
Table of Links
Abstract and 1. Introduction
-
Related work
-
Method
3.1. Uniform quantizer
3.2. IGQ-ViT
3.3. Group size allocation
-
Experiments
4.1. Implementation details and 4.2. Results
4.3. Discussion
-
Conclusion, Acknowledgements, and References
Supplementary Material
A. More implementation details
B. Compatibility with existing hardwares
C. Latency on practical devices
D. Application to DETR
A. More implementation details
A.1. Weight quantization
For weight quantization, we exploit a distinct quantizer for each output channel, following [21]. We designate the upper and lower bounds of weight quantizers with (100-ϵ)- th and ϵ-th percentiles of weight values in each output channel, where ϵ is a hyperparameter.
A.2. Hyperparameter settings
A.3. Perturbation metric for Mask R-CNN models

For Mask R-CNN and Cascade Mask R-CNN models, we modify the perturbation metric for each RoI in Eq. (9) as follows:

![Figure A. Our instance-aware group quantization framework could be implemented using existing DNN accelerators, with a slight modification from the implementation of [7]. One might leverage a group assignment module that computes the group indices for each channel using Eq. (5), and the resulting indices are used to select channels that belong to each group during matrix multiplication. Corresponding rows of weight buffers are also selected.](https://cdn.hackernoon.com/images/null-x23338p.png)
B. Compatibility with existing hardwares
We believe that IGQ-ViT could be efficiently implemented using existing neural network accelerators, with a slight modification from the implementation of VSquant [7]. Specifically, [7] divides channels of activations into a number of groups, and activation values assigned to each group are processed with separate multiplyaccumulate (MAC) units. The outputs from each MAC unit are then scaled with different quantization parameters. In contrast, IGQ-ViT dynamically splits channels according to their statistical properties for each input instance. Compared to [7], IGQ-ViT requires additional computations, which includes computing the min/max values of each channel, and assigning channels to quantizers with the minimum distance. To address this, one might leverage a group assignment module that computes the min/max values of each channel, followed by obtaining group indices using Eq. (5) (Fig. A). The resulting indices are then used to select channels that belong to each group. Finally, a separate MAC unit is applied for activation values within each group, which contains a single quantization parameter. Note that computing the group indices for each channel is computationally cheap in terms of BOPs (See Table 1 in the main paper), and using an indexing scheme for efficient computation is a common practice in real devices. For example, the work of [41] implements a module providing indices to dynamically detect sparsity patterns of weight and activation values in each group. It then uses the indices to skip groups of zero-valued weights and activations for efficiency (See Fig. 15.2.3 in [41]).
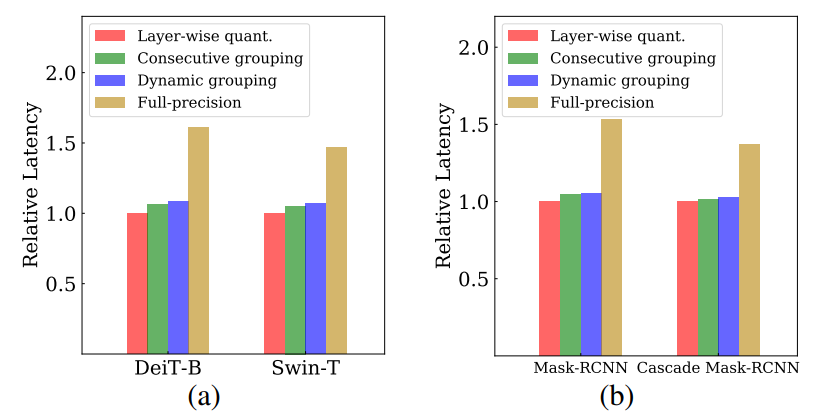
C. Latency on practical devices
To further validate the efficiency of IGQ-ViT, we conduct a simulation in PyTorch to compare the latencies between prior group quantization techniques [4, 7, 32] and ours. A key challenge is that most quantization methods exploit a fake quantization approach, following [20], which mimics the quantization process by discretizing the network’s weights and activations into a finite set of floating-point values, thereby serving a surrogate for the true quantization process. This approach is inappropriate for estimating the latency on real hardwares as it does not change the actual precision of the data, but merely introduces the concept of lower precision during calibration. Accordingly, we directly convert the data formats of weights and activations into 8-bit representations to measure the latency more accurately. Specifically, we simulate IGQ-ViT for linear operations using Eq. (7), which requires low-bit matrix multiplication between weights and activations within each group, along with the summation of outputs for each group in full-precision. Since PyTorch does not support convolutional or linear layers that takes low-bit matrices as input, we have implemented their 8-bit counterparts. Note that we have implemented the group assignment algorithm (i.e., Eq. (5)) in full-precision.
We compare in Fig. B the run-time latency of IGQViT with its variants. We can see that IGQ-ViT introduces marginal overhead compared to layer-wise quantization, and consecutive grouping strategy, while achieving high quantization performances (See Table 5 in the main paper). This suggests that dynamic grouping of channels have a limited impact on actual latency.
D. Application to DETR
We show in Table A the results of quantizing a DETR model with a ResNet-50 [13] backbone on COCO [22]. To the best of our knowledge, PTQ for ViT [26] is the only PTQ method that provides quantization results for a DETR
![Table A. Results of quantizing a DETR model with a ResNet50 [13] backbone on COCO [22].](https://cdn.hackernoon.com/images/null-58032c8.png)
model under 6/6-bit setting. We can see that IGQ-ViT outperforms it by 0.8% for a group size of 12.
:::info
Authors:
(1) Jaehyeon Moon, Yonsei University and Articron;
(2) Dohyung Kim, Yonsei University;
(3) Junyong Cheon, Yonsei University;
(4) Bumsub Ham, a Corresponding Author from Yonsei University.
:::
:::info
This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license
:::







{kind=link}