Table of Links
Abstract and 1 Introduction
2 LongFact: Using LLMs to generate a multi-topic benchmark for long-form factuality
3 Safe:LLM agents as factuality autoraters
4 LLMs agents can be better factuality annotators than humans
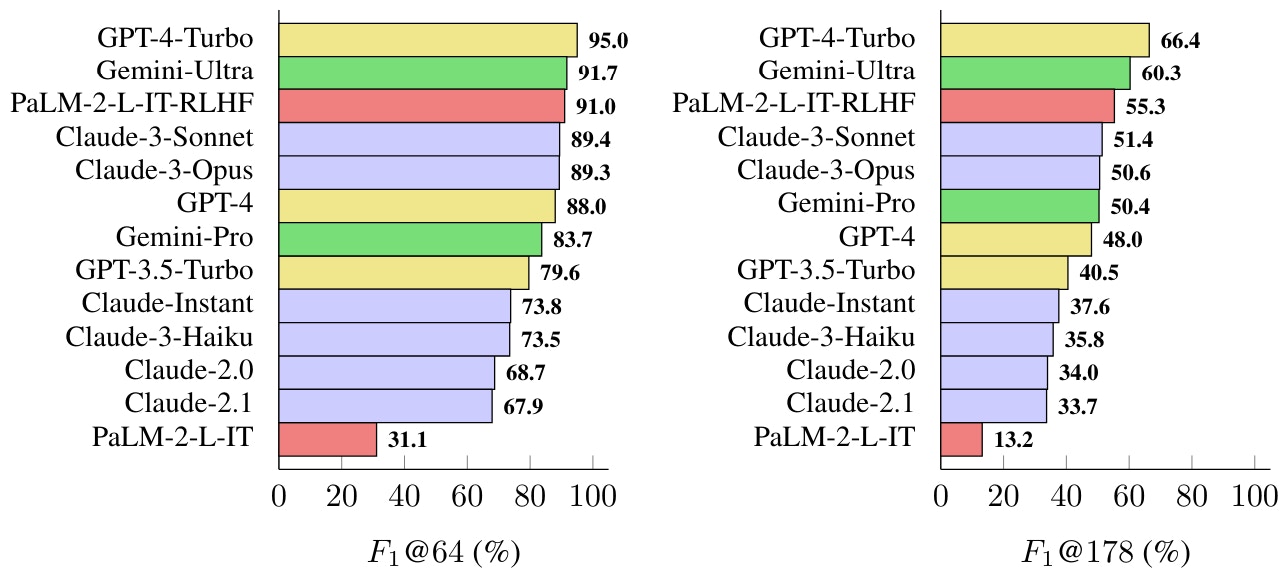
5 F1@k: Extending F1 with recall from human-preferred length
6 Larger LLMs are more factual
7 Related Work
8 Limitations
9 Conclusion, Acknowledgments, Author Contribution, and References
Appendix
A. Frequently asked questions
B. LongFact details
C. SAFE details
D. Metric details
E. Further analysis
Benchmarking factuality. Recent studies on factuality in large language models have presented several factuality benchmarks. Many benchmarks such as FELM (Chen et al., 2023), FreshQA (Vu et al., 2023), and HaluEval (Li et al., 2023) simply test a model’s knowledge of various factoids. On the other hand, adversarial benchmarks such as TruthfulQA (Lin et al., 2022) and HalluQA (Cheng et al., 2023b) consist of prompts that are designed to test whether a language model will generate a false factoid learned from imitating popular misconceptions. In the long-form setting, Min et al. (2023) proposed a set of prompts that require language models to generate biographies about people, evaluated against each person’s respective Wikipedia article. Our proposed prompt set does not dispute the importance of these tasks, but rather aims to provide broad coverage of factuality in a long-form setting, whereas existing benchmarks either cover singular short factoids or only cover a small set of long-form topics.
Evaluating factuality in model responses. In order to fully benchmark a model’s factuality, there must exist a reliable method for quantifying the factuality of a model response to a given prompt. Performance on factuality datasets with short ground-truth answers can often be evaluated using language models that have been fine-tuned on human evaluations (Lin et al., 2022; Sellam et al., 2020; Lin, 2004). Long-form responses, on the other hand, are harder to evaluate because they contain a much-broader range of possible factual claims. For example, FActScore (Min et al., 2023) leverages Wikipedia pages as knowledge sources for humans and language models to use when rating long-form responses on biographies about people. In reference-free contexts, RAGAS (Es et al., 2023) evaluate whether a response from a retrieval-augmented generation (RAG) system is self-contained by prompting a large language model to check the consistency among questions, retrieved contexts, answers, and statements within the answer. This matches the case study in Guan et al. (2023), which also showed that language models may serve as a strong tool for fact verification. Tian et al. (2023) leverages this intuition to demonstrate that factuality preference rankings obtained via model confidence can be used for improving factuality in responses via direct preference optimization. Improvements in human evaluation can also be important for evaluating factuality; in this domain, Cheng et al. (2023a) created an interface for human evaluation by asking fact-verification questions and checking self-consistency of model responses. Most related to our work, Chern et al. (2023) proposed a method of rating model responses by breaking them down and rating individual components via external tools and applied this in tasks such as code generation, math reasoning, and short-answer QA. Our proposed method takes inspiration from this work, but applies it in the long-form factuality setting, similar to other work that uses search-augmented language models for fact verification (Gao et al., 2023; Wang et al., 2023; Zhang & Gao, 2023). Compared to these prior methods of evaluating factuality, SAFE is automatic, does not require any model finetuning or any preset reference answers/knowledge sources, and is more-reliable than crowdsourced human annotations while only requiring a fraction of the cost.
Quantifying long-form factuality. Long-form factuality is difficult to quantify because the quality of the response is influenced both by the factuality of the response (precision) and by the coverage of the response (recall). FActScore (Min et al., 2023) measures precision with respect to Wikipedia pages as knowledge sources and mentions the difficulty of measuring recall as future work. Tian et al. (2023) and Dhuliawala et al. (2023) also use precision as a proxy for a model response’s factuality. Other metrics such as token-level F1 score (Rajpurkar et al., 2016), sentence or passage-level AUC (Manakul et al., 2023), and similarity to ground-truth (Wieting et al., 2022) can account for recall as well as precision but require human responses or judgements that serve as a ground-truth. Our proposed F1@K, on the other hand, measures both precision and recall of a long-form response without requiring any preset ground-truth answers, only the number of facts from each label category.
Authors:
(1) Jerry Wei, Google DeepMind and a Lead contributors;
(2) Chengrun Yang, Google DeepMind and a Lead contributors;
(3) Xinying Song, Google DeepMind and a Lead contributors;
(4) Yifeng Lu, Google DeepMind and a Lead contributors;
(5) Nathan Hu, Google DeepMind and Stanford University;
(6) Jie Huang, Google DeepMind and University of Illinois at Urbana-Champaign;
(7) Dustin Tran, Google DeepMind;
(8) Daiyi Peng, Google DeepMind;
(9) Ruibo Liu, Google DeepMind;
(10) Da Huang, Google DeepMind;
(11) Cosmo Du, Google DeepMind;
(12) Quoc V. Le, Google DeepMind.





{kind=link}