Table of Links
Abstract and 1. Introduction
2 Concepts in Pretraining Data and Quantifying Frequency
3 Comparing Pretraining Frequency & “Zero-Shot” Performance and 3.1 Experimental Setup
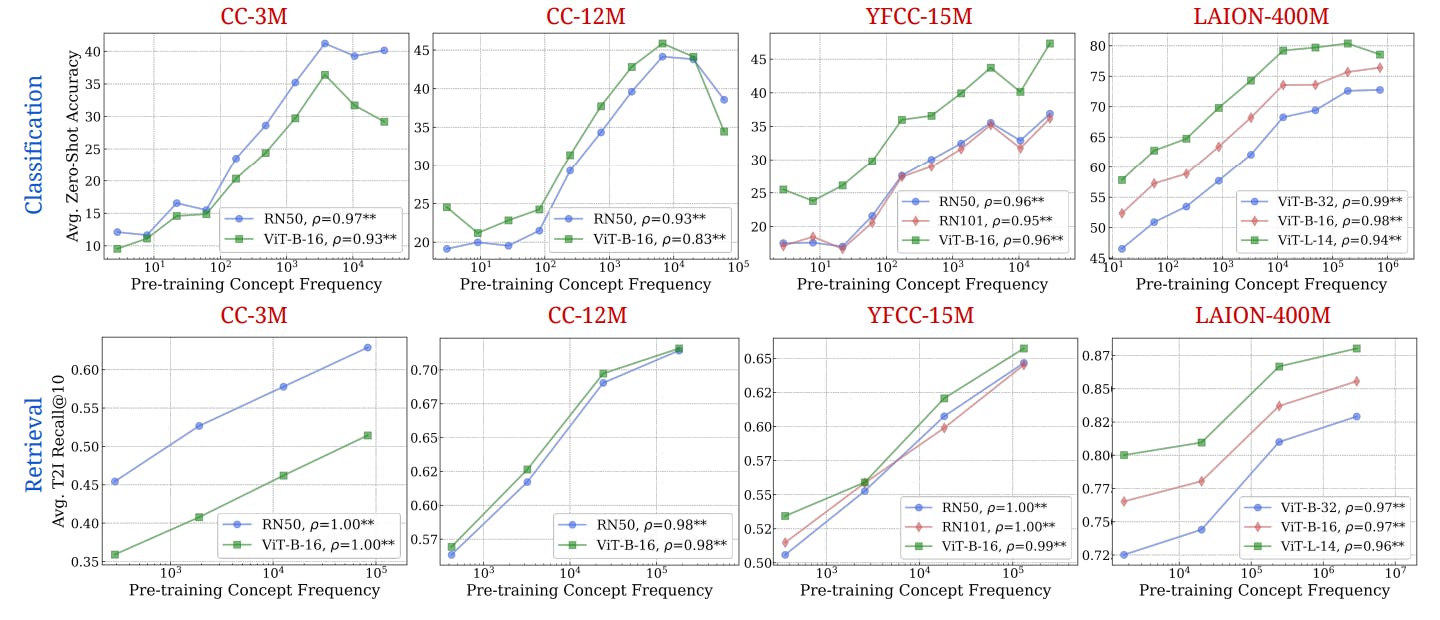
3.2 Result: Pretraining Frequency is Predictive of “Zero-Shot” Performance
4 Stress-Testing the Concept Frequency-Performance Scaling Trend and 4.1 Controlling for Similar Samples in Pretraining and Downstream Data
4.2 Testing Generalization to Purely Synthetic Concept and Data Distributions
5 Additional Insights from Pretraining Concept Frequencies
6 Testing the Tail: Let It Wag!
7 Related Work
8 Conclusions and Open Problems, Acknowledgements, and References
Part I
Appendix
A. Concept Frequency is Predictive of Performance Across Prompting Strategies
B. Concept Frequency is Predictive of Performance Across Retrieval Metrics
C. Concept Frequency is Predictive of Performance for T2I Models
D. Concept Frequency is Predictive of Performance across Concepts only from Image and Text Domains
E. Experimental Details
F. Why and How Do We Use RAM++?
G. Details about Misalignment Degree Results
H. T2I Models: Evaluation
I. Classification Results: Let It Wag!
2 Concepts in Pretraining Data and Quantifying Frequency
In this section, we outline our methodology for obtaining concept frequencies within pretraining datasets. We first define our concepts of interest, then describe algorithms for extracting their frequencies from images
![Figure 1: Concept Extraction and Frequency Estimation Pipeline. (left) We compile 4, 029 concepts from 17 classification, 2 retrieval, and 8 image generation prompt datasets. (right) We construct efficient indices for both text-search (using standard unigram indexing (1)) and image-search (using RAM++ [59] (2)); intersecting hits from both gives us (3) the image-text matched frequencies per concept.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
![Figure 1: Concept Extraction and Frequency Estimation Pipeline. (left) We compile 4, 029 concepts from 17 classification, 2 retrieval, and 8 image generation prompt datasets. (right) We construct efficient indices for both text-search (using standard unigram indexing (1)) and image-search (using RAM++ [59] (2)); intersecting hits from both gives us (3) the image-text matched frequencies per concept.](https://hackernoon.imgix.net/images/fWZa4tUiBGemnqQfBGgCPf9594N2-x1832pn.png?auto=format&fit=max&w=3840)
and text captions of pretraining datasets. Finally, we discuss how to aggregate them to calculate matched image-text concept frequencies. For a schematic overview of our methods, see Fig. 1.
Defining Concepts. We define “concepts” as the specific objects or class categories we seek to analyze in the pretraining datasets. For zero-shot classification tasks, these concepts are the class names, such as the 1, 000 classes in ImageNet [35] (e.g., “tench”, “goldfish”, “stingray”). For image-text retrieval and image generation tasks, concepts are identified as all nouns present in the test set captions or generation prompts, respectively. For example, in the caption, “A man is wearing a hat”, we extract “man” and “hat” as relevant concepts. We additionally filter out nouns that are present in less than five downstream evaluation samples to remove ambiguous or irrelevant concepts. Across all our experiments, we collate a list of 4, 029 concepts sourced from 17 classification, 2 retrieval, and 8 image generation downstream datasets (see Tab. 1 for details).
Concept Frequency from Text Captions. To enable efficient concept searches, we pre-index all captions from the pretraining datasets, i.e., construct a mapping from concepts to captions. We first use part-of-speech tagging to isolate common and proper nouns and subsequently lemmatize them to standardize word forms [65] with SpaCy [58] . These lemmatized nouns are then cataloged in inverted unigram dictionaries, with each noun being the key and all the indices in the pretraining data samples containing that noun being its values. To determine the frequency of a concept, particularly those composed of multiple words, we examine the concept’s individual unigrams within these dictionaries. For multi-word expressions, by intersecting the lists of sample indices corresponding to each unigram, we identify the samples that contain all parts of the concept. The frequency of the concept in the text captions is the count of these intersecting sample indices. Our frequency estimation algorithm hence allows scalable O(1) search with respect to the number of captions for any given concept in the pretraining dataset captions.
Concept Frequency from Images. Unlike text captions, we do not have a finite vocabulary for pre-indexing pretraining images, and thus cannot perform O(1) concept lookup. Instead, we collect all the 4, 029 downstream concepts and verify their presence in images using a pretrained image tagging model. We tested various open-vocabulary object detectors, image-text matching models and multi-tagging models. We found that RAM++ [59]—an open-set tagging model that tags images based on a predefined list of concepts in a multi-label manner—performs the best. This approach generates a list of pretraining images, each tagged with whether the downstream concepts are present or not, from which we can compute concept frequencies. We provide qualitative examples along with design choice ablations in Appx. F.
Image-Text Matched Concept Frequencies. Finally, we combine the frequencies obtained from both text and image searches to calculate matched image-text frequencies. This involves identifying pretraining


samples where both the image and its associated caption correspond to the concept. By intersecting the lists from our image and text searches, we determine the count of samples that align in both modalities, offering a comprehensive view of concept representation across the dataset. We note that this step is necessary as we observed significant image-text misalignment between concepts in the pretraining datasets (see Tab. 3), hence captions may not reflect what is present in the image and vice-versa. This behaviour has also been alluded to in prior work investigating pretraining data curation strategies [76, 75, 124, 83]. We provide more detailed analysis on image-text misalignment in Sec. 5.
Authors:
(1) Vishaal Udandarao, Tubingen AI Center, University of Tubingen, University of Cambridge, and equal contribution;
(2) Ameya Prabhu, Tubingen AI Center, University of Tubingen, University of Oxford, and equal contribution;
(3) Adhiraj Ghosh, Tubingen AI Center, University of Tubingen;
(4) Yash Sharma, Tubingen AI Center, University of Tubingen;
(5) Philip H.S. Torr, University of Oxford;
(6) Adel Bibi, University of Oxford;
(7) Samuel Albanie, University of Cambridge and equal advising, order decided by a coin flip;
(8) Matthias Bethge, Tubingen AI Center, University of Tubingen and equal advising, order decided by a coin flip.







{kind=link}