:::info
Authors:
(1) Haolong Li, Tongji Universiy and work done during internship at ByteDance ([email protected]);
(2) Yu Ma, Seed Foundation, ByteDance ([email protected]);
(3) Yinqi Zhang, East China Normal University and work done during internship at ByteDance ([email protected]);
(4) Chen Ye (Corresponding Author), ESSC Lab, Tongji Universiy ([email protected]);
(5) Jie Chen, Seed Foundation, ByteDance and a Project Leader ([email protected]).
:::
Table of Links
Abstract and 1 Introduction
2 Problem Definition
2.1 Arithmetical Puzzle Problem
2.2 Data Synthesizing
2.3 Dataset
3 Model
4 Experiments
4.1 Evaluation
4.2 Results
4.3 Case Studies
5 Conclusion and Acknowledgements
6 Limitations
7 Ethics Statement and References
A Appendix
A.1 Hyperparameter Settings
A.2 Evaluation of the Base Model
A.3 Case Study
A.4 Visualization of the Proposed Puzzle
2.1 Arithmetical Puzzle Problem
Arithmetical puzzle problem denotes a mathematical puzzle involving arithmetic operations and requires logical reasoning and numerical manipulation to derive a solution. The 24 Puzzle and Arithmetic Grid Puzzle are well-known examples of arithmetical puzzle problems.
In this paper, we propose a challenging arithmetical puzzle. Its objective is intricate yet precise: to deftly manipulate a set of given integers through a calculated sequence of arithmetic operations, to achieve a predetermined target integer. The problem strictly limits each integer to be used by one time exactly. For example, for the integers 3, 6, 7, 51, 58 and the target integer 4, one possible solution is: 58−51 = 7, 6−7 = −1, 3×−1 = −3, −3 + 7 = 4, as shown in Figure 5 in Appendix A.4.
2.2 Data Synthesizing
Given the arithmetical puzzle described above in Section 2.1, we create a data synthesizing pipeline to efficiently generate the proposed dataset.
Denote the set of candidate integers as X = {X1, X2, . . . , XN } and the target number as T, where N is the total number of candidate integers in a puzzle sample. Each candidate integer Xi is independently sampled from a uniform distribution Xi ∼ U(1, V ), where V is the upper bound of the sampled integers. To avoid data overlapping, we have strictly ensured that for each puzzle, the candidate integers are a set of distinct numbers. The arithmetic operators involved in this problem are ops = {+, −, ×, ÷} and all operations are limited to integer operations. For example, when solving the puzzle with a division operator, the operation should be considered in integer division like 14/3 = 4. The detailed steps of synthesizing data for this puzzle is described in Algorithm 1.
Besides, to construct the SFT dataset, the prompt is deliberately designed to excludes any natural language cues and instead focuses on purely symbolic language. See Table 1 for an example of the constructed prompt and response.
2.3 Dataset
We split the dataset into training and in-distribution and out-of-distribution test dataset by controlling the total number of candidate integers N and the upper bound of the sampled integers V . We set

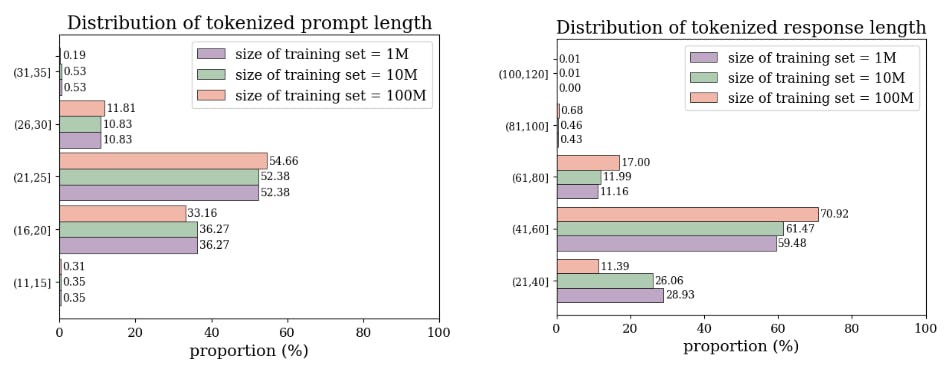
V = 60 for the training dataset, and sampled the candidate integers with N = 5, 6, 7. Three training datasets with different sizes scaling from 1 million to 10 millions and 100 millions are generated. And another 7500 samples (2500 samples for each N) under the same setting are generated as the in-distribution test dataset. Figure. 1 shows the distribution of N and X in these three training datasets. And the corresponding distribution of the tokenized prompt and response length is shown in Figure. 2.
To further evaluate the model’s performance on extrapolation, we have also designed two benchmarks of out-of-distribution dataset:
Numerical OOD test datasets. The upper bound of the sampled integers V is raised to 100 and 1000 separately to test the model’s generalization ability with unseen larger numbers. Specifically, 6000 samples are generated for each value of V with 2000 samples for each N. An additional filtering pipeline is applied to ensure that for each sample, there exists at least one integer Xi that satisfies 60 < Xi < 100 for the dataset with V = 100 and 100 < Xi < 1000 for that with V = 1000.
Form OOD test dataset. In mathematics, abstract forms often extend, such as expanding from a two-variable linear equation to one with three variables. For the proposed arithmetic puzzle, the extrapolation of abstract forms can be achieved by changing the number of candidate integers N. Clearly, when N increases, the exploration space leading to a feasible solution would expand exponentially, which results in an increased demand for precise reasoning steps. From another perspective, when the total number of the candidate integers changes, it actually requires the model’s ability to absorb and adapt to the puzzle’s abstract forms. Therefore, to test the model’s generalization capability from this point of view, we create another benchmark for OOD test dataset with 5000 samples generated with setting N to 8. To control variables, all the candidate integers in this dataset are sampled with the same upper bound V = 60 as the training dataset.
3 Model
3.1 Framework
We adopt the llama architecture (Touvron et al., 2023a) and employ low-rank adaptation (LoRA) tuning (Hu et al., 2021) based on the implementation of TRL full stack library (von Werra et al., 2020). LoRA achieves a remarkable reduction of 89% in our trainable parameters, from 3B to 0.3B.
3.2 Implementation Details
We train our model by fine-tuning open-llama-3B. We systematically apply left-padding to the query text and right-padding to the answer text to control the overall context length. All experiments are conducted with 8× NVIDIA A100-SXM4-80GB GPUs. The specific hyperparameter settings are listed in Table 3 in Appendix A.1.
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 Deed (Attribution-Noncommercial-Sharelike 4.0 International) license.
:::






{kind=link}