Authors:
(1) Anthi Papadopoulou, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway and Corresponding author ([email protected]);
(2) Pierre Lison, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(3) Mark Anderson, Norwegian Computing Center, Gaustadalleen 23A, 0373 Oslo, Norway;
(4) Lilja Øvrelid, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway;
(5) Ildiko Pilan, Language Technology Group, University of Oslo, Gaustadalleen 23B, 0373 Oslo, Norway.
Table of Links
Abstract and 1 Introduction
2 Background
2.1 Definitions
2.2 NLP Approaches
2.3 Privacy-Preserving Data Publishing
2.4 Differential Privacy
3 Datasets and 3.1 Text Anonymization Benchmark (TAB)
3.2 Wikipedia Biographies
4 Privacy-oriented Entity Recognizer
4.1 Wikidata Properties
4.2 Silver Corpus and Model Fine-tuning
4.3 Evaluation
4.4 Label Disagreement
4.5 MISC Semantic Type
5 Privacy Risk Indicators
5.1 LLM Probabilities
5.2 Span Classification
5.3 Perturbations
5.4 Sequence Labelling and 5.5 Web Search
6 Analysis of Privacy Risk Indicators and 6.1 Evaluation Metrics
6.2 Experimental Results and 6.3 Discussion
6.4 Combination of Risk Indicators
7 Conclusions and Future Work
Declarations
References
Appendices
A. Human properties from Wikidata
B. Training parameters of entity recognizer
C. Label Agreement
D. LLM probabilities: base models
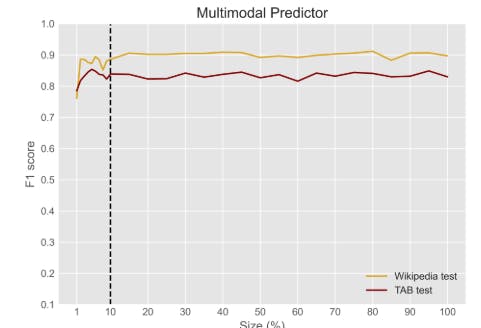
E. Training size and performance
F. Perturbation thresholds
4 Privacy-oriented Entity Recognizer
Identifying PII spans is the first step in text sanitization. Although many methods rely on some variant of NER, they fail to detect PII spans that are not named entities but are nevertheless (quasi-)identifying.
We detail here our approach to detecting text spans expressing personal information. The approach uses knowledge graphs such as Wikidata to create gazetteers for specific PII types. Those gazetteers are then combined with a NER model to create a domain-specific silver corpus, which is in turn employed to fine-tune a neural sequence labelling model. This approach to developing a “privacy-oriented entity recognizer” builds upon earlier work by Papadopoulou et al. (2022), and provides additional details on various aspects of the gazetteer construction process, model training and empirical evaluation.


4.1 Wikidata Properties
NER models are, as the term indicates, focused on named entities. However, many instances of the DEM and MISC[1] categories described in the previous section are not named entities. Examples include someone’s occupation, educational background, part of their physical appearance, the manner of their death or an object that is tied to their identity.
We extract a list of possible values for these two PII categories based on knowledge graphs. In particular, Wikidata[2] is a structured knowledge graph containing information in property-value pairs, with a large number of values being adjectives, nouns, or noun phrases. We operated by retrieving all instances of humans from the Wikidata dump file, and inspecting Wikidata properties[3] to select those that seems to express either DEM or MISC PII based on their description and their examples.
After filtering, we end up with 44 DEM properties and 196 MISC properties. Selected examples of each semantic type are shown Table 2, while a detailed table can be found in Appendix A. Some properties were left out due to the high level of false positives they might have introduced if included (e.g. blood type (P1853)) or because they mostly contained named entities that would already be detected by a generic NER model.
We then use these properties to traverse the Wikidata instances and save all values into two gazetteers, one for DEM entities[4] and one for MISC entities.
4.2 Silver Corpus and Model Fine-tuning
A silver corpus of 5000 documents is then compiled, consisting in our experiments with the datasets of Section 3 of 2500 European Court of Human Rights cases and 2500 Wikipedia summaries (Lebret et al., 2016). To automatically label the documents, we first run a generic NER model5 to detect named entities. We then apply the two DEM and MISC gazetteers and tag each match with their respective label. In case of overlap, we keep the longest span, e.g. keep “Bachelor in Computer Science” instead of “Bachelor” and “Computer Science” as two separate spans.


We then employ this silver corpus to fine-tune a RoBERTa (Liu et al., 2019) model, thus creating a privacy-oriented entity recognizer. Detailed training parameters can be found in Table 10 in Appendix B.
[1] It should be noted that the MISC category employed in this paper does not equate to the MISC category from CoNLL-2003 shared task (Tjong Kim Sang and De Meulder, 2003), which is characterized as a named entity (denoted with a proper name) that is neither a person, organization or place.
[2] https://www.wikidata.org
[3] https://www.wikidata.org/wiki/Wikidata:Database reports/List of properties/all
[4] We also manually add country names and nationalities into the DEM gazetteer to account for cases when the NER failed to detect those and the gazetteer lacked this information.
[5] We used here a RoBERTa model fine-tuned on the Ontonotes v5 corpus using spaCy’s implementation.






{kind=link}