:::info
Authors:
(1) Yosuke Kaga, Hitachi, Ltd., Japan;
(2) Yusei Suzuki, Hitachi, Ltd., Japan;
(3) Kenta Takahashi, Hitachi, Ltd., Japan.
:::
Table of Links
Abstract and I. Introduction
II. Related Work
III. IPFED
IV. Experiments
[V. Conclusion and References]()
III. IPFE
We propose a new method to solve the privacy and accuracy problems described in Sec.II. We call our proposed method Identity Protected Federated Learning (IPFed). The overview of IPFed and the training algorithm of IPFed are shown in Fig.2 and Algorithm 1, respectively
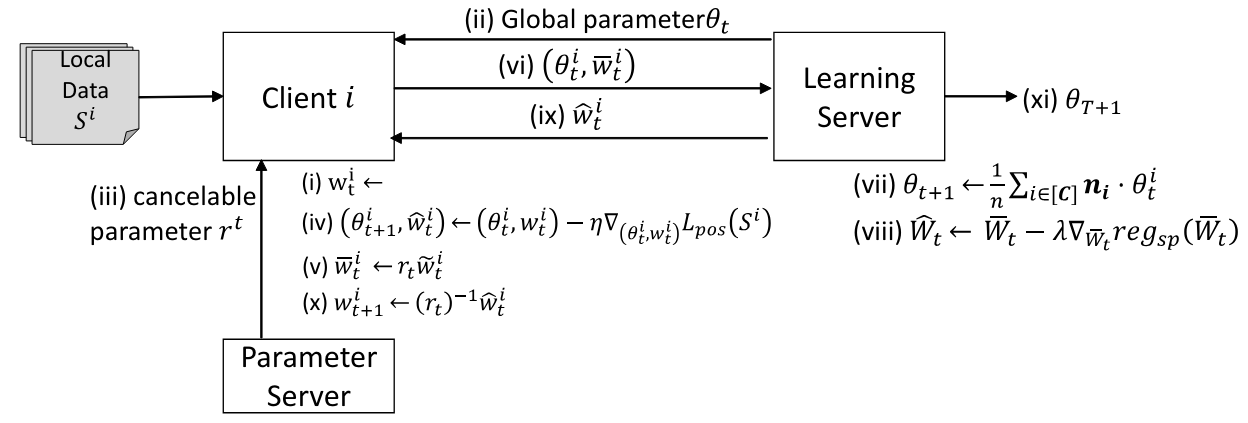
In IPFed, the class embedding is multiplied by a random transformation parameter which is secret to the learning server. Furthermore, the updated class embedding is returned to the original feature space using the inverse matrix of the transformation parameters. This makes it possible to perform the optimization while keeping the class embeddings secret from any server. In the following, we show in Section III-A that our method can perform the same optimization as FedFace even when the class embedding is kept secret, and we also show in Section III-B that it is difficult for an attacker on any entity to obtain the user’s personal data.
A. Derivation of IPFed




B. Privacy analysis of IPFed
In this section, we discuss how privacy protection is achieved by our IPFed. We assume that an attacker against IPFed can obtain the data stored or communicated on any one of the three entities. We also assume a semi-honest model in which each entity follows correct protocols. We also assume that the goal of the attack is to obtain personal data of a specific individual.

Attacker against the parameter server: From the parameter server, the attacker can obtain the transformation parameter rt. Since the transformation parameter is randomly generated data independent of the personal data, it is difficult to obtain any personal data.

In conclusion, we have confirmed that IPFed can strongly protect the privacy of training data under the assumptions defined in this paper.
C. Efficiency analysis of IPFed

Note that the parameter server is a newly introduced and its operating costs are newly incurred. However, since the role of the parameter server is only to generate and send the transformation parameter, there is no problem even if the server has very little computing power.
From the above discussion, it can be said that the efficiency of IPFed is comparable to that of the conventional method [6]. However, quantitative evaluation of the efficiency of IPFed is a future work.
IV. EXPERIMENTS
In this chapter, we show the effectiveness of the proposed method through experiments on face image datasets.
A. Setting
Datasets: We follow the setting in [6] and used CASIAWebFace [14] for training. CASIA-WebFace consists of 494,414 images of 10,575 subjects. We randomly select 9,000 subjects for pre-training and 1,000 subjects for federated learning. To evaluate the performance of face verification, we use three datasets: LFW [15], IJB-A [16] and IJB-C [17].
Implementation: We use CosFace [18] for the face feature extractor. Only CosFace was used as the face feature extractor according to [6], but evaluation using more recent multiple the face feature extractors is a subject for future work. We use the scale parameter of 30 and the margin parameter of 10 for the CosFace loss function. The margin parameters are m = 0.9 and v = 0.7. The parameter λ = 25 in Eq.(3). We perform federated learning with a communication round of 200 and a learning rate of 0.1.
B. Evaluation
First, the face verification performance of each method for 1000 clients is shown in the Table.I. The comparison methods are shown below:

Baseline A typical CosFace model, pre-trained on 9000 subjects.
Fine-tuning A fine-tuned model of Baseline using CosFace on 1000 subjects.
FedFace A model trained according to [6].
IPFed A model trained based on the proposed random projection approach.
Fixed class embedding (FCE) A model trained by fixing the class embedding to the initial data. In FCE, the class embedding does not need to be shared with the server, and secure federated learning can be performed.
As shown in Table.I, IPFed achieves the same level of accuracy as FedFace. This means that the random projection based spreadout in IPFed is equivalent to the spreadout in FedFace. On the other hand, FCE is less accurate than IPFed. This is due to the lack of class embedding optimization, which means that the spreadout in IPFed contributes to the accuracy improvement.
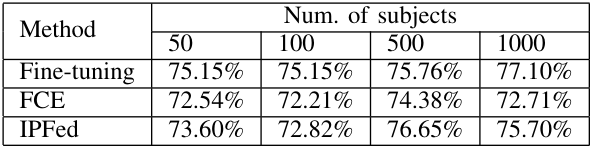
Furthermore, the accuracy against the number of subjects used for federated learning is shown in TableII. The IPFed achieves higher accuracy than the FCE for any of the number of the subjects. This indicates that sharing and optimizing class embedding improve the accuracy. However, while Fine-tuning has a monotonic increase in accuracy for the number of the subjects, IPFed does not. This may be due to the fact that the hyperparameters in learning are not optimal for the number of the subjects, so automatic adjustment of hyperparameters is a future task.
In addition, in our experiments, only accuracy was evaluated, and attack defense performance was only theoretically evaluated. This is also a topic for future work.
V. CONCLUSION
In this paper, we focused on the problem of personal data leakage from class embedding in federated learning for user authentication, and proposed IPFed, which performs federated learning while protecting class embedding. We proved that IPFed, which is based on random projection for class embedding, can perform learning equivalent to the state-of-theart method. We evaluate the proposed method on face image datasets and confirm that the accuracy of IPFed is equivalent to that of the state-of-the-art method. IPFed can improve the model for user authentication while preserving the privacy of the training data.
REFERENCES
[1] I. D. Raji and G. Fried, About face: A survey of facial recognition evaluation, 2021. arXiv: 2102.00813 [cs.CV].
[2] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer International Publishing, vol. 10, p. 3 152 676, 2017.
[3] M. Al-Rubaie and J. M. Chang, “Privacy-preserving machine learning: Threats and solutions,” IEEE Security Privacy, vol. 17, no. 2, pp. 49–58, 2019. DOI: 10.1109/MSEC.2018.2888775.
[4] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Artificial intelligence and statistics, PMLR, 2017, pp. 1273–1282.
[5] F. Yu, A. S. Rawat, A. Menon, and S. Kumar, “Federated learning with only positive labels,” in International Conference on Machine Learning, PMLR, 2020, pp. 10 946–10 956.
[6] D. Aggarwal, J. Zhou, and A. K. Jain, “Fedface: Collaborative learning of face recognition model,” in 2021 IEEE International Joint Conference on Biometrics (IJCB), 2021, pp. 1–8. DOI: 10.1109/IJCB52358.2021.9484386.
[7] H. Hosseini, S. Yun, H. Park, C. Louizos, J. Soriaga, and M. Welling, Federated learning of user authentication models, 2020. arXiv: 2007.04618 [cs.LG].
[8] H. Hosseini, H. Park, S. Yun, C. Louizos, J. Soriaga, and M. Welling, “Federated learning of user verification models without sharing embeddings,” in Proceedings of the 38th International Conference on Machine Learning, M. Meila and T. Zhang, Eds., ser. Proceedings of Machine Learning Research, vol. 139, PMLR, 18–24 Jul 2021, pp. 4328–4336. [Online]. Available: https://proceedings.mlr.press/v139/hosseini21a.html.
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::







{kind=link}