Turn Hours of Training Into Minutes With GPU Acceleration
If you’re a machine learning practitioner, you know this scene well.
You’ve spent hours wrangling data, engineering the perfect features, and carefully designing your experiment. Everything is ready. You finally type model.fit(X, y) and hit enter.
And then… you wait.
The progress bar creeps forward at a glacial pace. You grab a coffee. You check Slack. You come back, and your CPU is still grinding away.
Slow training kills momentum. You can’t test features, tune hyperparameters, and keep your head in the problem.
n The Most Expensive Part of Machine Learning is Your Time
XGBoost has earned its reputation as the powerhouse of gradient boosting. It’s the gold standard on tabular datasets. But its strength comes with a cost. When you scale to millions of rows, training time balloons from minutes into hours.
Most practitioners don’t realize that XGBoost has a single parameter that can transform this experience. Flip it, and your model can train 5–15x faster. No algorithm changes. No new libraries. Just one line in your config.
That one change takes you from completing a single experiment in a day to running several. Hyperparameter searches that once dragged on for days now wrap up in hours. Instead of waiting on a progress bar, you stay in the loop, testing ideas while they’re fresh and keeping momentum in your work.
In many cases, CUDA acceleration makes the difference between completing a job and never finishing it.
The “Magic” Parameter: GPU Acceleration Made Easy
XGBoost has built-in support for NVIDIA CUDA, so tapping into GPU acceleration doesn’t require new libraries or code rewrites. Often, it’s as simple as flipping a single parameter.
Here’s a typical CPU workflow:
import xgboost as xgb
model = xgb.XGBClassifier(
...
tree_method="hist" # CPU training
)
model.fit(X_train, y_train)
To use your GPU, you just change tree_method to "gpu_hist":
import xgboost as xgb
model = xgb.XGBClassifier(
...
tree_method="gpu_hist" # GPU training
)
model.fit(X_train, y_train)
or for regressors, set device="cuda":
import xgboost as xgb
xgb_model = xgb.XGBRegressor(device="cuda")
xgb_model.fit(X, y)
That’s it.
Whether you’re using XGBClassifier or XGBRegressor, adding device="cuda" tells XGBoost to use all available NVIDIA GPU resources. This single change can make your training 5–15x faster on large datasets.
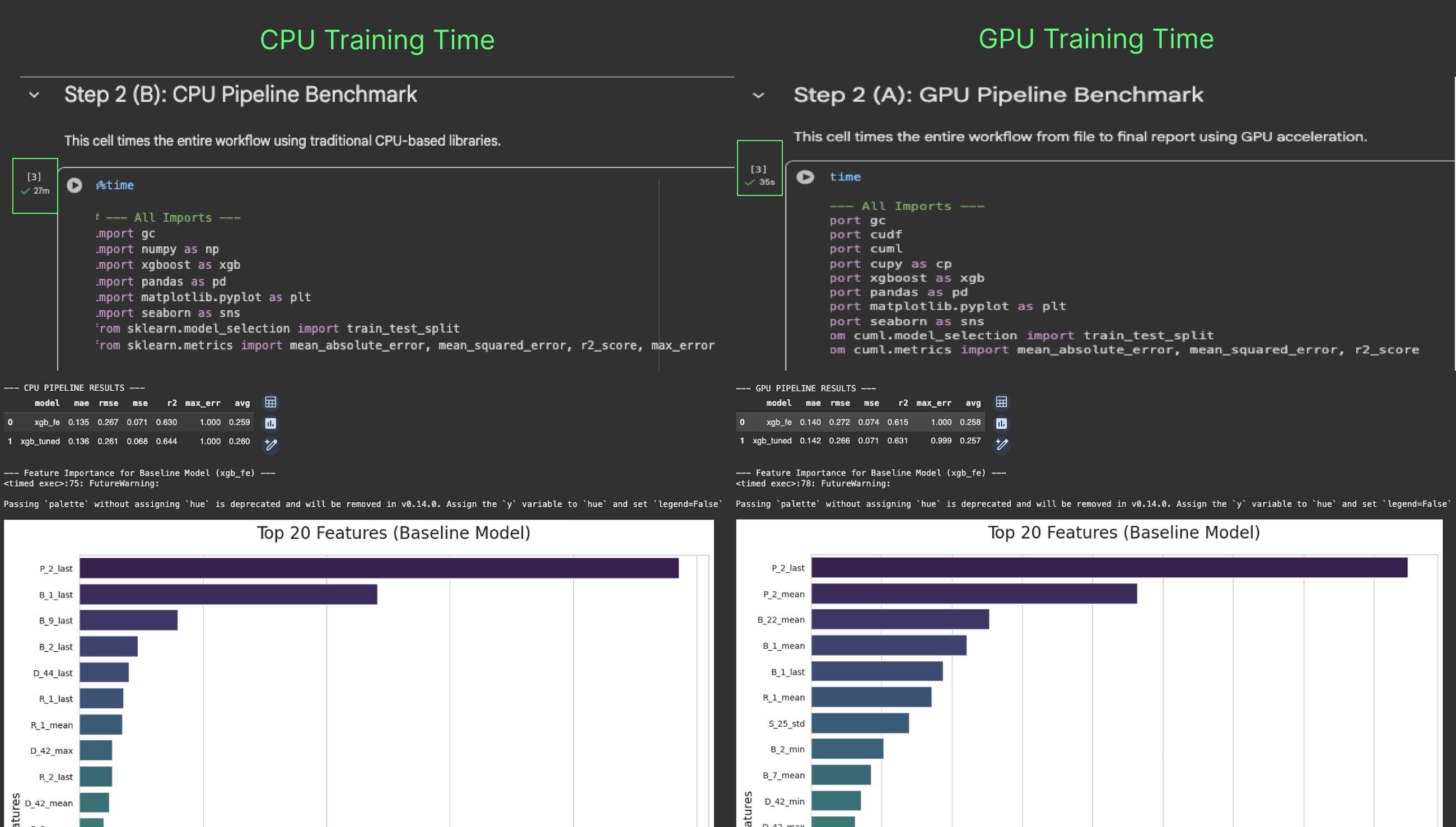
The Proof: A 46x Speed-up on Amex Default Prediction
To show the speedup in action, we benchmarked an XGBoost classifier on a 5.5 million row (50giga) subset of the American Express Default Prediction dataset, which includes 313 features.
We trained the model on two configurations:
- CPU: An M3 Pro 12-core CPU.
- GPU: An NVIDIA A100 GPU.
Here’s the training time comparison:
n  The results are dramatic:
The results are dramatic:
- CPU Training Time: 27 minutes
- NVIDIA GPU Training Time: 35 seconds
While achieving near identical performance.
The GPU’s advantage only grows with scale. On 50M or 500M rows, CPU hours can stretch into days, while GPUs, built for massive parallel workloads, handle the growth with minimal added time.
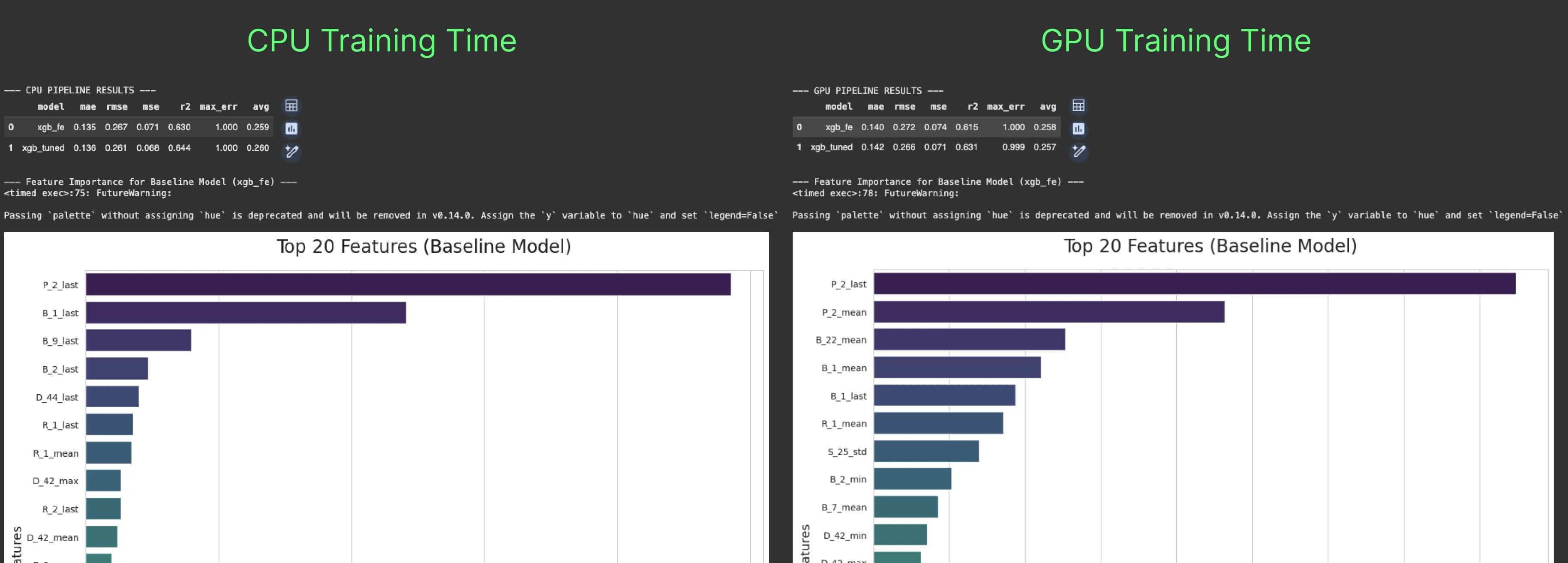
The difference across metrics like R², RMSE, and MAE is minimal, whether on baseline models or tuned ones. So, you’re not trading accuracy for speed. You’re getting the same results in a fraction of the time, which means more experiments and iterations.
In terms of predictive power, both models agree on one thing: P-2_last is by far the most important feature, and B_1_last also makes the top five. Beyond that, they start to diverge.
The CPU model focuses on _last features, focusing on the most recent values. The GPU model favors aggregated _mean features like P-2_mean, B-22_mean, and B-1_mean, features the CPU never ranks in its top five.
This suggests a hypothesis: the CPU model captures short-term risk signals, responding to the most recent events, while the GPU model captures long-term patterns, evaluating a customer’s risk across their full history. In other words, the CPU answers, “Is this customer a risk right now?” and the GPU answers, “Is this customer fundamentally risky over the long term?”
We also expect that on even larger, terabyte-scale datasets, GPUs could produce models with slightly better metrics thanks to their ability to process more data at once. At this scale, though, the main advantage is speed: getting results in seconds instead of hours.
Try It Yourself: Run the code and see the performance difference in this Notebook.
Best Practices for GPU acceleration
Adding device="cuda" is the first step. To get the most out of GPU acceleration, keep these best practices in mind:
Start With the Right-Sized Data
GPU acceleration works best on datasets that are large enough to justify the overhead of moving data from system RAM to GPU memory. The sweet spot is typically datasets between 4 GB and 24 GB, though benefits can appear starting at 2–4 GB.
For very small datasets, the time spent transferring data to the GPU and setting up parallel computations can actually exceed the training time itself, making CPU training faster in these cases. Always benchmark for your specific workload.
Mind Your VRAM: Fit Your Data in GPU Memory
GPUs have their own high-speed memory, called VRAM, which is separate from your system RAM. For standard training, your dataset needs to fit entirely in VRAM. You can check available VRAM using the nvidia-smi command.
As a rule of thumb: if your DataFrame uses 10 GB of system RAM, you’ll need a GPU with more than 10 GB of VRAM. For large workloads, GPUs like the NVIDIA A10G (24 GB) or A100 (40–80 GB) are common choices. If you see out-of-memory errors, it usually means your dataset is too large to fit in the GPU’s memory.
Optimize Data Types to Reduce Memory Footprint
One of the simplest ways to save VRAM is by using more efficient data types. Pandas defaults to 64-bit types (float64, int64), which are usually more precise than needed.
Converting columns to 32-bit types (float32, int32) can cut memory usage roughly in half without impacting model accuracy. For example: df['my_column'].astype('float32'). This small adjustment can make a big difference when working with large datasets on a GPU.
Go End-to-End: Accelerate Data Prep with cudf.pandas
Often, the biggest bottleneck isn’t training itself but preparing the data. Moving data back and forth between CPU and GPU memory adds overhead that can slow your workflow. The cudf.pandas library solves this by providing a GPU-powered drop-in replacement for pandas.
By starting your script with import cudf.pandas as pdall data loading and feature engineering operations run directly on the GPU. When you pass this GPU-native DataFrame to XGBoost, you eliminate transfer overhead and achieve massive end-to-end speed-ups.
For Datasets Larger Than VRAM: Use External Memory
What if your dataset is 100 GB, but your GPU only has 24 GB of VRAM? With XGBoost 3.0, external memory support lets you handle this by processing the data in chunks from system memory or disk. This enables GPU-accelerated training for terabyte-scale datasets on a single GPU, without losing performance. We’ll explore this feature in more detail in the next section.
Beyond VRAM: Training Terabyte-Scale Datasets With XGBoost 3.0
In the past, datasets larger than a GPU’s VRAM were a hard limit for accelerated training. You either had to downsample your data or fall back to slower CPU-based workflows.
The release of XGBoost 3.0 eliminates this barrier with a new external memory capability. This allows you to train on massive datasets by streaming data from system memory or disk directly to the GPU for processing. The entire dataset never has to reside in VRAM at once.
This makes scalable gradient boosting on terabyte-scale workloads possible on a single GPU, a task that previously required large, distributed clusters. On modern hardware like the NVIDIA Grace Hopper Superchip, this approach can be up to 8x faster than a multi-core CPU system, all while maintaining full performance and accuracy.
While this feature works with the core DMatrix object rather than the Scikit-Learn wrapper, the parameters remain familiar. You simply point XGBoost to your dataset on disk:
When paired with cudf.pandas for data preparation, your entire workflow for terabyte-scale datasets can now run on the GPU. Massive datasets now give you the scale needed to build stronger models in a fraction of the time.
Reclaim Your Time
In machine learning, the biggest cost is the time spent waiting. Waiting for models to train, for data to process, or for experiments to finish slows down your ability to test ideas, uncover insights, and create value.
NVIDIA GPU acceleration lets you reclaim that time.
With a single parameter change, you can train models 5–15x faster, run end-to-end data pipelines on the GPU, and even work with datasets larger than your GPU’s memory. This speed lets you move through experiments quickly, testing ideas and processing data without long delays.
The tools are ready, the integrations are seamless, and the setup is straightforward. Faster iteration means more experiments, more discoveries, and ultimately, better models.
From here, you have a few different ways to dive in:
- Follow the NVIDIA-annotated Notebook for a step-by-step guide.
- Watch the full walkthrough in the YouTube video.
- Dive into the official XGBoost Documentation to explore all
cuda configuration options.GPU Acceleration Made Ea
Don’t just take my word for it. Run my Amex notebook, and feel just how much faster your workflow can be.
Happy building, n Paolo







{kind=link}