
Table of Links
-
Abstract and Introduction
-
Dataset
2.1 Baseline
2.2 Proposed Model
2.3 Our System
2.4 Results
2.5 Comparison With Proprietary Systems
2.6 Results Comparison
-
Conclusion
3.1 Strengths and Weaknesses
3.2 Possible Improvements
3.3 Possible Extensions and Applications
3.4 Limitations and Potential for Misuse
A. Other Plots and information
B. System Description
C. Effect of Text boundary location on performance
3 Conclusion
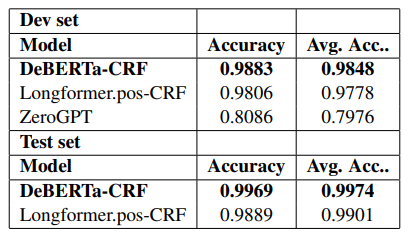
The metrics from Table 3 demonstrate the proposed model’s performance on both seen domain and generator data (dev set) along with unseen domain and unseen generator data (test set) , hinting at wider applicability. While there was a drop in accuracy at a word level, there was an increase in sentence level accuracy.
3.1 Strengths and Weaknesses
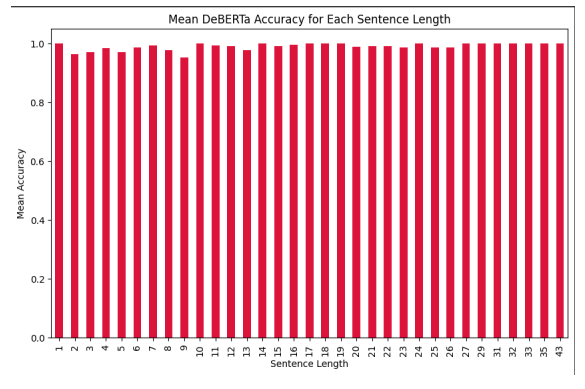
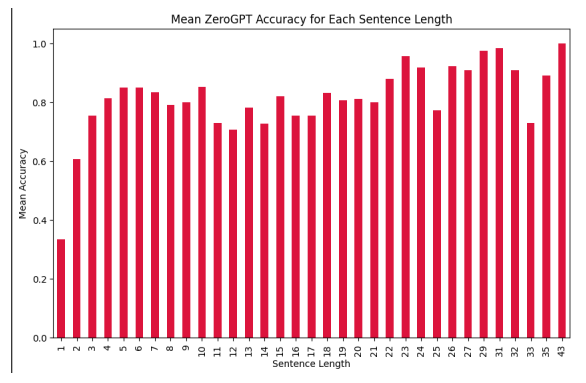
It was observed that the proprietary systems used for comparison struggled with shorter texts. i.e when the input text has fewer sentences, the predictions were either that the input text is fully human written or fully machine generated leading to comparatively low accuracy.
The average accuracy of sentence level classification for each text length of our model and ZeroGPT can be seen in Figure 2 , Figure 3 respectively. the proposed model overcomes this issue by providing more accurate results even on short text inputs.
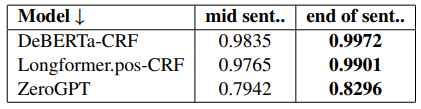
The sentence level accuracy did vary considerably while comparing cases where the actual text boundary is at the end of sentence and those where it is mid sentence. The results can be seen in Table 4.
Since the source and generators of texts individually wasn’t made available, the comparison between in-domain and out-of-domain texts couldn’t be made.
3.2 Possible Improvements
DeBERTa performed better when text boundaries are in the first half of the given text, while Longformer had better performance when the text boundary is in the other half as seen in Figure 4 and Figure 5. In cases where there was a significantly bigger MAE , atleast one of two (DeBERTa and Longformer) had made a very close prediction. There is a possibility that an ensemble of both
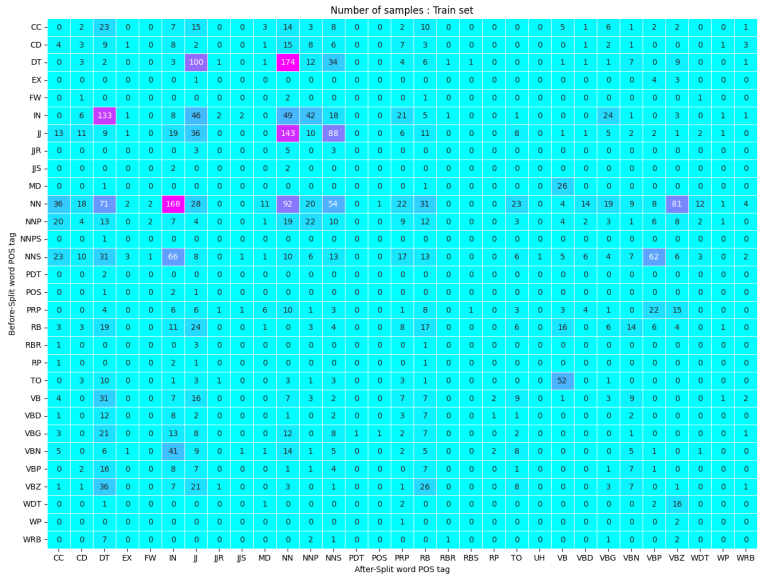
might perform better, as seen in Table 2, on the test set (unseen generators), while DeBERTa had a better MAE , Longformer had the better MARE. Further, the POS tags of the words pre and post text boundary were examined to find out what led to some cases having higher MAE. Though DeBERTa had better performance, when dealing with very long texts, Longformer might be a better choice. Figure 6 and Figure 7 display the count of data samples in train set and median MAE of those in test set for each POS tags combination pre and post split. The cases where the median MAE was higher (i.e 30 or above) had none or very few samples in the training set. Excluding those cases the new MAE was less than half of what it previously was. Adding more data that covers all cases of pre-split and post-split POS tag words might lead to better results. At a sentence level the accuracy was close to 100 percent excluding the above mentioned samples. Another possible approach worth testing is having a multiplier to the predicted values of each token before classifying as a 0 or 1.
as seen in Figure 6 and Figure 7, the biggest error cases in pre and post text boundary POS tags were the ones which were not present at all or in
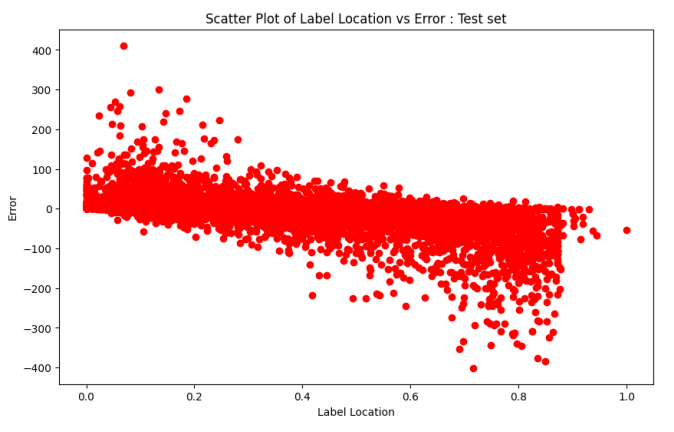
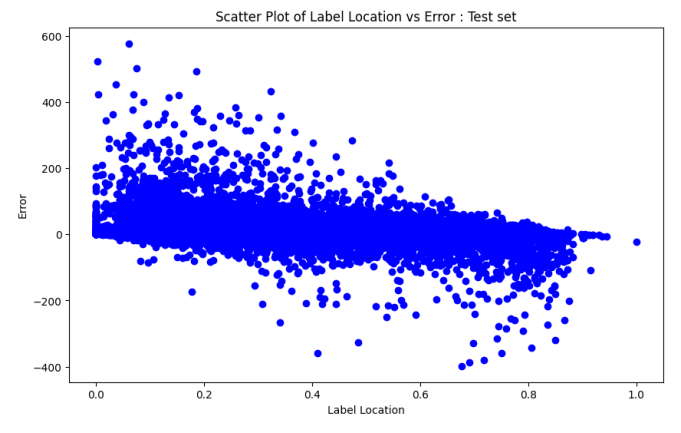
very minute amount in the training data, nearly 92 percentage of cases had less than 10 samples to train on and 64 percentage of cases had no samples at all in the training set. A potential solution would be including ample amount of data for all possibilities to cover wider range of texts. This can be done through generating more data by splitting the text at required word boundaries in existing texts and using an LLM to finish the texts.
3.3 Possible Extensions and Applications
The need to detect AI generated content is also prevalent over all languages. While the current model utilizes just English language data, gathering multilingual data and having a multilingual model might also be of great use. With the growth of misinformation and fake news using bots on social media handles(Zellers et al., 2019), being able to detect AI generated texts is of great importance. As most of the texts i.e posts , comments etc.. are shorter in length and difficult to detect, An extension of the current work by training on social media data may yield a good result as demonstrated in Figure 2 and Figure 3. The dataset mostly consisted of texts which are academic related while there is a need to detect machine generated texts in other fields too. Also, It is worth testing the performance of paraphrased data along with the existing data. Since, usage of additional data was prohibited, data augmentation wasn’t used in training the current models. It is likely that having more data to cover the cases of pre and post POS tags that weren’t present in the training dataset may improve the performance of the models. Some of the other findings are available in Appendix A.
3.4 Limitations and Potential for Misuse
While this novel task of detecting text boundaries in partially machine generated texts achieves a high accuracy where one change from human to machine occurs. Being able to handle the cases of multiple changes from human to machine and vice versa is vital. Since having a completely machine generated text and rewriting a few sentences in between or vice versa isn’t covered by this work or other existing models, there is a possibility that detection can be evaded this way. There is also a potential for misuse by learning what features and texts caused errors using the proposed models to create texts that can evade detection. The current study covers only two kinds of LLMs i.e GPT and LLaMa. The performance on other types of LLMs is still to be tested. With wide range of available LLMs, training the models over wider range of LLMs might improve performance. The current work focuses on just English texts, however it can be extended to other languages by replacing DeBERTa with mDeBERTa and training on a multilingual corpus. However not all languages are covered by mDeBERTa, this can be a potential issue when dealing with multilingual texts. Another kind of texts that need to be tested upon is where machine generated portions are generated by different generators, and the cases where it is completely machine generated but by different generators. The current corpus used to trained the models is sourced from academic platforms and academic essays, It is necessary to have models to work over a wide variety of texts including cases where it can be in a casual tone. While the current work only considers the first 512 tokens, the longformer version did achieve the same results on unseen generator texts. It is worth looking into how well chunking would work on the deberta model to process longer texts.

References
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M. Rush. 2019. GLTR: statistical detection and visualization of generated text. CoRR, abs/1906.04043.
GptKit. GPTKit: A Toolkit for Detecting AI Generated Text. https://gptkit.ai/. Accessed: 2024-02- 12.
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023. Debertav3: Improving deberta using electra-style pretraining with gradient-disentangled embedding sharing.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. 2020. Spanbert: Improving pre-training by representing and predicting spans. In Transactions of the Association for Computational Linguistics, volume 8, pages 64–77. MIT Press.
Diederik P. Kingma and Jimmy Ba. 2017. Adam: A method for stochastic optimization.
Ryuto Koike, Masahiro Kaneko, and Naoaki Okazaki. 2023. Outfox: Llm-generated essay detection through in-context learning with adversarially generated examples.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.
Andrew McCallum. 2012. Efficiently inducing features of conditional random fields.
OpenAI. 2024. Gpt-4 technical report.
Edward Tian and Alexander Cui. 2023. Gptzero: Towards detection of ai-generated text using zero-shot and supervised methods.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models.
Vice. 2023. AI Is Tearing Wikipedia Apart. https://www.vice.com/en/article/v7bdba/ ai-is-tearing-wikipedia-apart. Accessed: 2024-02-12.
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mohanned Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, Alham Fikri Aji, Nizar Habash, Iryna Gurevych, and Preslav Nakov. 2024a. M4gtbench: Evaluation benchmark for black-box machinegenerated text detection.
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, jinyan su, Artem Shelmanov, Akim Tsvigun, Osama Mohammed Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, Chenxi Whitehouse, Alham Fikri Aji, Nizar Habash, Iryna Gurevych, and Preslav Nakov. 2024b. Semeval-2024 task 8: Multidomain, multimodel and multilingual machine-generated text detection. In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pages 2041–2063, Mexico City, Mexico. Association for Computational Linguistics.
Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 2019. Defending against neural fake news. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc.
ZeroGPT. Zerogpt : Reliable chat gpt, gpt4 & ai content detector. https://www.zerogpt.com.
:::info
Author:
(1) Ram Mohan Rao Kadiyala, University of Maryland, College Park ([email protected]**).**
:::
:::info
This paper is available on arxiv under CC BY-NC-SA 4.0 license.
:::



")


{kind=link}