
Table of Links
Abstract and 1 Introduction
2 Pre-Training
2.1 Tokenization
2.2 Pre-Training Data
2.3 Stability
2.4 Inference
3 Alignment and 3.1 Data
3.2 Fine-Tuning Strategy
4 Human Evaluations and Safety Testing, and 4.1 Prompts for Evaluation
4.2 Baselines and Evaluations
4.3 Inter-annotator Agreement
4.4 Safety Testing
4.5 Discussion
5 Benchmark Evaluations and 5.1 Text
5.2 Image-To-Text
6 Related Work
7 Conclusion, Acknowledgements, Contributors, and References
Appendix
A. Samples
B. Additional Information of Human Evaluations
5.2 Image-To-Text
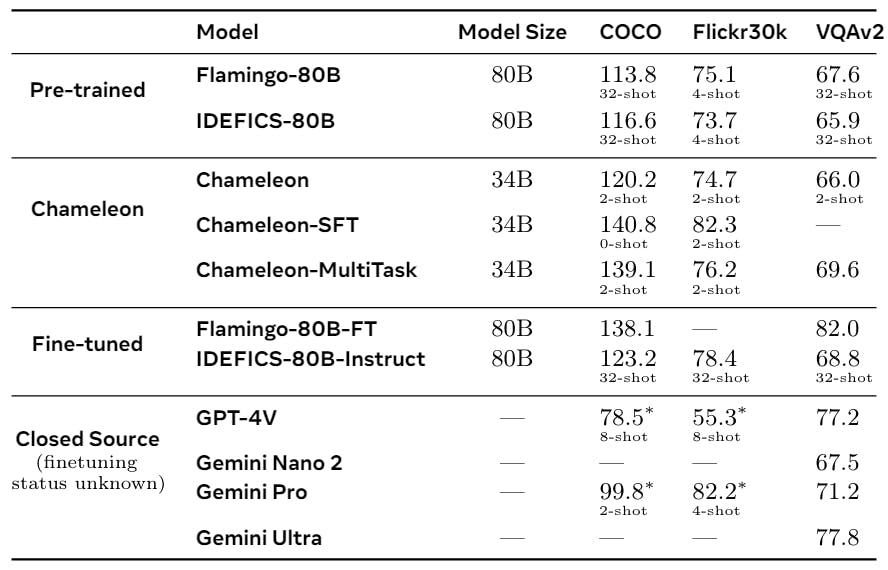
We next evaluate Chameleon on the segment of tasks that requires text generation conditioned on an image, specifically on image captioning and visual question-answering tasks, and present results of Chameleon-34B in Table 7. Together with our pre-trained model, we also present results with a model fine-tuned on all tasks together (Chameleon-34B-MultiTask), as well as models exclusively fine-tuned for the specific evaluation tasks (Chameleon-34B-SFT).
We evaluate against available open-source late-fusion models: specifically Flamingo 80B (Alayrac et al., 2022), IDEFICS 80B (Laurençon et al., 2023), and Llava-1.5 (Liu et al., 2023a), as well as recent closed-source models, such as Gemini (Gemini et al., 2023) and GPT4-V (OpenAI, 2023). We note that we did not take any special care when formatting the pre-training data to ensure that 0-shot inference can be effectively done. Therefore, we augment the input images or questions with the published prompts used by other models. This was purposefully done to maintain the fidelity of the pre-training data.
• Image Captioning: For image captioning evaluations we report CiDER (Vedantam et al., 2015) scores on the Karpathy test split of MS-COCO (Lin et al., 2014), and the Karpathy test split of Flickr30k (Plummer et al., 2015) using the pycocoevalcap (Chen et al., 2020) package. For Chameleon models, we restrict captions to 30 tokens. We evaluated GPT-4V and Gemini models using several prompts and generation lengths via their APIs and report the best performance that we were able to achieve.
In the open-source pre-trained category, Chameleon-34B (2-shot) outperforms the larger 80B models of both Flamingo and IDEFICS on COCO with 32-shots, while matching their performance on Flickr30k. With respect to fine-tuned/closed-source models, both multi-task and SFT variants of Chameleon-34B outperform all other models on COCO, while for Flickr30k, the SFT model outperforms other models with the multitask model being a close competitor.
• Visual Question Answering: For visual question answering (VQA) we report performance on the testdev split of VQA-v2 (Goyal et al., 2017). For VQA-v2, the pre-trained Chameleon-34B model with 2-shots matches the 32-shot performance of the larger Flamingo and IDEFICS models, while for finetuned/closed models, Chameleon-34B-Multitask approaches the performance of IDEFICS-80B-Instruct and Gemini Pro, but trails larger models such as Flamingo-80B-FT, GPT-4V, and Gemini Ultra. Llava-1.5 outperforms Chameleon-34B on VQAv2 potentially owing to its additional fine-tuning on

conversations from GPT-4, ShareGPT (ShareGPT, 2023), GQA (Hudson and Manning, 2019), and region-level VQA datasets, but significantly trails behind on the other tasks.
In general, we find Chameleon is fairly competitive on both image captioning and VQA tasks. It rivals other models by using much fewer in-context training examples and with smaller model sizes, in both pre-trained and fine-tuned model evaluations.
Author:
(1) Chameleon Team, FAIR at Meta.







{kind=link}