
Imagine your AI assistant summarizing a lengthy report (50 pages) but adding a fictitious fact that could influence a crucial choice. How can you believe it? While ROUGE and other traditional tools check for word matches, they fall short in accuracy, clarity, and capturing the essence of the content. New artificial intelligence (AI) systems, called agentic AI, are taking over to produce and assess trustworthy, understandable, and significant summaries.
What Qualifies as an Excellent Summary?
It takes more than just word matching to create an excellent summary. It’s about accurately stating the facts, making sense, and perfectly capturing the main idea. What matters is this:
Accuracy: There must be no errors or fabricated statistics; every detail must correspond to the original document.
Clarity: The summary should be easily read and contain logically flowing ideas.
Essence: It captures the key points and main ideas.
An Improved Method for Evaluating Summaries
A straightforward framework can be used to assess summaries correctly:
- From 1 (poor) to 5 (excellent), assign a score to each component (such as clarity or accuracy).
- Examine each aspect’s specific details (see the table below).
- The total rating is the sum of the scores.
| Criterion | Description | Key Elements to Check |
|—-|—-|—-|
| Consistency | Without any hallucinations, the summary should be factually accurate and consistent with the original document. | Are all facts and data points rightly represented?Are any details fake or hallucinated?Does the meaning remain clear and unaltered? |
| Relevance | Only the most important and contextually relevant details should be included in the summary. | Does the summary capture the main idea of the document?Does it exclude unnecessary or minor details?Is the information included important for the intended audience? |
| Conciseness | The summary should be brief yet comprehensive, removing redundancy while preserving meaning. | Does the target audience need the information included?Does it avoid excessive wordiness while retaining clarity?Is the content compact without sacrificing key details? |
| Fluency | The text should be grammatically correct, well-structured, and easy to read. | Is the sentence structure and grammar correct?Does the synopsis sound logical and flow naturally?Does the writing avoid awkward phrasing, and is it clear? |
| Coverage | The summary should include all essential aspects, including key data, facts, and insights from the original document. | Are all major findings or claims included?Does it include important numerical or statistical data?Are there any crucial details missing that change the meaning? |
| Coherence | The sentences should be well-organized and logically connected for clarity. | Are concepts presented in a logical order with no sudden changes?Do paragraphs and sentences flow well together?Is the structure of the summary consistent? |
Rating Scale**
Based on the estimated amount of human rework needed, the recommended rating scale for the overall score is:
26–30: Minimal Rework Needed: The summary is very well written and needs little to no human editing.
21–25: Light Rework Needed: Although the summary is good, it might need a few small revisions or improvements.
16–20: Moderate Rework Needed: Although the summary is reasonable, it needs a lot of editing and enhancement.
11–15: Significant Rework Is Required: The summary needs to be significantly rewritten and restructured due to its poor quality.
6-10: Total Rewrite Required: The synopsis needs to be completely revised because it is unacceptable.
Agentic AI: A Better Way to Rate Summaries
It takes time to review summaries manually. Agentic AI systems can do this automatically by using several AI “agents,” each of which focuses on a different part, such as accuracy or clarity. The agents give the summary a score and explain why they assigned that score, which speeds up and makes the process more consistent.
How It Works
Although human evaluation has its advantages, it also requires a lot of time and resources. A possible remedy is provided by agentic AI systems, which automate the assessment procedure by combining several AI agents.
Input: The original text, the summary, and sometimes an example written by a person.
Evaluation Agents: Each agent looks at one thing, like an “Accuracy Agent” who finds mistakes in facts.
Scoring Agent: Adds up the scores and gives a clear explanation.
Architecture: Agentic Evaluation System
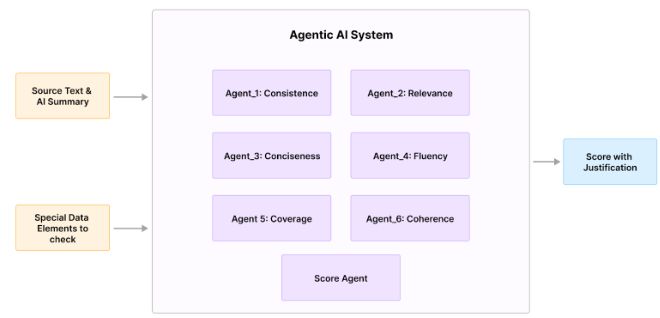
n Template and Configuration for Agents
The configuration of an autonomous agent system aimed at carefully evaluating the factual correctness of AI-generated summaries in relation to their original sources is described in this paper. In this system, every agent is assigned a distinct role, goal, operational background (context), assignment, and output structure. For instance, the agent’s instructions incorporate particular assessment criteria, such as “consistency,” right into the text.
- Function: Expert in Consistency.
- Objective: Assess the summary’s factual coherence with the original document.
- Background: You are an experienced fact-checker who is skilled at spotting errors and discrepancies.
- The assignment is to read both the generated summary and the original document.
- Give consistency a number between 1 and 5, where 5 represents complete consistency and 1 represents extreme inconsistency.
- Provide a thorough explanation of the score, emphasizing any particular discrepancies that were discovered.
- Results:
- Rating: (1–5)
- Rationale: “…”
Tools to Build It
The following tools and technologies are recommended:
AI Frameworks: Programs for managing numerous agents, such as Autogen or CrewAI.
AI Models: Open-source alternatives like Llama or more sophisticated models like Claude and GPT-4.
Open-Source LLMs: Enhanced versions of models such as Mistral, Falcon, or Llama can be hosted and utilized as endpoints.
OpenAI’s o1, o2, and o3 reasoning models, as well as multi-modal models like GPT-Omni, LLama, and Anthropic Sonnet
Overcoming the Difficulties in LLM Evaluation
Although LLM-based evaluation offers a big improvement, especially when done with agentic systems, it has drawbacks that must be carefully considered. Because they are stochastic, evaluator LLMs themselves may experience hallucinations, generate inconsistent results, and display biases acquired from their training data. In order to mitigate these problems, specific domain-specific examples must be used for fine-tuning, evaluations must be grounded in source-document evidence (e.g., RAG), deterministic sampling techniques must be used for reproducibility, clear prompts and rubrics must be developed, and model biases must be actively audited for and addressed.
The computational expense and latency of complex assessments must also be taken into account when implementing these systems in practice, as well as the inherent challenge of objectively assessing subjective attributes like “clarity” or “capturing the essence.” Here, tactics include breaking down subjective criteria into more quantifiable parts, optimizing resource use, utilizing human feedback to train models on complex assessments, and implementing tiered evaluation systems with models of differing complexity. In the end, creating reliable LLM-driven evaluation requires an ongoing development cycle, thorough testing, and essential human supervision to verify and improve the automated tests.
How Summarization Is Impacting Industries, Especially in the Life Sciences
In addition to saving time, LLM-powered summarization is revolutionizing workflows and promoting innovation across a range of industries, with the life sciences being notably impacted.
Rapid Literature Review: To speed up drug discovery and development, quickly compile scientific literature from research papers, clinical trial reports, and patents to identify important trends, findings, and potential targets.
Simplified Regulatory Submissions: Compile preclinical and clinical data automatically to ensure consistency and completeness, which speeds up the production of important regulatory documents (like CTDs).
Better Market Access Strategies: Condense complex clinical trial and health economic data to create succinct, evidence-based Global Value Dossiers (GVDs) that support decisions about market access and reimbursement.
Improved Pharmacovigilance: Use automated summaries to analyze vast amounts of patient feedback and adverse event reports, facilitating quicker risk mitigation and safety signal identification.
Better Communication in Medical Affairs: Provide succinct overviews of publications and guidelines to Medical Science Liaisons (MSLs) to promote educated dialogue and enhance patient care.
This change is also giving rise to new positions:
Prompt Engineers: Preparing effective prompts to guide LLMs.
Finetuning Specialists: Optimizing LLM accuracy and performance, particularly for specialized life science datasets.
Agentic AI System Architects: Creating and implementing complex multi-agent systems.
Evaluation and Validation Engineers: Ensuring the quality and reliability of LLM-generated summaries. Specifically, it involves validating summaries against scientific and regulatory standards.
Conclusion: Summaries’ Future
The way we handle information is evolving due to AI-powered summarization. We are improving the accuracy, clarity, and utility of summaries through the use of agentic AI and intelligent evaluation systems. There are still obstacles to overcome, but enormous potential is unlocked when human insight is combined with AI’s speed. This isn’t just about faster summaries, but it’s about smarter decisions and progress in every field.
n





{kind=link}