Table of Links
Abstract and 1 Introduction
-
Related Work
-
Our Proposed DiverGen
3.1. Analysis of Data Distribution
3.2. Generative Data Diversity Enhancement
3.3. Generative Pipeline
-
Experiments
4.1. Settings
4.2. Main Results
4.3. Ablation Studies
-
Conclusions, Acknowledgments, and References
Appendix
A. Implementation Details
B. Visualization
3.1. Analysis of Data Distribution
Existing methods [28, 29, 34] often attribute the role of generative data to addressing class imbalance or data scarcity. In this paper, we provide an explanation for two main questions from the perspective of distribution discrepancy.
Why does generative data augmentation enhance model performance? We argue that there exist discrepancies between the model learned distribution of the limited real training data and the distribution of real-world data. The role of adding generative data is to alleviate the bias of the real training data, effectively mitigating overfitting the training data.
First, to intuitively understand the discrepancies between different data sources, we use CLIP [21] image encoder to extract the embeddings of images from different data sources, and then use UMAP [18] to reduce dimensions for visualization. Visualization of data distributions on different sources is shown in Figure 1. Real-world data (LVIS [8] train and LVIS val) cluster near the center, while generative data (Stable Diffusion [22] and IF [24]) are more dispersed, indicating that generative data can expand the data distribution that the model can learn.
hen, to characterize the distribution learned by the model, we employ the free energy formulation used by Joseph et al. [10]. This formulation transforms the logits outputted by the classification head into an energy function. The formulation is shown below:



What types of generative data are beneficial for improving model performance? We argue that there are also discrepancies between the distribution of the generative data and the real-world data distribution. If these discrepancies are not properly addressed, the full potential of the generative model cannot be attained.
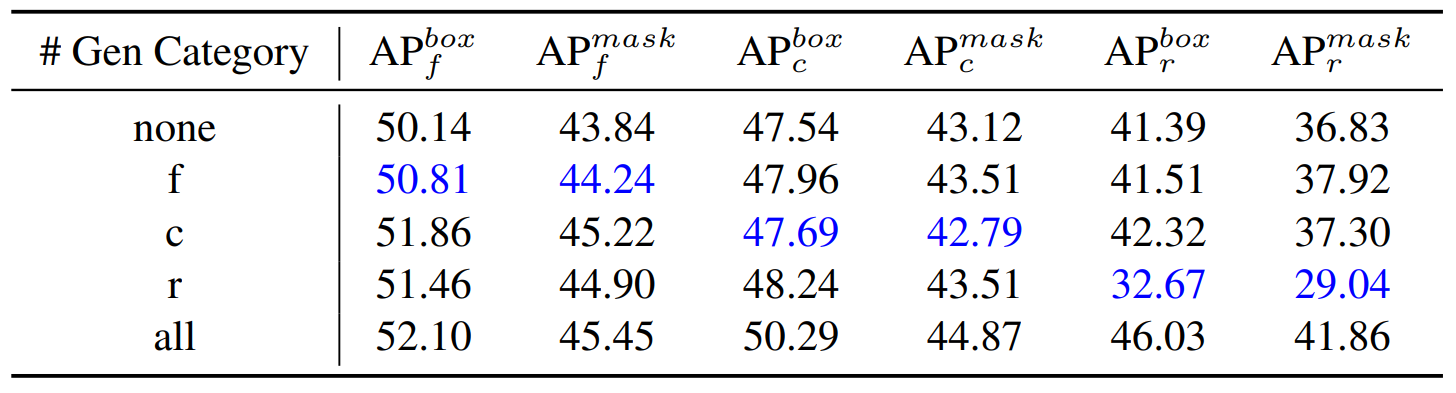
We divide the generative data into ‘frequent’, ‘common’, and ‘rare’ [8] groups, and train three models using each group of data as instance paste source. The inference results are shown in Table 2. We find that the metrics on the corresponding category subset are lowest when training with only one group of data. We consider model performance to be primarily influenced by the quality and diversity of data. Given that the quality of generative data is relatively consistent, we contend insufficient diversity in the data can mislead the distribution that the model can learn and a more comprehensive understanding is obtained by the model from a diverse set of data. Therefore, we believe that using diverse generative data enables models to better adapt to these discrepancies, improving model performance.
3.2. Generative Data Diversity Enhancement
Through the analysis above, we find that the diversity of generative data is crucial for improving model performance. Therefore, we design a series of strategies to enhance data diversity at three levels: category diversity, prompt diversity, and generative model diversity, which help the model to better adapt to the distribution discrepancy between generative data and real data.
Category diversity. The above experiments show that including data from partial categories results in lower performance than incorporating data from all categories. We believe that, akin to human learning, the model can learn features beneficial to the current category from some other categories. Therefore, we consider increasing the diversity of data by adding extra categories. First, we select some extra categories besides LVIS from ImageNet-1K [23] categories based on WordNet [5] similarity. Then, the generative data from LVIS and extra categories are mixed for training, requiring the model to learn to distinguish all categories. Finally, we truncate the parameters in the classification head corresponding to the extra categories during inference, ensuring that the inferred category range remains within LVIS.
Prompt diversity. The output images of the text2image generative model typically rely on the input prompts. Existing methods [34] usually generate prompts by manually designing templates, such as “a photo of a single {category_name}.” When the data scale is small, designing prompts manually is convenient and fast. However, when generating a large scale of data, it is challenging to scale the number of manually designed prompts correspondingly. Intuitively, it is essential to diversify the prompts to enhance data diversity. To easily generate a large number of prompts, we choose large language model, like ChatGPT, to enhance the prompt diversity. We have three requirements for the large language model: 1) each prompt should be as different as possible; 2) each prompt should ensure that there is only one object in the image; 3) prompts should describe different attributes of the category. For example, if the category is food, prompts should cover attributes like color, brand, size, freshness, packaging type, packaging color, etc. Limited by the inference cost of ChatGPT, we use the manually designed prompts as the base and only use ChatGPT to enhance the prompt diversity for a subset of categories. Moreover, we also leverage the controllability of the generative model, adding the constraint “in a white background” after each prompt to make the background of output images simple and clear, which reduces the difficulty of mask annotation.
Generative model diversity. The quality and style of output images vary across generative models, and the data distribution learned solely from one generative model’s data is limited. Therefore, we introduce multiple generative models to enhance the diversity of data, allowing the model to learn from wider data distributions. We selected two commonly used generative models, Stable Diffusion [22] (SD) and DeepFloyd-IF [24] (IF). We use Stable Diffusion V1.5, generating images with a resolution of 512 × 512, and use images output from Stage II of IF with a resolution of 256 × 256. For each category in LVIS, we generated 1k images using two models separately. Examples from different generative models are shown in Figure 2.

3.3. Generative Pipeline
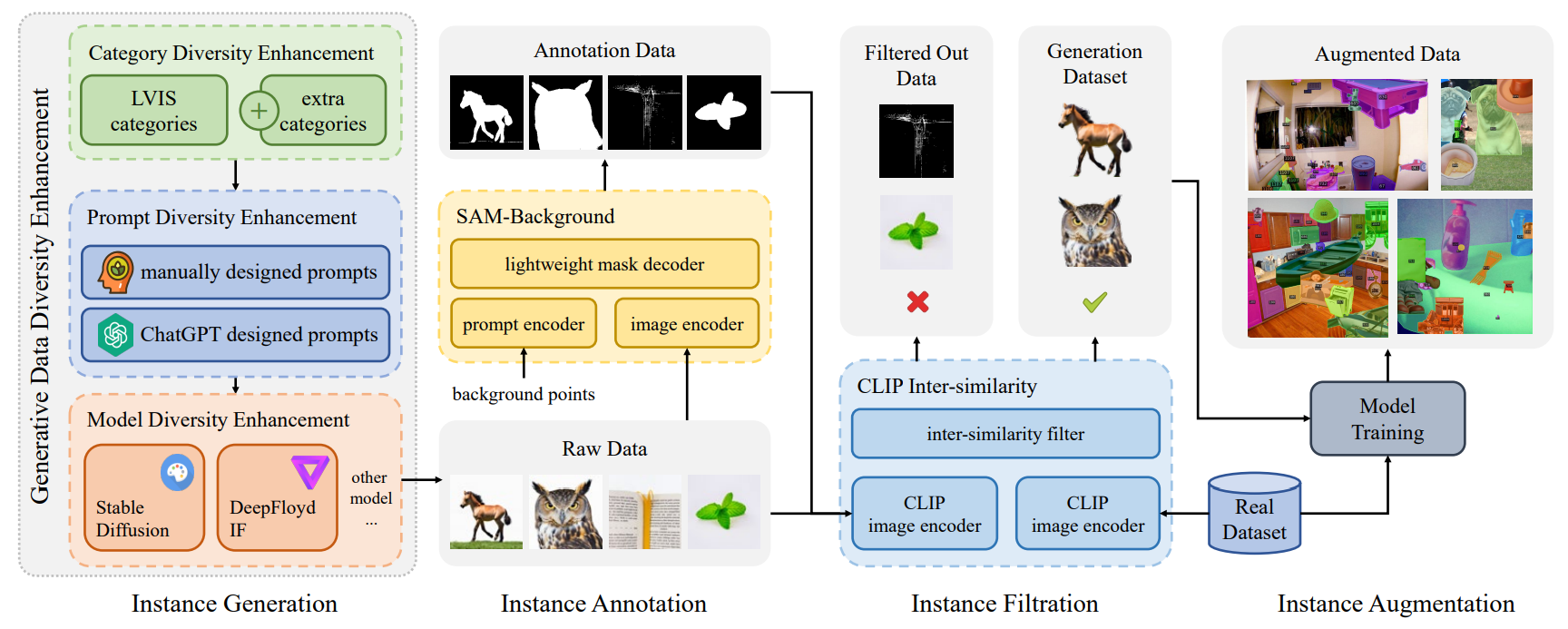
The generative pipeline of DiverGen is built upon XPaste [34]. It can be divided into four stages: instance generation, instance annotation, instance filtration and instance augmentation. The overview of DiverGen is illustrated in Figure 3.
Instance generation. Instance generation is a crucial stage for enhancing data diversity. In this stage, we employ our proposed Generative Data Diversity Enhancement (GDDE), as mentioned in Sec 3.2. In category diversity enhancement, we utilize the category information from LVIS [8] categories and extra categories selected from ImageNet-1K [23]. In prompt diversity enhancement, we utilize manually designed prompts and ChatGPT designed prompts to enhance prompt diversity. In model diversity enhancement, we employ two generative models, SD and IF.
Instance annotation. We employ SAM [12] as our annotation model. SAM is a class-agnostic promptable segmenter that outputs corresponding masks based on input prompts, such as points, boxes, etc. In instance generation, leveraging the controllability of the generative model, the generative images have two characteristics: 1) each image predominantly contains only one foreground object; 2) the background of the images is relatively simple. Therefore, we introduce a SAM-background (SAM-bg) annotation strategy. SAM-bg takes the four corner points of an image as input prompts for SAM to obtain the background mask, then inverts the background mask as the mask of the foreground object. Due to the conditional constraints during the instance generation stage, this strategy is simple but effective in producing high-quality masks.
Instance filtration. In the instance filtration stage, X-Paste utilizes the CLIP score (similarity between images and text) as the metric for image filtering. However, we observe that the CLIP score is ineffective in filtering low-quality images. In contrast to the similarity between images and text, we think the similarity between images can better filter out low-quality images. Therefore, we propose a new metric called CLIP inter-similarity. We use the image encoder of CLIP [21] to extract image embeddings for objects in the training set and generative images, then calculate the similarity between them. If the similarity is too low, it indicates a significant disparity between the generative and real images, suggesting that it is probably a poor-quality image and needs to be filtered.
Instance augmentation. We use the augmentation strategy proposed by X-Paste [34] but do not use the data retrieved from the network or the instances in LVIS [8] training set as the paste data source, only use the generative data as the paste data source.
:::info
Authors:
(1) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(2) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China ([email protected]);
(4) Yang Liu, Zhejiang University, China;
(5) Weijia Wu, Zhejiang University, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Zhejiang University, China ([email protected]).
:::
:::info
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::







{kind=link}