Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway and Corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Definitions
2.2 NLP Approaches
2.3 Privacy-Preserving Data Publishing
2.4 Differential Privacy
3 Datasets and 3.1 Text Anonymization Benchmark (TAB)
3.2 Wikipedia Biographies
4 Privacy-oriented Entity Recognizer
4.1 Wikidata Properties
4.2 Silver Corpus and Model Fine-tuning
4.3 Evaluation
4.4 Label Disagreement
4.5 MISC Semantic Type
5 Privacy Risk Indicators
5.1 LLM Probabilities
5.2 Span Classification
5.3 Perturbations
5.4 Sequence Labelling and 5.5 Web Search
6 Analysis of Privacy Risk Indicators and 6.1 Evaluation Metrics
6.2 Experimental Results and 6.3 Discussion
6.4 Combination of Risk Indicators
7 Conclusions and Future Work
Declarations
References
Appendices
A. Human properties from Wikidata
B. Training parameters of entity recognizer
C. Label Agreement
D. LLM probabilities: base models
E. Training size and performance
F. Perturbation thresholds
5 Privacy Risk Indicators
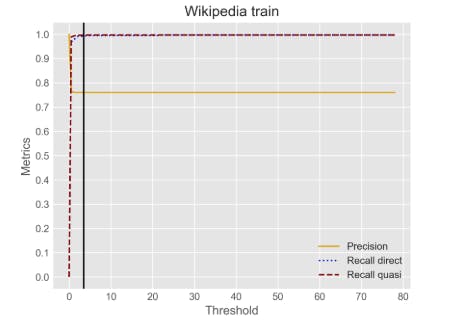
Many text sanitization approaches simply operate by masking all detected PII spans. This may, however, lead to overmasking, as the actual risk of re-identification may vary greatly from one span to another. In many documents, a substantial fraction of the detected text spans may be kept in clear text without notably increasing the reidentification risk. For instance, in the TAB corpus, only 4.4 % of the entities were marked by the annotators as direct identifiers, and 64.4 % as quasi-identifiers, thus leaving 31.2 % of the entities in clear text. To assess which text spans should be masked, we need to design privacy risk indicators able to determine which text spans (or combination of text spans) actually constitute a re-identification risk.
We present 5 possible approaches for inferring the re-identification risk associated with text spans in a document. Those 5 indicators are respectively based on:
-
LLM probabilities,
-
Span classification,
-
Perturbations,
-
Sequence labelling,
-
Web search.
The web search approach can be applied in a zero-short manner without any finetuning. The two methods respectively based on LLM probabilities and perturbations require a small number of labeled examples to adjust a classification threshold or fit a simple binary classification model. Finally, the span classification and sequence labelling approaches operate by fine-tuning an existing language model, and are thus the methods that are most dependent on getting a sufficient amount of labeled training data to reach peak performance. This training data will typically take the form of human decisions to mask or keep in clear text a given text span.
We present each method in turn and provide an evaluation and discussion of their relative benefits and limitations in Section 6.
5.1 LLM Probabilities
The probability of a span as predicted by a language model is inversely correlated with its informativeness: a text span that is harder to predict is more informative/surprising than one that the language model can easily infer from the context (Zarcone et al., 2016). The underlying intuition is that text spans that are highly informative/surprising are also associated with a high re-identification risk, as they often correspond to specific names, dates or codes that cannot be predicted from the context.
Concretely, we calculate the probability of each detected PII span given the entire context of the text by masking all the (sub)words of the span, and returning a list with all log-probabilities (one per token) referring to the span as calculated by a large, bidirectional language model, in our case BERT (large, cased) (Devlin et al., 2019). Those probabilities are then aggregated and employed as features for a binary classifier that outputs the probability of the text span being masked by a human annotator.
The list of log-probabilities for each span has a different length depending on the number of tokens comprised in the text span. We therefore aggregate this list by reducing it to 5 features, namely the minimum, maximum, median and mean log probability as well as the sum of log-probabilities in the list. In addition, we also include as feature an encoding of the PII type assigned to the span by the human annotators (see Table 1).
For the classifier itself, we conduct experiments using a simple logistic regression model as well as a more advanced classification framework based on AutoML. AutoML (He et al., 2021) provides a principled approach to hyper-parameter tuning and model selection, efficiently searching for the hyper-parameters and model combination that yield the best performance. We use the Autogluon toolkit (Erickson et al., 2020) in our experiments, and more specifically AutoGluon’s Tabular predictor (Erickson et al., 2020), which consists of an ordered sequence of base models. After each model is trained and hyper-parameter optimization is performed on each, a weighted ensemble model is trained using a stacking technique. A list of all base models of the Tabular predictor is shown in Table 11, in Appendix D. We use the training splits of the Wikipedia biographies and the TAB corpus to fit the classifier.







{kind=link}