
Table of Links
Abstract and 1. Introduction
-
Related work
-
Method
3.1. Uniform quantizer
3.2. IGQ-ViT
3.3. Group size allocation
-
Experiments
4.1. Implementation details and 4.2. Results
4.3. Discussion
-
Conclusion, Acknowledgements, and References
Supplementary Material
A. More implementation details
B. Compatibility with existing hardwares
C. Latency on practical devices
D. Application to DETR
3. Method
In this section, we provide a brief description of uniform quantizer (Sec. 3.1). We then present our approach in detail, including IGQ-ViT (Sec. 3.2) and a group size allocation technique (Sec. 3.3).
3.1. Uniform quantizer
Given a floating-point value x and the quantization bitwidth b, uniform quantizers discretize the inputs into a finite set of values with equally spaced intervals. To this end, it normalizes the floating-point value x using a scale parameter s, calibrate the normalized value with a zero-point z, and clip the output as follows:
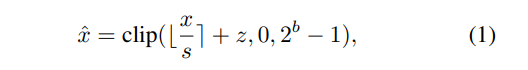
where the scale parameter s and zero-point z are defined as:
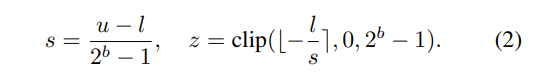
We denote by u and l upper and lower bounds of the quantizer, respectively. ⌊.⌉ is a rounding function, and clip(., m, n) restricts an input to the range with lower and upper bounds of m and n, respectively. The quantized output is then obtained as follows:
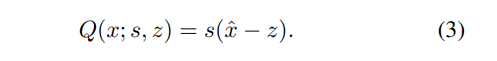
3.2. IGQ-ViT
Following the work of [26], we quantize all network weights except for the positional embedding. We also quantize input activations of FC layers in the multi-layer perceptron (MLP) block, and the activations for the multi-head self-attention (MSA) block, including queries, keys, values, and softmax attentions. We exploit uniform quantizers for all weights and activations in ViTs.
3.2.1 IGQ for linear operations
In the following, we first provide empirical observations on input activations of FC layers, and explain the details of our IGQ framework for linear operations.
Distributions of activations across channels. Most quantization frameworks [2, 19, 26, 27] exploit layer-wise quantizers for activations, applying a single quantization parameter for all channels for efficient inference. However, we have observed that the input activations of FC layers have significant scale variations across channels (Fig. 2(a)). Similar findings can be found in [21, 23]. This suggests that layer-wise quantizers degrade the quantization performance significantly, as they cannot handle scale variations across different channels. Although adopting separate quantizers for individual channels could be an effective strategy for overcoming the scale variation problem, this requires a summation of a floating-point output for every channel, which is computationally expensive. We have also found that the ranges of these activations for each channel vary drastically among different input instances (Fig. 2(b, c)), since ViTs do not have preceding BatchNorm [15] layers in contrast to state-of-theart CNNs (e.g., ResNet [13], MobileNetV2 [31]). Conventional approaches (e.g., [4, 7, 32, 36]) exploit a fixed quantization interval (i.e., from lower to upper bounds of the quantizer) for every input instance, thus cannot adapt to such diverse distributions across different samples.


![Table 1. Comparison of BOPs for a 4-bit DeiT-B [34] model using various quantization strategies. We denote by ‘Model’ the required BOP for layer-wise quantization. In contrast to layer-wise quantization, IGQ-ViT involves additional computations, including (1) computing the min/max values of each channel, (2) assigning channels to quantizers with the minimum distance, and (3) summing the outputs of each group in a floating-point format. The corresponding BOPs for these steps are denoted by ‘Minmax’, ‘Assign’, and ‘FP sum’, respectively.](https://cdn.hackernoon.com/images/null-m4232wa.png)

3.2.2 IGQ for softmax attentions
Here, we present our observation for the distribution of softmax attentions, and present the details of IGQ for softmax attentions.
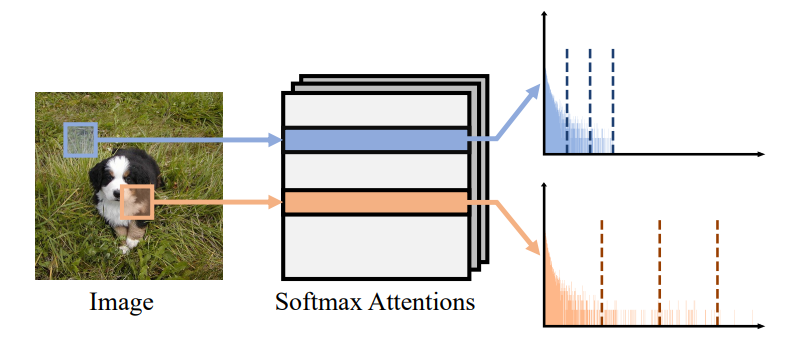
Distributions of softmax attentions. ViTs capture correlations between tokens through softmax attentions. The distribution of attention values varies drastically across different tokens (Fig. 3). Therefore, using a single quantization
![Figure 4. Comparisons for dynamic ranges of activation values across channels, chosen from different layers of ViT-S [10]. σrange is the standard deviation of the dynamic ranges of channels for each layer. We can see that the degree of scale variations across channels varies according to the layer, suggesting that the number of groups for each layer would be adjusted.](https://cdn.hackernoon.com/images/null-t6532ds.png)
parameter to quantize softmax attentions degrades quantization performance severely. Separate quantizers might be exploited for individual tokens to handle the attention values, but this requires a large number of quantizers, and needs to adjust the quantization parameters for each instance.


3.3. Group size allocation
We observe that activations and softmax attentions in different layers show different amount of scale variations across channels and tokens, respectively, indicating that using the same number of groups for different layers might be suboptimal (Fig. 4). To address this, we search for the optimal group size for each layer that minimizes the discrepancy between the predictions from quantized and fullprecision models, under a BOP constraint. However, the search space for finding the optimal group sizes is exponential w.r.t. the number of layers L, which is intractable for a large model. We propose a group size allocation technique that efficiently optimizes the group size for each layer within such a large search space. Concretely, we define a perturbation metric for a particular layer ψ(.) as the Kullback-Leibler (KL) divergence between predictions of the model before and after quantization as follows:

![Table 2. Quantitative results of quantizing ViT architectures on ImageNet [8]. W/A represents the bit-width of weights (W) and activations (A), respectively. We report the top-1 validation accuracy (%) with different group sizes for comparison. The numbers of other quantization methods are taken from [9, 21]. †: Results without using a group size allocation (i.e., a fixed group size for all layers).](https://cdn.hackernoon.com/images/null-2q132ax.png)
:::info
Authors:
(1) Jaehyeon Moon, Yonsei University and Articron;
(2) Dohyung Kim, Yonsei University;
(3) Junyong Cheon, Yonsei University;
(4) Bumsub Ham, a Corresponding Author from Yonsei University.
:::
:::info
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license
:::





{kind=link}