Authors:
(1) Mahdi Goldani;
(2) Soraya Asadi Tirvan.
Table of Links
Abstract and Introduction
Methodology
Dataset
Similarity methods
Feature selection methods
Measure the performance of methods
Result
Discussion
Conclusion and References
Abstract
In predictive modeling, overfitting poses a significant risk, particularly when the feature count surpasses the number of observations, a common scenario in high-dimensional data sets. To mitigate this risk, feature selection is employed to enhance model generalizability by reducing the dimensionality of the data. This study focuses on evaluating the stability of feature selection techniques with respect to varying data volumes, particularly employing time series similarity methods. Utilizing a comprehensive dataset that includes the closing, opening, high, and low prices of stocks from 100 high-income companies listed in the Fortune Global 500, this research compares several feature selection methods including variance thresholds, edit distance, and Hausdorff distance metrics. The aim is to identify methods that show minimal sensitivity to the quantity of data, ensuring robustness and reliability in predictions, which is crucial for financial forecasting. Results indicate that among the tested feature selection strategies, the variance method, edit distance, and Hausdorff methods exhibit the least sensitivity to changes in data volume. These methods therefore provide a dependable approach to reducing feature space without significantly compromising the predictive accuracy. This study not only highlights the effectiveness of time series similarity methods in feature selection but also underlines their potential in applications involving fluctuating datasets, such as financial markets or dynamic economic conditions. The findings advocate for their use as principal methods for robust feature selection in predictive analytics frameworks.
Introduce
In machine learning models, having a complete and comprehensive dataset can significantly enhance model accuracy. However, there are instances where the inclusion of irrelevant features may actually hinder rather than help the model’s performance. In fact, the feature space with larger dimensions creates a larger number of parameters that need to be estimated. As a result, by increasing the number of parameters, the probability of overfitting in the demand model is strengthened. Therefore, the best performance generalization is achieved when a subset of the available features is used. Dimensionality reduction is the way to solve this challenge. The literature on dimensionality reduction refers to transforming data from a high-dimensional space into a low dimensional space. One of the most well-known techniques of dimensionality reduction is Feature selection [1]. Feature selection selects a subset of relevant features for use in model construction. The filters, embedded, and wrapper methods are the three main categories of Feature selection methods. Filter methods are characterized by their independence from specific machine learning algorithms. They prioritize data relationships, making them computationally efficient and straightforward to implement. In contrast, wrappers and embedded methods rely on learning algorithms. While filters are computationally efficient and easy to implement, wrappers often achieve better performance by considering feature interactions, albeit with increased computational complexity. Embedded methods strike a balance between filters and wrappers, integrating feature selection into the training process. This integration reduces computational costs compared to wrappers, as it eliminates the need for separate iterative evaluation of feature subsets [2]. Along with feature selection methods, time series similarity methods used for clustering in machine learning can be a suitable option for selecting a suitable subset of variables. similarity methods can serve as effective feature selection techniques by identifying redundant or irrelevant features, grouping similar features together, and quantifying the relationships between features and the target variable. By leveraging similarity measures in feature selection, one can extract the most informative features from the dataset while reducing dimensionality and improving model performance. The review of articles in this field shows that similarity methods are used in combination with feature selection methods.
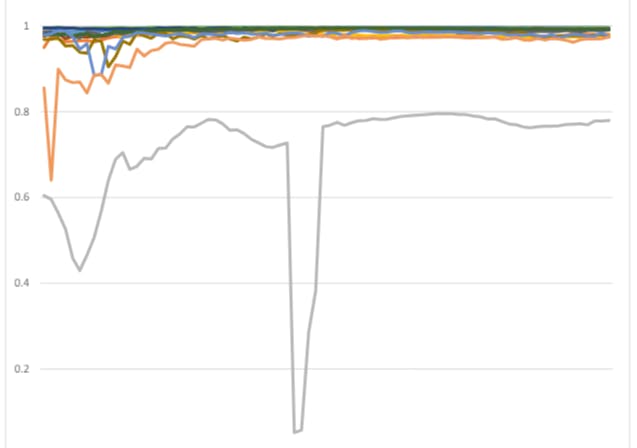
In the literature, the primary aim of feature selection is to eliminate irrelevant variables, particularly when the number of features exceeds the number of observations. This practice helps mitigate overfitting, ensuring that the model generalizes well to unseen data. Therefore, feature selection is a method for dealing with a small number of observations. But does the performance of feature selection methods change when the number of observations is very small? In fact, this article seeks to find the answer to this question; When we are faced with a small number of observations, the results of which of the feature selection methods can be more reliable? This issue is important because most of the existing datasets that provide annual data face the problem of a small number of observations. Therefore, finding a way to reduce the dimension of a data set when the number of observations is low can help to increase the accuracy of the models. The aim of this research is to find the most optimal method to reduce the dimension of data that has the least impact on the performance of these models.
Feature selection is a widely used technique in various data mining and machine learning applications. In the literature on feature selection, there is no study that uses similarity methods directly as feature selection methods but there are some researches that explore this concept or incorporate similarity measures into feature selection processes. For example, Zhu et al [3] In the proposed Feature Selection-based Feature Clustering (FSFC) algorithm, similarity-based feature clustering utilized a means of unsupervised feature selection. Mitra [4] proposes an unsupervised feature selection algorithm designed for large datasets with high dimensionality. The algorithm is focused on measuring the similarity between features to identify and remove redundancy, resulting in a more efficient and effective feature selection process. In the domain of software defect prediction, Yu et al. [5] emphasize the central role of similarity in gauging the likeness or proximity among distinct software modules (referred to as samples) based on their respective features. Shi et al. [6] proposed a novel approach called Adaptive-Similarity based Multi-modality Feature Selection (ASMFS) for multimodal classification in Alzheimer’s disease (AD) and its prodromal stage, mild cognitive impairment (MCI). They addressed the limitations of traditional methods, which often rely on pre-defined similarity matrices to depict data structure, making it challenging to accurately capture the intrinsic relationships across different modalities in high-dimensional space. In the FU’s [7] article Following the evaluation of feature relevance, redundant features are identified and removed using feature similarity. Features that exhibit high similarity to one another are considered redundant and are consequently eliminated from the dataset. Feature similarity measures are utilized to quantify the similarity between pairs of features. These measures help identify redundant features by assessing their degree of resemblance or closeness.
In terms of data size, there’s been a bunch of studies that have addressed this issue. Vabalas [8] highlights the crucial role of sample size in machine learning studies, particularly in predicting autism spectrum disorder from high- dimensional datasets. It discusses how small sample sizes can lead to biased performance estimates and investigates whether this bias is due to validation methods not adequately controlling overfitting. Simulations show that certain validation methods produce biased estimates, while others remain robust regardless of sample size. Perry et al. [9] underscore the significance of sample size in machine learning for predicting geomorphic disturbances, showing that small samples can yield effective models, especially for identifying key predictors. It emphasizes the importance of thoughtful sampling strategies, suggesting that careful consideration can enhance predictive performance even with limited data. Cui and Goan [10] tested Six common ML regression algorithms on resting-state functional MRI (rsfMRI) data from the Human Connectome Project (HCP), using various sample sizes ranging from 20 to 700. Across algorithms and feature types, prediction accuracy and stability increase exponentially with larger sample sizes. Kuncheva et al. [11] conducted experiments on 20 real datasets. In an exaggerated scenario, where only a small portion of the data (10 instances per class) was used for feature selection while the rest was reserved for testing, the results underscore the caution needed when performing feature selection on wide datasets. The findings suggest that in such cases, it may be preferable to avoid feature selection altogether rather than risk providing misleading results to users. Kuncheva [12] challenges the traditional feature selection protocol for high-dimensional datasets with few instances, finding it leads to biased accuracy estimates. It proposes an alternative protocol integrating feature selection and classifier testing within a single cross-validation loop, which yields significantly closer agreement with true accuracy estimates. This highlights the importance of re-evaluating standard protocols for accurate performance evaluation in such datasets.
A review of studies clarifies two basic issues. One, among the mentioned studies, there is no study that directly uses similarity methods as a feature selection method. Therefore, as a new proposal, this study directly uses similarity methods as a feature selection method and compares their prediction performance with feature selection methods. Second, in this study, a real data set (Financial data of the 100 largest companies by revenue), to evaluate the sensitivity of each method to the sample size and compare it with another. The rest of the paper is organized as follows: methodology is discussed in Section 2, Section 3 presents the results of the study, and Section 4 reports a discussion of findings and conclusions.
This paper is available on arxiv under CC BY-SA 4.0 by Deed (Attribution-Sharealike 4.0 International) license.






{kind=link}