
Your app is ready. You have a backend that does some magical things and then exposes some data through an API. You have a frontend that consumes that API and displays the data to the user. You are using the Fetch API to make requests to your backend, then process the response and update the UI. Simple and straightforward, right?
Well, in development, yes. Then, you deploy your app to production. And strange things start to happen. Most of the time, all seems fine, but sometimes, requests fail. The UI breaks. Users complain. You wonder what went wrong.
The network is unpredictable, and you have to be ready for it. You’d better have answers to these questions: What happens when the network is slow or unreliable? What happens when the backend is down or returns an error? If you consume external API’s, what happens when you hit the rate limit and get blocked? How do you handle these scenarios gracefully and provide a good user experience?
Honestly, vanilla Fetch is not enough to handle these scenarios. You need to add a lot of boilerplate code to handle errors, retries, timeouts, caching, etc. This can quickly become messy and hard to maintain.
In this article, we will explore how to make your fetch requests production-ready using a library called ffetch. We will:
- build a backend with Node.js and Express with some endpoints
- build a frontend that polls those endpoints with vanilla JavaScript using the Fetch API
- make the backend flaky to simulate real-world scenarios
- see how fetch requests can fail and how to handle those failures
- introduce
ffetchto simplify and enhance the fetch request handling
The Boilerplate
We will build the backbones of a simple multi-user task list. The backend will expose RESTful endpoints to create, read, update, and delete users and tasks, and assign tasks to users. The frontend will poll the backend to get the latest data and display it to the user.
Backend
We will use Node.js and Express to build the backend. We will also use a simple in-memory data store to keep things simple. Here are the user and task models:
interface User {
id: number; // Unique identifier
name: string; // Full name
email: string; // Email address
}
export interface Task {
id: number; // Unique identifier
title: string; // Short task title
description?: string; // Optional detailed description
priority: "low" | "medium" | "high"; // Task priority
}
We will create the following endpoints:
GET /users: Get all users (returns an array of user ids)POST /users: Create a new user (returns the created user’s id)GET /users/:id: Get a user by id (returns the user object)PUT /users/:id: Update a user (returns a success message)DELETE /users/:id: Delete a user (returns a success message)GET /tasks: Get all tasks (returns an array of task ids)GET /tasks/:id: Get a task by id (returns the task object)POST /tasks: Create a new task (returns the created task’s id)PUT /tasks/:id: Update a task (returns a success message)DELETE /tasks/:id: Delete a taskGET /users/:userId/tasks: Get all tasks assigned to a user (returns an array of task ids)POST /users/:userId/tasks/:taskId: Assign a task to a user (returns a success message)DELETE /users/:userId/tasks/:taskId: Remove a task from a user (returns a success message)
Frontend
As frameworks usually add their own abstractions and ways of doing things, we will use vanilla TypeScript to keep things simple and framework-agnostic. We will create a SPA with two views: one for the userlist and one for a specific user. The userlist displays the user’s name and the number of tasks assigned to them. Clicking on a user will take you to the user view, which shows the user’s details and their tasks. And from the user view, we can go back to the userlist.
To keep things simple, we will use polling to get the latest data from the backend. Every 3 seconds, we will make requests to the backend to get the latest data for the current view and update the UI accordingly.
For the userlist view, we will make a request to GET /users to get all the user ids, then for each user, we will make a request to GET /users/:id to retrieve their details, and GET /users/:id/tasks to calculate the number of tasks assigned to them.
For the user view, we will make a request to GET /users/:id to get the user’s details, and GET /users/:id/tasks to get the task ids assigned to them. Then for each task id, we will make a request to GET /tasks/:id to retrieve the task details.
The GitHub Repo
You can find the complete code for this example in the accompanying GitHub repo.
Because of the amount of boilerplate, refer to the repo for the complete code. Every stage of the article will reference a branch in the repo.
The repo contains both the backend and frontend code. The backend is in the backend folder, and the frontend is in the frontend folder. When you clone the repo, run npm install in both folders to install the dependencies. Then you can run the backend with npm run dev in the backend folder, and the frontend with npm run dev in the frontend folder. The frontend will be served at http://localhost:5173 and the backend at http://localhost:3000.
Once you have done all the chores and both your backend and frontend are running, you can open your browser and go to http://localhost:5173 to see the app in action:
In Development
If you navigate to http://localhost:5173, you should see everything working just fine. If you add a new user with
curl -X POST http://localhost:3000/users
-H "Content-Type: application/json"
-d '{"name": "John Doe", "email": "[email protected]"}'
you should see the user appear in the userlist view within 3 seconds. Feel free to play around with the app and add more users and tasks. Most likely, everything will work just fine.
Well, this is where we finally arrive at the point of this article. Our backend works just fine. Our frontend, despite the horrible boilerplate, also works just fine. But between the frontend and backend, there is the network. And the network is unreliable. So, let’s see what happens if we add a bit of flakiness to our backend.
Simulating Network Errors
Let’s add a middleware to our backend that randomly fails requests with a 20% chance and also adds some random delay up to 1 second. This will simulate network errors and help us test how our frontend handles them.
You can find the flaky middleware in the backend/src/middleware/flaky.ts file. Here is the code:
import { Request, Response, NextFunction } from 'express';
export function flaky(req: Request, res: Response, next: NextFunction) {
// Randomly fail requests with a 20% chance
if (Math.random() < 0.2) {
return res.status(500).json({ error: 'Random failure' });
}
// Add random delay up to 2 seconds
const delay = Math.random() * 2000;
setTimeout(next, delay);
}
Then, we can use this middleware in our Express app. You can find the code in the backend/src/index.ts file. Just import the middleware and use it before your routes:
...
import { flaky } from './middleware/flaky';
...
app.use(cors());
app.use(express.json());
app.use(flaky); // Use the flaky middleware
This code is in the network-errors branch of the repo, so you can check it out with git checkout network-errors.
Now, if you restart your backend and refresh the frontend, you should start seeing some weird things. The console will be filled with errors. Some fields on the UI will be undefined. Things start to fall apart. And this is when, if you haven’t already, you need to start thinking about how to handle these errors gracefully.
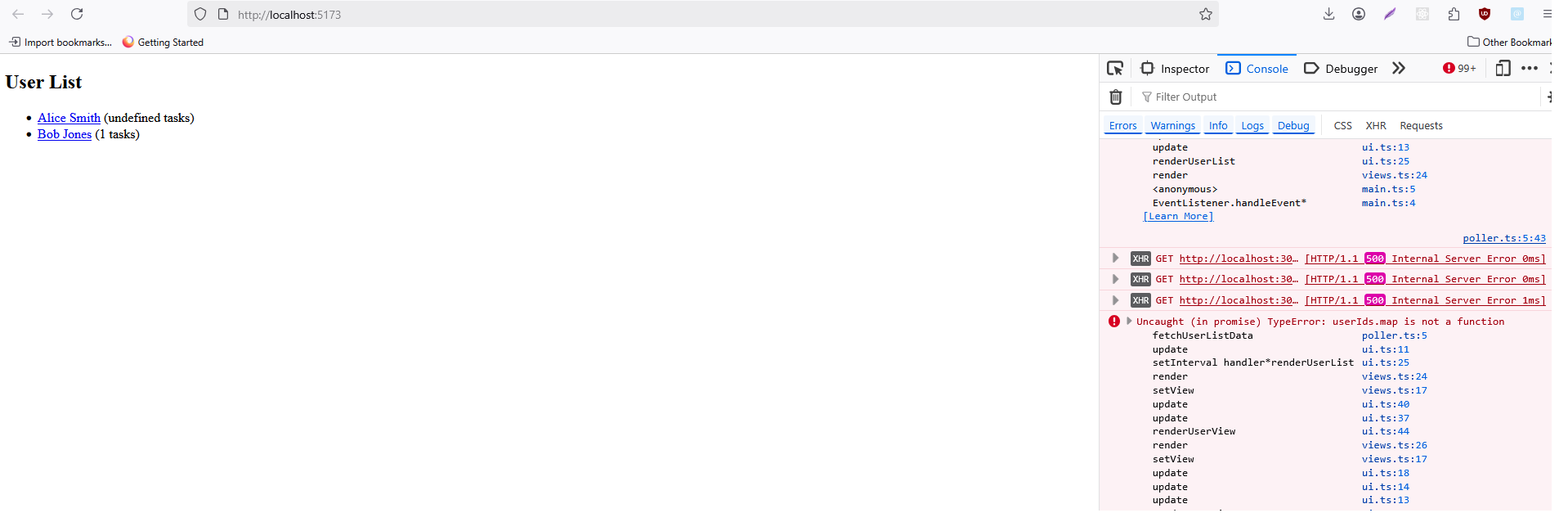
Error Scenarios
First of all, let’s identify what can go wrong and how we can handle it:
- Intermittent network failures: requests can fail randomly, so on certain errors, we need to retry them a few times before giving up.
- When polling, we’re not sending just one request, but multiple requests asynchronously. And 3 seconds later, we send another batch of requests. If a request from the previous batch is still pending when the next batch is sent, we might get an earlier response after a later one. This can lead to an inconsistent UI state. We need to make sure that only the latest response is used to update the UI, so when a new polling cycle starts, we need to cancel any pending requests from the previous cycle.
- Similarly, if the user navigates to a different view while requests from the previous view are still pending, we might get responses for the previous view after we’ve already navigated away. This can also lead to an inconsistent UI state. We need to make sure that only responses for the current view are used to update the UI, so when navigating to a different view, we need to cancel any pending requests from the previous view.
- If a request was successful at some point, but then fails in a subsequent polling cycle, we don’t want to immediately show an error state to the user. We can cache successful responses so users don’t notice every little hiccup in the network.
- We have to handle scenarios where, say, we’re viewing a user that has been deleted in the backend. We need to handle 404 errors gracefully and navigate back to the userlist view, or at least show a not found message.
- Also, we need to handle scenarios where the backend is completely down or unreachable. We need to show a global error message to the user and maybe retry the requests after some time.
- And the list goes on, especially if the UI allows creating, updating, or deleting data. But for now, let’s focus on the read operations and how to handle errors when fetching data.
Handling Errors With Vanilla Fetch
Here, as with many things in JavaScript (or TypeScript), you have two options to handle these scenarios. You can write your own utility functions to wrap the Fetch API and add the necessary error handling logic, or you can pick a library that does this for you.
Let’s start with implementing everything ourselves. The code is on the native-fetch branch of the repo, so you can check it out with git checkout native-fetch.
What Needs to Be Done
- Centralize all fetch logic in
poller.ts. - For each poll, create a new
AbortController, and cancel the previous one. - Wrap fetch calls in a retry-and-timeout function.
- On success, update a cache and use it for rendering.
- On failure, retry as needed, and handle timeouts/cancellations gracefully.
Our poller.ts file now looks like this:
// Cache for responses
const cache: Record<string, any> = {};
// AbortController for cancelling requests
let currentController: AbortController | undefined;
// Helper: fetch with retries and timeout
async function fetchWithRetry(url: string, options: RequestInit = {}, retries = 2, timeout = 3000): Promise<any> {
for (let attempt = 0; attempt <= retries; attempt++) {
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), timeout);
try {
const res = await fetch(url, { ...options, signal: controller.signal });
clearTimeout(timer);
if (!res.ok) throw new Error(`HTTP ${res.status}`);
const data = await res.json();
return data;
} catch (err) {
clearTimeout(timer);
if (attempt === retries) throw err;
}
}
}
// Cancel all previous requests
function cancelRequests() {
if (currentController) currentController.abort();
currentController = new AbortController();
}
export async function fetchUserListData() {
cancelRequests();
// Use cache if available
if (cache.userList) return cache.userList;
try {
if (!currentController) throw new Error('AbortController not initialized');
const userIds = await fetchWithRetry('http://localhost:3000/users', { signal: currentController!.signal });
const users = await Promise.all(userIds.map((id: number) => fetchWithRetry(`http://localhost:3000/users/${id}`, { signal: currentController!.signal })));
const taskCounts = await Promise.all(userIds.map((id: number) => fetchWithRetry(`http://localhost:3000/users/${id}/tasks`, { signal: currentController!.signal }).then((tasks: any[]) => tasks.length)));
cache.userList = { users, taskCounts };
return cache.userList;
} catch (err) {
// fallback to cache if available
if (cache.userList) return cache.userList;
throw err;
}
}
export async function fetchUserDetailsData(userId: number) {
cancelRequests();
const cacheKey = `userDetails_${userId}`;
if (cache[cacheKey]) return cache[cacheKey];
try {
if (!currentController) throw new Error('AbortController not initialized');
const user = await fetchWithRetry(`http://localhost:3000/users/${userId}`, { signal: currentController!.signal });
const taskIds = await fetchWithRetry(`http://localhost:3000/users/${userId}/tasks`, { signal: currentController!.signal });
const tasks = await Promise.all(taskIds.map((id: number) => fetchWithRetry(`http://localhost:3000/tasks/${id}`, { signal: currentController!.signal })));
cache[cacheKey] = { user, tasks };
return cache[cacheKey];
} catch (err) {
if (cache[cacheKey]) return cache[cacheKey];
throw err;
}
}
We deleted api.ts as all fetch logic is now in poller.ts. In our simplified use case, it’s bearable, but even here, we needed to add a lot of boilerplate code to handle errors, retries, timeouts, cancellations, and caching. And this is just for read operations. Imagine how much more code you would need to handle create, update, and delete users, tasks, and assignments.
If you run the app now, you should see that it works much better. The UI is more stable and doesn’t break as often. You can still see some errors in the console, but they are handled gracefully and don’t affect the user experience as much.
Downsides of This Approach
- More boilerplate code: We had to write a lot of code to handle errors, retries, timeouts, cancellations, and caching. This can quickly become messy and hard to maintain.
- Not very reusable: The code is tightly coupled to our specific use case and not very reusable for other projects or scenarios.
- Limited features: The code only handles basic error scenarios. More complex scenarios like exponential backoff, circuit breakers, or global error handling would require even more code.
Using ffetch for Better Fetch Handling
To address the downsides of our custom fetch handling, I wrote a library called ffetch. It is a small and lightweight library that wraps the Fetch API and provides a simple and declarative way to handle errors, retries, timeouts, cancellations, and some more features.
Let’s rewrite our fetch logic using ffetch. You can find the code on the ffetch branch of the repo, so you can check it out with git checkout ffetch.
First, install ffetch in the frontend folder:
npm install @gkoos/ffetch
Then, we can rewrite our poller.ts file using ffetch:
import createClient from '@gkoos/ffetch';
// Cache for responses
const cache: Record<string, any> = {};
// Create ffetch client
const api = createClient({
timeout: 3000,
retries: 2,
});
function cancelRequests() {
api.abortAll();
}
export async function fetchUserListData() {
cancelRequests();
if (cache.userList) return cache.userList;
try {
const userIds = await api('http://localhost:3000/users').then(r => r.json());
const users = await Promise.all(
userIds.map((id: number) => api(`http://localhost:3000/users/${id}`).then(r => r.json()))
);
const taskCounts = await Promise.all(
userIds.map((id: number) => api(`http://localhost:3000/users/${id}/tasks`).then(r => r.json()).then((tasks: any[]) => tasks.length))
);
cache.userList = { users, taskCounts };
return cache.userList;
} catch (err) {
if (cache.userList) return cache.userList;
throw err;
}
}
export async function fetchUserDetailsData(userId: number) {
cancelRequests();
const cacheKey = `userDetails_${userId}`;
if (cache[cacheKey]) return cache[cacheKey];
try {
const user = await api(`http://localhost:3000/users/${userId}`).then(r => r.json());
const taskIds = await api(`http://localhost:3000/users/${userId}/tasks`).then(r => r.json());
const tasks = await Promise.all(
taskIds.map((id: number) => api(`http://localhost:3000/tasks/${id}`).then(r => r.json()))
);
cache[cacheKey] = { user, tasks };
return cache[cacheKey];
} catch (err) {
if (cache[cacheKey]) return cache[cacheKey];
throw err;
}
}
The code is much cleaner and easier to read. We don’t have to worry about retries, timeouts, or cancellations anymore. ffetch takes care of that for us. We just create a client with the desired options and use it to make requests.
Other Benefits of Using ffetch
- Circuit breaker: automatic endpoint cooldown after repeated failures
- Automatic exponential backoff for retries: increasing wait times between retries
- Global error handling: hooks for logging, modifying requests/responses, etc.
- We can fine-tune which failures should trigger a retry, and which should not. For example, we can choose to retry on network errors and 5xx server errors, but not on 4xx client errors.
ffetch doesn’t do anything magical you couldn’t build yourself, but it saves you from writing, testing, and maintaining all that boilerplate. It’s a convenience wrapper that bakes in production-grade patterns (like circuit breaker and backoff) so you can focus on your app, not your fetch logic. It also stops at the fetch layer, so you can still use your own caching, state management, and UI libraries as you see fit.
Conclusion
The main takeaway of this article is not that you should use ffetch specifically, but that you should not rely on vanilla Fetch for production-ready applications. The network is unreliable, and you need to be prepared for it. You need to handle errors, retries, timeouts, cancellations, and caching gracefully to provide a good user experience.
What you exactly need to do depends on your specific use case and requirements, but you can’t go to production handling the happy path only. Things can and will go wrong, and your app needs to handle at least the most common failure scenarios. And ffetch can help with that.







{kind=link}