) trained on the 2500 “most biased” users according to the centroid difference gender direction (CD) achieved 96.4% with-gender test accuracy and 81.5% non-gender test accuracy. In order to maintain consistency between test accuracies, we evaluated using the same test set across all trained SVC models.
The significant decrease in test accuracy for CSVC-2 could be attributed to multiple factors, such as a reduction in training data, overfitting to training data, or a reduction in gender explainability for all users via the CD. The difference between with-gender and non-gender test accuracy for CSVC-1 is particularly interesting since we intentionally trained the with-gender and non-gender models on the same users. The reduced ability of these 200 users to accurately predict gender when embeddings are not explicitly trained with user gender
as a feature signals that the explicit use of this feature does strengthen the significance of gender in user embeddings within the trained latent space. The perfect training accuracy achieved by training our SVC models on the “most” biased users, as found by calculating the cosine similarity with the centroid vector, one can see that the gender centroids do accurately capture gender associations. Additionally, the difference in training and test accuracy for these two models signals that the more stereotypically “gender biased” the user is, the more easily they can be linearly separated by an SVC model. The decrease in training and test accuracy when removing gender as a model attribute shows a reduction, but not complete erasure, in gender attribute association in the latent space.
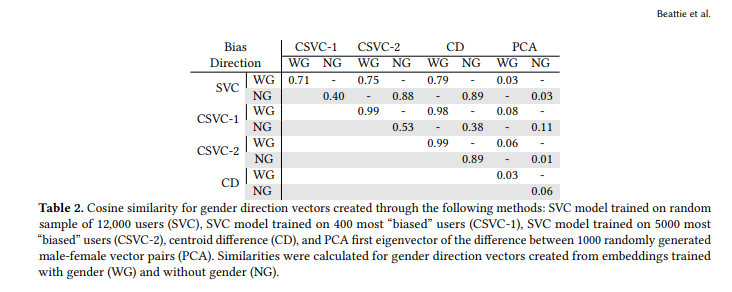
atent space. Finally, the reduced accuracy of the CSVC-1 model with no gender may signal that the resulting bias direction may not be best for calculating bias metrics or analyzing attribute association bias. It would be more prudent to leverage bias directions with high levels of significance via testing and high levels of accuracy (when using SVC to create the bias direction). We calculated the cosine similarity between each possible direction vector to compare the resulting bias directions. The cosine similarities between the different gender directions reflected in with-gender and non-gender embeddings can be found in Table 2. Our comparisons signaled high levels of similarity between all calculated gender directions except for the PCA bias direction.
As previously noted, this direction was created by randomly pairing female and male users, finding the difference in their vector directions, and then finding the first eigenvector of their vector differences. Given that this direction is the only one with a low level of cosine similarity, carefully choosing pairs when leveraging this method is essential. We found that randomly pairing users to create a difference vector based on their attribute resulted in our bias direction not accurately capturing potential attribute association bias. The PCA bias direction method should solely be used if the practitioner is confident in their entity pairing methodology to reflect the targeted attribute. Table 2 also shows that the cosine similarity between bias directions from the different methods varied significantly. Even though each direction was significant, this difference demonstrates that each relationship captured is slightly different according to the method used. Additionally, we noticed that these fluctuations decreased when user gender was removed as a model feature. This decrease was expected since user gender was no longer used as a model feature. Additionally, it showcased that the bias directions were capable of relaying implicit, or potentially systematic, bias in the latent space. Given the fluctuations found, we believe it would be responsible for practitioners to explore and test multiple bias directions during analysis to enable more nuanced viewpoints of attribute association bias.
6.3 Bias Amplification Metrics
EAA, GEAA, and DEAA. Our results using this set of metrics signaled that our test entity sets of true crime and sports podcast vectors showed significant association attribute bias with their respective user gender. We found that podcast embeddings trained with and without gender resulted in a significant DEAA score of 612.27 and 480.59, respectively. The calibration effect for with and without gender DEAA was 1.81 and 1.78. The normalization of the calibration effect showcases that the attribute association bias remains highly significant when accounting for the EAA distributions. EAA metrics successfully flagged a significant change in attribute association bias levels when removing gender. However, significant levels of bias remained. When accounting for the separate GEAA for sports and true crime podcasts, we found that the final DEAA score could be contributed primarily to sports podcasts versus true crime podcasts. When trained with gender, sports podcasts GEAA was -521.34, which was reduced to -406.59 when trained without gender. This decrease of 22% was greater than the 18.6% decrease for the true crime podcast test metric. True crime GEAA was originally 90.93 when trained with gender and reduced to 73.98 after the mitigation. This discrepancy reflects that sports podcasts have significantly higher attribute association bias and are heavily associated with the male attributedefining entity set of vectors. This difference also highlights that this simple mitigation method does not equally address gender attribute association bias across groups. Observing the different levels of EAA metrics allow a practitioner to pinpoint which group is more or less affected by the mitigation.
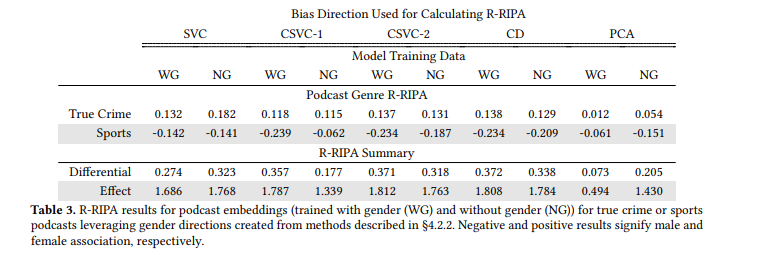
R-RIPA. We find that R-RIPA also successfully relays attribute association bias; results are in Table 3. When comparing the R-RIPA across bias directions, a couple of results
stand out. First, after removing gender, the SVC R-RIPA for true crime podcasts increased, signifying an increase in attribute association bias for true crime podcasts with female users. However, this result is not present for R-RIPA created with the bias directions CSVC-1, CSVC-2, and CD. This difference signals that user gender attribute association bias may have a more nuanced relationship with individual female users that is not fully captured by centroid-based directions. Additionally, we find that true crime podcasts do not experience as significant of a decrease as sports podcasts for R-RIPA calculated with the bias directions CSVC-1, CSVC-2, and CD. This result could signify that removing user gender reduced attribute association bias more heavily for sports podcasts with high levels of attribute association bias as captured by a centroid-related direction.
Metric Comparison. Unlike the EAA metrics, R-RIPA is at risk of more fluctuation in results depending on the bias direction selected for calculation. As a result, we recommend that practitioners compute R-RIPA only with bias directions that more accurately represent the attribute behavior in the latent space. For example, when leveraging bias directions other than that of SVC (trained on a randomly sampled user set), there is a significant increase in attribute association bias signaled by R-RIPA. This peculiarity could be seen as those bias directions over-reporting bias or SVC under-reporting bias. Additionally, R-RIPA computed with the SVC bias direction is at risk of becoming less accurate as the trained SVC becomes less accurate. It is essential to account for this possibility by implementing permutation testing to determine the significance of R-RIPA results if there is less confidence in the bias direction. In such cases, it may be more prudent to apply the EAA bias metrics instead.
6.4 Classification Scenarios
The classification scenarios we designed allowed us to observe if podcast embeddings used as downstream features resulted in either accurate predictions of user gender engagement or stereotyped predictions of podcasts labeled for our entity test sets. For each scenario, we evaluated results for podcasts trained with and without user gender as a feature to understand implicit user gender bias in the latent space and how explicit use of the feature amplifies said bias. We used the same SVC classification models trained on user vectors to create gender directions for our analysis: SVC, CSVC-1, and CSVC-2.
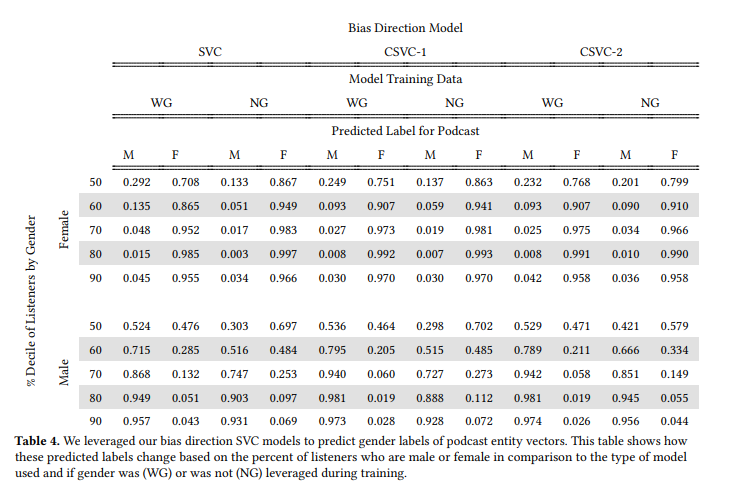
6.4.1 Gendered Podcast Listening. We analyzed whether these predictions aligned with actual podcast listenership gender percentages. We did this by observing how our SVC models labeled podcasts as “male” and “female”. We compared these predictions against the podcasts’ male and female listenership percentage. In 4, we see the pattern that as podcasts have increasing percentages of male or female listenership, the podcasts are more likely to be classified as “male” or “female” podcasts. For example, with the SVC model trained on user embeddings with user gender, we see that when podcasts are in the 50% decile, they are classified as “female” 70.8% of the time, but when female listenership grows to over 70%, podcasts are labeled as “female” over 95% of the time. This classification scenario allows us to see that as engagement becomes more gendered, the podcast entity embeddings become more associated with a specific gender as well.
Interestingly, predictions correlating with female podcast listening became more accurate when the model was not trained with gender. However, this result did not hold for male podcast listening. When the model was trained without gender, the predictions became significantly less accurate when labeling a podcast with higher male engagement as male. Given this change in result, we hypothesized that the semantic embedding of user gender might not precisely represent the female and male binary relationship for podcast vectors but that of male and not male. Understanding how
this relationship is embedded into the space would require more in-depth testing with non-binary data, which is out of the scope of this paper but could be an interesting development to explore in future research. We found that this classification scenario showcased how podcast entity vectors can capture user gender attribute association bias based on the increase in accuracy in predictions as the percentage of listener gender rose. Additionally, the results showed that podcast embeddings associated with male listening experienced a sharper increase in accuracy as the male listener percentage increased. This finding is helpful during evaluation because it flags a difference in behavior within the latent space for podcast embeddings more related to stereotypical male listening.
6.4.2 User Gender from Podcast Listening History.
We designed this scenario to capture the ability of item embeddings to relay sensitive information about users in downstream models. If item embeddings can be used to predict the user-sensitive attribute, as well as the user embedding itself, it can be assumed that the sensitive attribute is entangled within the item embedding. We found the overall change in test accuracy to be small when leveraging podcast vectors trained with and without access to gender as a feature. Classification test accuracy for with-gender podcast vectors was 0.832, while non-gender podcast vectors achieved a test accuracy of 0.829. When breaking down results by gender, we found the change in test accuracy to be more pronounced. When gender was included as a feature, 17.9% of female users were classified as male. This percentage reduced to 11.3% when vectors were trained without access to gender. Alternatively, misclassification for male users increased to 23.7% when the model was trained without gender versus 15.7% when trained with user gender as a feature. To better understand the vectors resulting in misclassification, we evaluated the cosine similarity of these vectors against the female, male, female podcast-listening, and male podcast-listening centroids. We found that misclassified podcast vectors showed higher cosine similarity with the opposite gender and gendered listening centroids.
6.4.3 Gender Bias by Genre. Finally, we examine if gender stereotyped genres are more or less likely to be associated with misclassifications of gender if gender is used as a feature or not. This association is evaluated by observing the predicted labels of the sports or true crime podcasts. Results are in Table 5. We found that results for true crime and sports podcasts from SVC and CSVC-2 remained relatively stable when gender was and was not used as a feature during training. When testing for significance, we found that both models did not experience a significant change, with p-values of 0.007 and 0.264, respectively. However, we found this untrue when testing CSVC-1, which was trained on the 200 “most gender-biased” users. Predictions from CSVC-1 showed a significant change in the precision of predicting true crime podcasts as female, with the metric reducing from 0.80 to 0.49. This drop means more sports podcasts were classified as “female” instead of “male.” One can speculate that this reflects attribute association bias for sports podcasts concerning the 200 “most gender-biased” users to have been significantly reduced when removing user gender from the training process. This behavior is also reflected in the significant drop in recall for sports podcasts regarding the CSVC-1 model. In contrast, true crime podcasts experience a slight uptick in the recall, with an increase of 0.81 to 0.84 for CSVC-1 and SVC and CSVC-2 results. These results show an imbalanced effect of the chosen mitigation method to remove user gender from training. This assumption is further supported when testing for significance
between the genre groups of model performance. When gender was used during training, model performance for predicting the stereotyped gender for a podcast was significantly different for all three classification models. If gender was removed during training, we found that the difference in performance was no longer significant for the SVC model. This difference was not due to the lessening of bias when predicting the gender of a podcast but instead from the classification model predicting more true crime podcasts as “female.”
:::info
Authors:
- Lex Beattie
- Isabel Corpus
- Lucy H. Lin
- Praveen Ravichandran
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::






{kind=link}