
How we designed Swarm, our in-house load-testing framework, to handle the challenges of end-to-end testing, custom protocols, and large-scale bot simulations in gamedev.
These days, it’s really hard to imagine a software product without at least some level of testing. Unit tests are a standard way to catch bugs in small pieces of code, while end-to-end tests cover entire application workflows. GameDev is no exception, but it comes with its own unique challenges that don’t always align with how we usually test web applications. This article is about the path we took to fulfil those unique needs with our own internal testing tool.
Hi, I’m Andrey Rakhubov, a Lead Software Engineer at MY.GAMES! In this post, I’ll share details about the backend used in our studio, and our approach to load testing the meta-game in War Robots: Frontiers.
A Note on Our Architecture
Without going into any unnecessary details, our backend consists of a set of classic services and a cluster of interconnected nodes where the actors live.

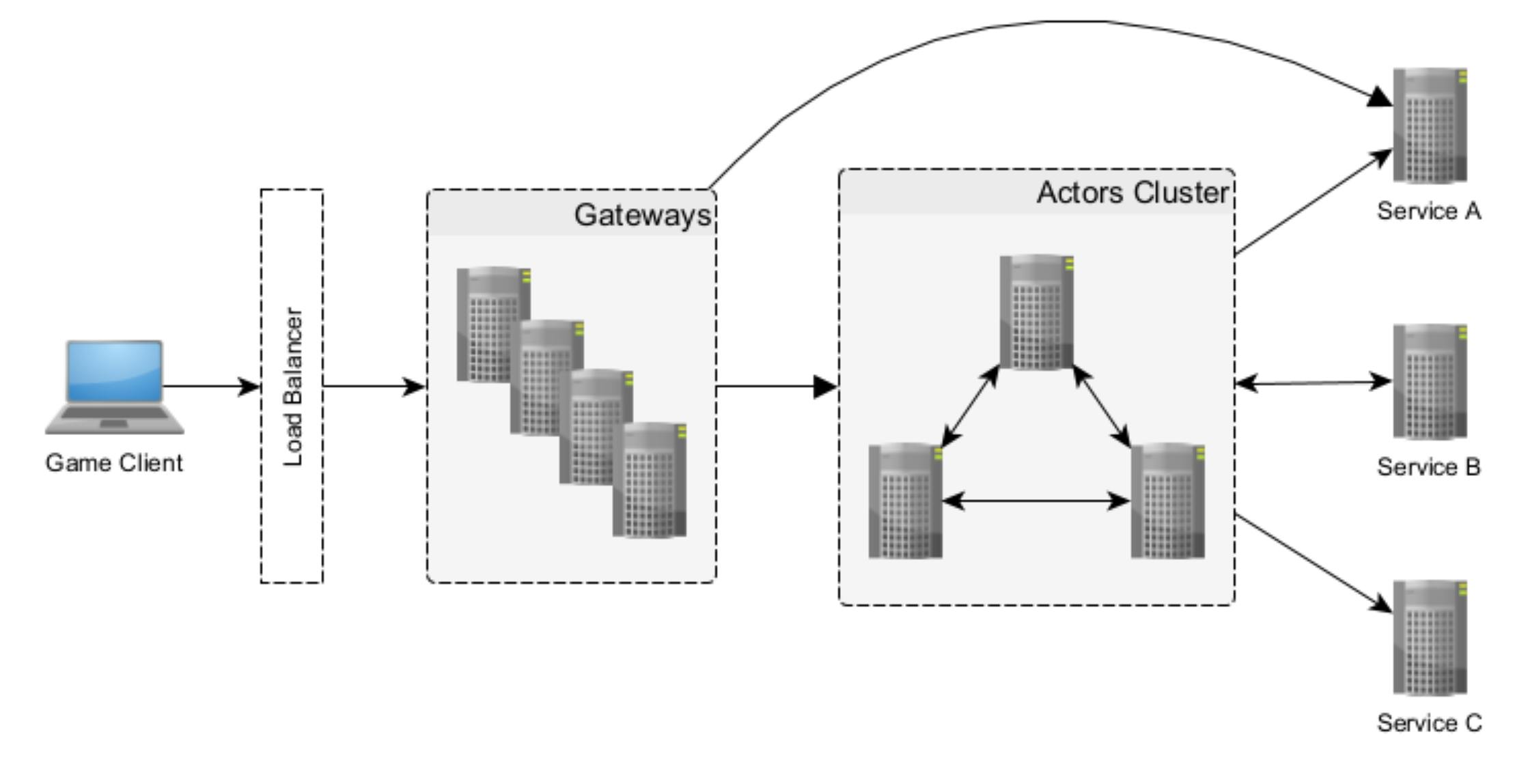
Despite some other shortcomings that may exist, this approach has proven to be quite good at solving one of the most bothersome problems in game development: iteration speed. You may remember that during the early days of Rust-lang development there was a joke that documentation would change as you were reading it. Well, we have the same saying about the GDD (game design document).
Actors help in a way that they are very cheap to implement and modify at the early stages of feature design and they are pretty straightforward to refactor as a separate service if the need later arises.
Obviously, this complicates load and integration testing, since you no longer have a clear separation of services with small, well-defined APIs. Instead, there is a cluster of heterogeneous nodes, where there are much less obvious or controllable connections between the actors.
Testing
As you might guess, unit testing for actors and services (and load/integration testing for services) is no different from what you’d find in any other type of software. The differences appear in:
- Load and integration testing actors
- End-to-end and load backend testing
We won’t look at testing actors in detail here since it’s not specific to GameDev, but relates to the actor model itself. The usual approach is to have a special single-node cluster that’s suitable to be wired up in memory inside a single test and that’s also able to stub all outgoing requests and invoke the actors API. We use the same approach.
That said, things start to get more interesting when we come up to load or end-to-end testing – and this is where our story begins.
So, in our case, the client application is the game itself. The game uses Unreal Engine, so the code is written in C++, and on the server we use C#. Players interact with UI elements in the game, producing requests to the backend (or requests are made indirectly).
At this point, the vast majority of frameworks just stop working for us, and any kind of selenium-like kits that consider client applications a browser are out of scope.
The next issue is that we use a custom communication protocol between the client and backend. This part really deserves a separate article altogether, but I will highlight the key concepts:
- Communication happens via a WebSocket connection
- It’s schema-first; we use Protobuf to define message and services structure
- WebSocket messages are Protobuf messages wrapped into a container with metadata that mimics some necessary gRPC-related info, like URL and headers
So, any tool that doesn’t allow defining custom protocols is not suitable for the task.
At the same time, we wanted to have a single tool that could write both REST/gRPC load tests and end-to-end tests with our custom protocol. After considering all requirements that were discussed in Testing and some preliminary discussions, we were left with these candidates:
Each one of them had their pros and cons, but there were several things none of them could solve without huge (sometimes internal) changes:
- First, there was a need related to inter-bot communication for synchronization purposes, as discussed earlier.
- Second, clients are quite reactive and their state could change without explicit action from the test scenario; this leads to extra synchronization and the need to jump through a lot of hoops in your code.
- Last but not least, those tools were too narrowly focused on performance testing, offering numerous features for gradually increasing load or specifying time intervals, yet lacking the ability to create complex branched scenarios in a straightforward manner.
It was time to accept the fact that we really needed a specialised tool. That is how our tool – Swarm – was born.
Swarm
At a high level, Swarm’s task is to start a lot of actors that will produce load on the server. These actors are called bots, and they can simulate client behaviour or dedicated server behaviour. Swarm consists of one or several agents that host these bots and communicate with each other.
More formally, here is a list of requirements for the tool:
- Reaction to state updates should be easy
- Concurrency should not be an issue
- Code should be automatically instrumentable
- Bot-to-bot communication should be easy
- Multiple instances should be joinable in order to create enough load
- The tool should be lightweight and capable of creating decent stress on the backend itself
As a bonus, I’ve also added some extra points:
- Both performance and end-to-end test scenarios should be possible
- The tool should be transport-agnostic; we should be able to plug this to any other possible transport if needed
- The tool features an imperative code style, as I personally have the firm opinion that a declarative style is not suitable for complex scenarios with conditional decisions
- Bots should be able to exist separately from the testing tool, meaning that there should be no hard dependencies
Our goal
Let’s imagine the code we’d like to write; we will consider the bot as a puppet, and it cannot do things on its own, it can only maintain invariants, while Scenario is the puppeteer that pulls the strings.
public class ExampleScenario : ScenarioBase
{
/* ... */
public override async Task Run(ISwarmAgent swarm)
{
// spawn bots and connect to backend
var leader = SpawnClient();
var follower = SpawnClient();
await leader.Login();
await follower.Login();
// expect incoming InviteAddedEvent
var followerWaitingForInvite = follower.Group.Subscription
.ListenOnceUntil(GroupInviteAdded)
.ThrowIfTimeout();
// leader sends invite and followers waits for it
await leader.Group.SendGroupInvite(follower.PlayerId);
await followerWaitingForInvite;
Assert.That(follower.Group.State.IncomingInvites.Count, Is.EqualTo(1));
var invite = follower.Group.State.IncomingInvites[0];
// now vice versa, the leader waits for an event...
var leaderWaitingForAccept = leader.Group.Subscription
.ListenOnceUntil(InviteAcceptedBy(follower.PlayerId))
.ThrowIfTimeout();
// ... and follower accept invite, thus producing the event
await follower.Group.AcceptGroupInvite(invite.Id);
await leaderWaitingForAccept;
Assert.That(follower.Group.State.GroupId, Is.EqualTo(leader.Group.State.GroupId));
PlayerId[] expectedPlayers = [leader.PlayerId, follower.PlayerId];
Assert.That(leader.Group.State.Players, Is.EquivalentTo(expectedPlayers));
Assert.That(follower.Group.State.Players, Is.EquivalentTo(expectedPlayers));
}
}
Steaming
Backend pushes a lot of updates to the client that can happen sporadically; in the example above, one such event is GroupInviteAddedEvent. The bot should be able to both react to these events internally and give an opportunity to watch them from outside code.
public Task SubscribeToGroupState()
{
Subscription.Listen(OnGroupStateUpdate);
Subscription.Start(api.GroupServiceClient.SubscribeToGroupStateUpdates, new SubscribeToGroupStateUpdatesRequest());
return Task.CompletedTask;
}
While code is pretty straightforward (and as you may have guessed OnGroupStateUpdate handler is just a long switch case), a lot of happens here.
StreamSubscription is itself a IObservable<ObservedEvent<TStreamMessage>>
and it provides useful extensions, has a dependent lifecycle, and is covered with metrics.
Another benefit: it requires no explicit synchronization to read or modify state, regardless of where the handler is implemented.
case GroupUpdateEventType.GroupInviteAddedEvent:
State.IncomingInvites.Add(ev.GroupInviteAddedEvent.GroupId, ev.GroupInviteAddedEvent.Invite);
break;
Concurrency should not be an issue
Above, the code is written as if it were linear, single-threaded code. The idea is simple: never execute code concurrently belonging to a scenario or to a bot spawned in that scenario, and further, the inner code for a bot/module should not be executed concurrently with other parts of a bot.
This is similar to a read/write lock, where scenario code is read (shared access) and bot code is write (exclusive access). And while our goal could be achieved with using these kinds of locks, there is a better way.
Task schedulers and the synchronization context
The two mechanisms mentioned in this heading are now very powerful parts of async code in C#. If you’ve ever developed a WPF application, you probably know that it’s a DispatcherSynchronizationContext that is responsible for elegantly returning your async calls back to the UI thread.
In our scenario, we don’t care about thread affinity, and instead care more about the execution order of tasks in a scenario.
Before rushing to write low-level code, let’s look at one not widely known class called ConcurrentExclusiveSchedulerPair . From the
Provides task schedulers that coordinate to execute tasks while ensuring that concurrent tasks may run concurrently and exclusive tasks never do.
This looks like exactly what we want! Now we need to ensure that all of the code inside the scenario is executed on ConcurrentScheduler while the bot’s code executes on ExclusiveScheduler.
How do you set a scheduler for a task? One option is to explicitly pass it as a parameter, which is done when a scenario launches:
public Task LaunchScenarioAsyncThread(SwarmAgent swarm, Launch launch)
{
return Task.Factory.StartNew(
() =>
{
/* <some observability and context preparations> */
return RunScenarioInstance(Scenario, swarm, LaunchOptions, ScenarioActivity, launch);
},
CancellationToken.None,
TaskCreationOptions.DenyChildAttach,
Scenario.BotScenarioScheduler.ScenarioScheduler).Unwrap();
}
The RunScenarioInstance method, in turn, invokes the SetUp and Run methods on the scenario, so they are executed in a concurrent scheduler (ScenarioScheduler is a concurrent part of ConcurrentExclusiveSchedulerPair).
Now, when we’re inside the scenario code and we do this…
public Task LaunchScenarioAsyncThread(SwarmAgent swarm, Launch launch)
{
return Task.Factory.StartNew(
() =>
{
/* <some observability and context preparations> */
return RunScenarioInstance(Scenario, swarm, LaunchOptions, ScenarioActivity, launch);
},
CancellationToken.None,
TaskCreationOptions.DenyChildAttach,
Scenario.BotScenarioScheduler.ScenarioScheduler).Unwrap();
}
…the async state machine does its job for us by keeping a scheduler for our tasks.
Now SendGroupInvite executes on concurrent scheduler as well, so we do the same trick for it, too:
public Task<SendGroupInviteResponse> SendGroupInvite(PlayerId inviteePlayerId)
{
return Runtime.Do(async () =>
{
var result = await api.GroupServiceClient.SendGroupInviteAsync(/* ... */);
if (!result.HasError)
{
State.OutgoingInvites.Add(inviteePlayerId);
}
return result;
});
}
Runtime abstraction wraps scheduling in the same way as before, by calling Task.Factory.StartNew with the proper scheduler.
Code generation
OK, now we need to manually wrap everything inside the Do call; and while this solves the issue, it is error prone, easy to forget, and generally speaking, well, it looks strange.
Let’s look at this part of code again:
await leader.Group.SendGroupInvite(follower.PlayerId);
Here, our bot has a Group property. Group is a module that exists just to divide code into separate classes and avoid bloating the Bot class.
public class BotClient : BotClientBase
{
public GroupBotModule Group { get; }
/* ... */
}
Lets say a module should have an interface:
public class BotClient : BotClientBase
{
public IGroupBotModule Group { get; }
/* ... */
}
public interface IGroupBotModule : IBotModule, IAsyncDisposable
{
GroupBotState State { get; }
Task<SendGroupInviteResponse> SendGroupInvite(PlayerId toPlayerId);
/* ... */
}
public class GroupBotModule :
BotClientModuleBase<GroupBotModule>,
IGroupBotModule
{
/* ... */
public async Task<SendGroupInviteResponse> SendGroupInvite(PlayerId inviteePlayerId)
{
// no wrapping with `Runtime.Do` here
var result = await api.GroupServiceClient.SendGroupInviteAsync(new() /* ... */);
if (!result.HasError)
{
State.OutgoingInvites.Add(new GroupBotState.Invite(inviteePlayerId, /* ... */));
}
return result;
}
|
And now it just works! No more wrapping and ugly code, just a simple requirement (that is pretty common for developers) to create an interface for every module.
But where is the scheduler? The magic happens inside the source generator that creates a proxy class for each IBotModule interface and wraps every function into Runtime.Do call:
public const string MethodProxy =
@"
public async $return_type$ $method_name$($method_params$)
{
$return$await runtime.Do(() => implementation.$method_name$($method_args$));
}
";
Instrumentation
The next step is to instrument the code in order to collect metrics and traces. First, every API call should be observed. This part is very straightforward, as our transport effectively pretends to be a gRPC channel, so we just use a properly written interceptor…
callInvoker = channel
.Intercept(new PerformanceInterceptor());
…where CallInvoker is a gRPC abstraction of client-side RPC invocation.
Next, it would be great to scope some parts of code in order to measure performance. For that reason, every module injects IInstrumentationFactory with the following interface:
public interface IInstrumentationFactory
{
public IInstrumentationScope CreateScope(
string? name = null,
IInstrumentationContext? actor = null,
[CallerMemberName] string memberName = "",
[CallerFilePath] string sourceFilePath = "",
[CallerLineNumber] int sourceLineNumber = 0);
}
Now you can wrap the parts that you are interested in:
public Task AcceptGroupInvite(GroupInvideId inviteId)
{
using (instrumentationFactory.CreateScope())
{
var result = await api.GroupServiceClient.AcceptGroupInviteAsync(request);
}
}
Looks familiar, right? While you can still use this feature to create sub-scopes, every module proxy method defines a scope automatically:
public const string MethodProxy =
@"
public async $return_type$ $method_name$($method_params$)
{
using(instrumentationFactory.CreateScope(/* related args> */))
{
$return$await runtime.Do(() => implementation.$method_name$($method_args$));
}
}
";
The instrumentation scope records execution time, exceptions, creates distributed traces, it can write debug logs, and it does a lot of other configurable stuff.
Bot-to-bot communication
The example in the “Our goal” section doesn’t really show any communication. We just know the follower’s bot PlayerId because it’s another local variable. While this style of writing scenarios is often easy and straightforward, there are more complex cases where this approach just doesn’t work.
I initially planned to implement some sort of blackboard pattern with a shared key-value storage for communication (like Redis), but after running some proof of concept scenario tests, it turned out that the amount of work could be greatly reduced down to two simpler concepts: a queue, and a selector.
Queue — Tickets
In the real world, players communicate with each other somehow – they write direct messages or use voice chat. With bots, we do not need to simulate that granularity, and we just need to communicate intentions. So, instead of “Hey Killer2000, invite me into your group please” we need a simple “Hey, someone, invite me into the group please”. Here’s where tickets come into play:
public interface ISwarmTickets
{
Task PlaceTicket(SwarmTicketBase ticket);
Task<SwarmTicketBase?> TryGetTicket(Type ticketType, TimeSpan timeout);
}
The bot can place a ticket, and then an another bot can retrieve that ticket. ISwarmTickets is nothing more than a message broker with a queue per ticketType. (Actually it is slightly more than that, as there are extra options to prevent bots from retrieving their own tickets, as well as other minor tweaks).
With this interface, we can finally split the example scenario into two independent scenarios. (here, all extra code is removed to illustrate the base idea):
private async Task RunLeaderRole(ISwarmAgent swarm)
{
var ticket = await swarm.Blackboard.Tickets
.TryGetTicket<BotWantsGroupTicket>(TimeSpan.FromSeconds(5))
.ThrowIfTicketIsNull();
await bot.Group.SendGroupInvite(ticket.Owner);
await bot.Group.Subscription.ListenOnceUntil(
GotInviteAcceptedEvent,
TimeSpan.FromSeconds(5))
.ThrowIfTimeout();
}
private async Task RunFollowerRole(ISwarmAgent swarm)
{
var waitingForInvite = bot.Group.Subscription.ListenOnceUntil(
GotInviteAddedEvent,
TimeSpan.FromSeconds(5))
.ThrowIfTimeout();
await swarm.Blackboard.Tickets.PlaceTicket(new BotWantsGroupTicket(bot.PlayerId));
await waitingForInvite;
await bot.Group.AcceptGroupInvite(bot.Group.State.IncomingInvites[0].Id);
}
Selector
We have two different behaviors, one for the leader, one for the follower. Of course, they can be split into two different scenarios and launched in parallel. Sometimes, this is the best way to do it, other times you may need a dynamic configuration of group sizes (several followers per single leader) or any other situation to distribute/select different data/roles.
public override async Task Run(ISwarmAgent swarm)
{
var roleAction = await swarm.Blackboard
.RoundRobinRole(
"leader or follower",
Enumerable.Repeat(RunFollowerRole, config.GroupSize - 1).Union([RunLeaderRole]));
await roleAction(swarm);
}
Here, RoundRobinRole is just a fancy wrapper around a shared counter and a modulo operation to select the proper element from the list.
Cluster of swarms
Now, with all communication hidden behind queues and shared counters, it becomes trivial to introduce either an orchestrator node, or use some existing MQ and KV storages.
Fun fact: we never finished the implementation of this feature. When QA got their hands on a single node implementation of SwarmAgent, they immediately started to simply deploy multiple instances of independent agents in order to increase load. Apparently, that was more than enough.
Single instance performance
What about performance? How much is lost inside all those wrappers and implicit synchronisations? I won’t overload you with all variety of tests performed, just the two most significant which proved that the system is capable of creating a good enough load.
Benchmark setup:
BenchmarkDotNet v0.14.0, Windows 10 (10.0.19045.4651/22H2/2022Update)
Intel Core i7-10875H CPU 2.30GHz, 1 CPU, 16 logical and 8 physical cores
.NET SDK 9.0.203
[Host] : .NET 9.0.4 (9.0.425.16305), X64 RyuJIT AVX2
.NET 9.0 : .NET 9.0.4 (9.0.425.16305), X64 RyuJIT AVX2
private async Task SimpleWorker()
{
var tasks = new List<Task>();
for (var i = 0; i < Parallelism; ++i)
{
var index = i;
tasks.Add(Task.Run(async () =>
{
for (var j = 0; j < Iterations; ++j)
{
await LoadMethod(index);
}
}));
}
await Task.WhenAll(tasks);
}
private async Task SchedulerWorker()
{
// scenarios are prepared in GlobalSetup
await Task.WhenAll(scenarios.Select(LaunchScenarioAsyncThread));
}
public class TestScenario : ScenarioBase
{
public override async Task Run()
{
for (var iteration = 0; iteration < iterations; ++iteration)
{
await botClient.Do(BotLoadMethod);
}
}
}
First let’s look at almost pure overhead of scheduling against simple Task spawning.
In this case, both load methods are as follows:
private ValueTask CounterLoadMethod(int i)
{
Interlocked.Increment(ref StaticControl.Counter);
return ValueTask.CompletedTask;
}
Results for Iterations = 10:
|
WorkerType |
Parallelism |
Mean |
Error |
StdDev |
Gen0 |
Gen1 |
Gen2 |
Allocated |
|---|---|---|---|---|---|---|---|---|
|
Simple |
10 |
3.565us |
0.0450us |
0.0421us |
0.3433 |
– |
– |
2.83KB |
|
Simple |
100 |
30.281us |
0.2720us |
0.2544us |
3.1128 |
0.061 |
– |
25.67KB |
|
Simple |
1000 |
250.693us |
2.1626us |
2.4037us |
30.2734 |
5.8594 |
– |
250.67KB |
|
Scheduler |
10 |
40.629us |
0.7842us |
0.8054us |
8.1787 |
0.1221 |
– |
66.15KB |
|
Scheduler |
100 |
325.386us |
2.3414us |
2.1901us |
81.0547 |
14.6484 |
– |
662.09KB |
|
Scheduler |
1000 |
4,685.812us |
24.7917us |
21.9772us |
812.5 |
375 |
– |
6617.59KB |
Looks bad? Not exactly. Before actually carrying out the test, I was expecting much worse performance, but the results really surprised me. Just think about how much happened under the hood and benefits we got just for ~4us per parallel instance. Anyway, this is just an illustration of overhead; we’re interested in much more practical benchmarks.
What could be a realistic worst case test scenario? Well, what about a function that does nothing more than an API call? On one hand, almost every method of the bot does that, but on the other hand, if there is nothing more than just API calls, then all the synchronization efforts are wasted, right?
The load method would just call PingAsync. For simplicity, RPC clients are stored outside bots.
private async ValueTask PingLoadMethod(int i)
{
await clients[i].PingAsync(new PingRequest());
}
Here are results, again 10 iterations (grpc server is in local network):
|
WorkerType |
Parallelism |
Mean |
Error |
StdDev |
Gen0 |
Gen1 |
Allocated |
|---|---|---|---|---|---|---|---|
|
Simple |
100 |
94.45 ms |
1.804 ms |
2.148 ms |
600 |
200 |
6.14 MB |
|
Simple |
1000 |
596.69 ms |
15.592 ms |
45.730 ms |
9000 |
7000 |
76.77 MB |
|
Scheduler |
100 |
95.48 ms |
1.547 ms |
1.292 ms |
833.3333 |
333.3333 |
6.85 MB |
|
Scheduler |
1000 |
625.52 ms |
14.697 ms |
42.405 ms |
8000 |
7000 |
68.57 MB |
As expected, the performance impact on real work scenarios is negligible.
Analysis
Of course, there are backend logs, metrics, and traces that provide a good view of what’s happening during load. But Swarm goes a step further, writing its own data — sometimes connected to the backend — complementing it.
Here’s an example of several metrics in a failure test, with an increasing number of actors. The test failed due to multiple SLA violations (see the timeouts in the API calls), and we have all the instrumentation needed to observe what was happening from the client perspective.


We usually stop the test completely after a certain number of errors, that’s why the API call lines end abruptly.
Of course, traces are necessary for good observability. For Swarm test runs, client traces are linked with backend traces onto one tree. Particular traces can be found by connectionIdD/botId, which helps with debugging.


Note: DevServer is a convenient monolith build of all-in-one backend services to be launched on developers PC, and this is a specifically crafted example to reduce the amount of details on the screen.
Swarm bots write another kind of trace: they mimic the traces used in performance analysis. With the aid of existing tools, those traces can be viewed and analyzed using built-in capabilities like PerfettoSQL.


What we ended up with in the end
We now have an SDK that both GameClient and Dedicated Server bots are built on. These bots now support the majority of the game logic—they include friends subsystems, support groups, and matchmaking. Dedicated bots can simulate matches where players earn rewards, progress quests, and much more.
Being able to write simple code made it possible to create new modules and simple test scenarios by the QA team. There is an idea about FlowGraph scenarios (visual programming), but this remains only an idea at this time.
Performance tests are almost continuous – I say almost because one still has to start them manually.
Swarm helps not only with tests, but is commonly used to reproduce and fix bugs in the game logic, especially when this is hard to do manually, like when you need several game clients performing a special sequence of actions.
To sum things up, we’re extremely satisfied with our result and definitely have no regrets about the effort spent on developing our own testing system.
I hope you enjoyed this article, it was challenging to tell you about all the nuances of Swarm development without making this text excessively bloated. I’m sure I may have excluded some important details in the process of balancing text size and information, but I’ll gladly provide more context if you have any questions!







{kind=link}