
Table of Links
Abstract and 1. Introduction
-
Related Work
2.1 Open-world Video Instance Segmentation
2.2 Dense Video Object Captioning and 2.3 Contrastive Loss for Object Queries
2.4 Generalized Video Understanding and 2.5 Closed-World Video Instance Segmentation
-
Approach
3.1 Overview
3.2 Open-World Object Queries
3.3 Captioning Head
3.4 Inter-Query Contrastive Loss and 3.5 Training
-
Experiments and 4.1 Datasets and Evaluation Metrics
4.2 Main Results
4.3 Ablation Studies and 4.4 Qualitative Results
-
Conclusion, Acknowledgements, and References
Supplementary Material
A. Additional Analysis
B. Implementation Details
C. Limitations
4 Experiments
We evaluate our proposed approach on the diverse tasks of open-world video instance segmentation (OW-VIS), dense video object captioning (Dense VOC), and closed-world video instance segmentation (VIS). Note that there is no dedicated dataset for the task of open-world video instance segmentation and captioning. Hence we use the three aforementioned tasks and evaluate the three different aspects of our approach: open-world capability, video object captioning, and video instance segmentation. In the following subsections, we first discuss the datasets and evaluation metrics used in our evaluation in Sec. 4.1. We then compare our performances to baselines in Sec. 4.2. We demonstrate how each of our contributions results in better performance through an ablation study in Sec. 4.3. Finally we show some qualitative results in Sec. 4.4.
4.1 Datasets and Evaluation Metrics
We evaluate our approach on the OW-VIS, Dense VOC and VIS tasks. For OW-VIS, we use the challenging BURST dataset [2]. For the Dense VOC task,
![Table 5: Ablation on the VidSTG [57] data. ‘w/o m.a.’ refers to without masked attention. ‘bb. cap.’ and ‘en. bb. cap.’ refers to bounding box captioning and enlarged bounding box captioning.](https://cdn.hackernoon.com/images/null-sy233bh.png)
we use the VidSTG dataset [57]. Note that VidSTG [57] has bounding box and tracking identity for all objects, but captions are not exhaustively provided. However, DVOC-DS [58] uses VidSTG [57] for the Dense VOC task by removing the captioning loss for missing captions during training and not evaluating the missing captions during evaluation. We follow a similar setting. For the VIS task, we evaluate on the OVIS dataset [36].

4.2 Main Results
Open-world video instance segmentation (BURST). Tab. 1 shows our results for the OW-VIS task on the BURST dataset [2]. We report the openworld tracking accuracy for all, common (comm.) and uncommon (unc.) categories. For the uncommon classes, we achieve the state-of-the-art, improving upon the next best method (Mask2Former [8]+DEVA [10]) by ∼ 6 points on

the BURST [2] validation data and by ∼ 4 points on the BURST test data. For the common categories, our method ranks 2 nd in the BURST validation data. We use a SwinL [29] backbone, a clip-length of T = 1, and DEVA [10] for the temporal association of objects.
Dense video object captioning (VidSTG). Tab. 2 shows our results on the Dense VOC task. We outperform DVOS-DS [58] on the captioning accuracy (CapA), demonstrating that our captioning head with masked attention (Sec. 3.3) is effective in generating object-centric captions. We improve upon DS-VOC on the overall CHOTA metric, even though we slightly underperform on DetA and AssA. Note that DVOS-DS is an offline method: the entire object trajectories are used for generating the captions. Hence DVOS-DS cannot process videos with more than 200 frames. This is in contrast to our online method, where we sequentially process short video clips of length T = 2. This enables to process very long videos. DVOS-DS uses a ViT [14] backbone, whereas we use SwinL [29], which leads to a difference in DetA scores. We use a clip-length T = 2 for this experiment. Note that T = 2 enables the object queries to be spatio-temporally rich. This helps in generating better object-centric captions. For tracking, we use CAROQ [13] to propagate object queries across frames.
Video instance segmentation (OVIS). Tab. 3 shows our results for the closed-world video instance segmentation task on the OVIS [36] dataset. In the closed-world setting, we disable the open-world object queries. We notice that the contrastive loss Lcont (discussed in Sec. 3.4) improves the closed-world results. We use a clip-length of T = 2 in this setting and CAROQ [13] to combine results from video clips.

4.3 Ablation Studies

Masked attention. Tab. 5 shows that masked attention in the object-to-text transformer of the captioning head, described in Sec. 3.3, helps in object-centric captioning using the VidSTG [57] data.
The second row ‘w/o m.a.’ of Tab. 5 refers to the setting without masked attention, i.e., the entire image feature is used to calculate the cross-attention in the object-to-text-transformer. The object-centric context is only accumulated by concatenating the i th object query with the learnt text embeddings, as discussed in Sec. 3.3 and shown in Fig. 2. We observe that the captioning accuracy CapA drops by 23 points, indicating that concatenating the object query with the text embeddings is not sufficient for an object-centric focus.
The third row in Tab. 5, ‘bb. cap.’ (bounding box captioning), pursues the opposite setting. Here, the images are cropped based on the object bounding box predictions in the detection head. The cropped images are directly used for captioning, ensuring that both the self and cross attention blocks in the object-to-text transformer operate on object-centric features. Note, that we don’t use masked attention in this setting. We see a drop in CapA of 5 points in this setting. Although the cropping helps in retaining the object-centric information, the overall context from the entire image is missing.
The fourth row in Tab. 5, ‘en. bb. cap.’ (enlarged bounding box captioning), shows a similar setting as the third row, but the bounding boxes are first enlarged by 10% to provide more overall image context. The enlarged bounding boxes are then used to crop the images for captioning. We observe a drop in CapA of 3 points in this setting, indicating that enlarging the bounding boxes helps but is not sufficient to provide overall context.
The first row in Tab. 5, ‘Ours’ (our approach), where we retain the overall context using self attention in the object-to-text transformer and focus on the object-centric features using masked cross attention, performs the best among these settings.
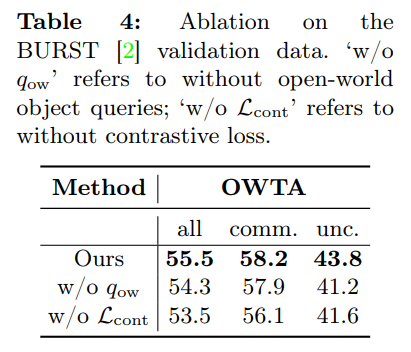
Contrastive loss. Tab. 4 (first and last rows) shows how the contrastive loss Lcont, described in Sec. 3.4, helps in detecting both the common (comm.) and uncommon (unc.) categories of objects. The performance drops by ∼ 2 points for both the common and uncommon categories for the setting ‘w/o Lcont’, i.e., when the contrastive loss is not used. The contrastive loss helps in removing highly overlapping false positives in the closed-world setting and in discovering new objects in the open-world setting. Tab. 3 further shows that the contrastive loss helps in detecting objects in the closed-world setting.
4.4 Qualitative Results
We provide qualitative results generated by OW-VISCap in this section. Fig. 1 shows an example from the BURST [2] dataset. OW-VISCap is able to simultaneously detect, track and caption objects in the given video frames. The objects belong to both the open- and closed-world. Note that the BURST [2] dataset doesn’t have object-centric captions available for training or evaluation, hence our captioning head was not trained on BURST [2]. We train the captioning head on the Dense VOC task (whose results are shown in Tab. 2). We find this captioning-head to be effective in generating meaningful object-centric captions even for objects never seen during training. Fig. 3 shows two examples from the BURST validation data. We are able to consistently detect, segment, and track the previously seen and unseen objects. Fig. 4 shows an example from the VidSTG [57] data. Our approach is able to detect and track objects in the scene consistently, and to generate meaningful object-centric captions for each of the detected objects.
:::info
Authors:
(1) Anwesa Choudhuri, University of Illinois at Urbana-Champaign ([email protected]);
(2) Girish Chowdhary, University of Illinois at Urbana-Champaign ([email protected]);
(3) Alexander G. Schwing, University of Illinois at Urbana-Champaign ([email protected]).
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::






{kind=link}