Table of Links
-
Introduction
-
Related Work
2.1 Semantic Typographic Logo Design
2.2 Generative Model for Computational Design
2.3 Graphic Design Authoring Tool
-
Formative Study
3.1 General Workflow and Challenges
3.2 Concerns in Generative Model Involvement
3.3 Design Space of Semantic Typography Work
-
Design Consideration
-
Typedance and 5.1 Ideation
5.2 Selection
5.3 Generation
5.4 Evaluation
5.5 Iteration
-
Interface Walkthrough and 6.1 Pre-generation stage
6.2 Generation stage
6.3 Post-generation stage
-
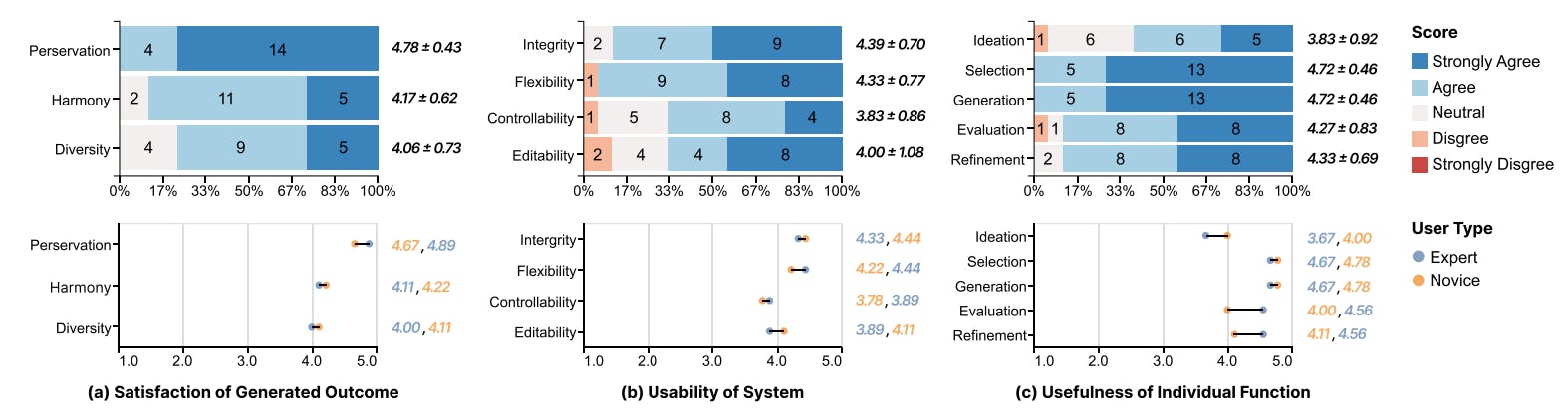
Evaluation and 7.1 Baseline Comparison
7.2 User Study
7.3 Results Analysis
7.4 Limitation
-
Discussion
8.1 Personalized Design: Intent-aware Collaboration with AI
8.2 Incorporating Design Knowledge into Creativity Support Tools
8.3 Mix-User Oriented Design Workflow
-
Conclusion and References
5.3 Generation
5.3.1 Input Generation. This section describes the three inputs required for the generation process. The first input is the selected typeface 𝐼𝑡 , which serves as the origin image for the diffusion model. The second input is the optional user’s prompt 𝑇𝑝 , which allows them to explicitly express their intent, such as the specific style they desire. The third input consists of the design factors extracted from the selected image 𝐼𝑖 .
Semantics. Textual prompt is an accessible and intuitive medium for creators to instruct AI, which also offers a way to incorporate imagery into the generation process. However, it is laborious to describe a significant amount of information within the constraints of a limited prompt length. TypeDance solves this problem by automatically extracting the description of the selected imagery. Describing the selected imagery involves a text inversion process encompassing multiple concrete semantics dimensions. One of the prominent semantics is the general visual understanding of a scene. For instance, in Fig. 4, the description of the scene is “a yellow vase with pink flowers.” We capture this explicit visual information (object, layout, etc.) using BLIP [29], a Vision-Language model that excels in image captioning tasks. Moreover, the style of imagery, especially when it comes to illustrations or paintings, can greatly influence its representation and serve as a common source of inspiration for creators. The style of the case in Fig. 4 is “still life photo studio in style of simplified realism.” Such a specific style is derived from retrieving relevant descriptions with high similarity in a huge prompt database. Therefore, the complete semantics of the imagery include the scene and style. To enhance interface scalability, we extract keywords from the detailed semantics. Creators can still access the complete version by hovering over the keywords.
Color. TypeDance utilizes kNN clustering [16] to extract five primary colors from the selected imagery. These color specifications are then applied in the subsequent generation process. In order to preserve the semantic colorization relation, the extracted colors are transformed into a 2D palette that includes spatial information. This ensures that the generated output maintains a meaningful and coherent color composition.
Shape. The shape of the typeface can take an aesthetic distortion to incorporate rich imagery, as demonstrated in our formative study. To achieve this, we first leveraged edge detection to recognize the contour of selected imagery. Then, we sample 20 equidistant points along the contour. These points are used to deform the outline of the typeface iteratively, using generalized Barycentric coordinates [33]. The deformation occurs in the vector space, resulting in a modified shape that depicts coarse imagery and facilitates guided generation.
These design factors are applied independently during the generation process. Creators have the flexibility to combine these factors according to their specific needs, allowing for the creation of diverse and personalized designs.
5.3.2 Output Discrimination. To ensure that the generated result aligns with the creators’ intent, TypeDance employs a strategy that filters good results based on three scores. As illustrated in Fig. 4, we aim for the generated result 𝐼𝑔 to achieve a relatively balanced score in the triangles composed of typeface, imagery, and the optional user prompt. The typeface score 𝑠1 is determined by comparing the saliency maps of the selected typeface and the generated result. Saliency maps are grayscale images that highlight visually salient objects in an image while neglecting other redundant information. We extract the saliency maps for the typeface and the generated result and then compare their similarity pixel-wise. The imagery score 𝑠2 is derived from the cosine similarity between the image embeddings of the input image 𝐼𝑖 and the generated result 𝐼𝑔. Similarly, we obtain the prompt score 𝑠3 by computing the cosine similarity between the image embedding of the generated result 𝐼𝑔 and the text embedding of the user prompt 𝑇𝑝 . We use the pre-trained CLIP model to obtain the image and text embeddings because of its aligned multi-modal space. We denote 𝑠𝑖 = {𝑠𝑖1, 𝑠𝑖2, 𝑠𝑖3}, where 𝑖 represents the 𝑖-th result at one round of generation. To filter the results that mostly align with the creators’ intent, we use a multi-objective function that maximizes the sum of the scores and minimizes the variance between them. The function is defined as follows:


where S is the score set of all generated results, and 𝜎(S) calculates the variance of the scores. The 𝜆 is a weighting factor used to balance the total score and variance, which is empirically set as 0.5. Based on this criteria, TypeDance displays the top 1 result on the interface each round and regenerates to obtain a total of four results.
Authors:
(1) SHISHI XIAO, The Hong Kong University of Science and Technology (Guangzhou), China;
(2) LIANGWEI WANG, The Hong Kong University of Science and Technology (Guangzhou), China;
(3) XIAOJUAN MA, The Hong Kong University of Science and Technology, China;
(4) WEI ZENG, The Hong Kong University of Science and Technology (Guangzhou), China.
This paper is






{kind=link}