 | HackerNoon")
How are you, hacker?
🪐 What’s happening in tech today, January 26, 2026?
The
HackerNoon Newsletter
brings the HackerNoon
homepage
straight to your inbox.
On this day,
First Performance of Mozart’s Opera “The Marriage of Figaro” in 1786, India officially became a republic in 1950, The Apollo Theater in New York launched its first Amateur Night in 1934,
and we present you with these top quality stories.
From
Choosing an LLM in 2026: The Practical Comparison Table (Specs, Cost, Latency, Compatibility)
to
With CBDCs, Central Banks Are Making the Same Mistake Kodak Made,
let’s dive right in.
Can ChatGPT Outperform the Market? Week 26
By @nathanbsmith729 [ 4 Min read ] Final Week Results Read More.
Your Release Process Is a Projection of Fear

By @b128s [ 6 Min read ] Your release process isnt neutral. It reflects what youre most afraid of: breaking production or building something nobody wants. Read More.
Choosing an LLM in 2026: The Practical Comparison Table (Specs, Cost, Latency, Compatibility)
By @superorange0707 [ 6 Min read ] Compare top LLMs by context, cost, latency and tool support—plus a simple decision checklist to match “model + prompt + scenario”. Read More.
With CBDCs, Central Banks Are Making the Same Mistake Kodak Made

By @edwinliavaa [ 11 Min read ] Central banks are repeating Kodak’s biggest mistake. Why CBDCs may fail—and why Bitcoin represents a deeper monetary paradigm shift. Read More.
AI Just Passed the Turing Test for Piano Music

By @aimodels44 [ 9 Min read ]
This is a Plain English Papers summary of a research paper called Generating Piano Music with Transformers: A Comparative Study of Scale, Data, and Metrics. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
The Turing test for music
Before diving into models and architectures, theres a more fundamental question hiding beneath all the technical choices: what does it actually mean to succeed at music generation?
For decades, the answer was easy. AI-generated music sounded robotic, lifeless, predictable in ways youd notice immediately. But something has shifted. Researchers have begun asking whether an algorithm could fool a listener in a blind test. Not whether it matches some mathematical criterion, but whether a person sitting down to listen could tell the difference between a piece composed by a human and one generated by a machine.
This is the north star of the research. Everything else serves this single question. And the answer turns out to be surprising: when built correctly, a transformer trained on enough diverse piano data can produce music that humans genuinely struggle to distinguish from human composition.
The researchers ran a Turing-style listening study where participants heard piano pieces and had to guess whether each was human or AI-composed. For the best-performing model, results hovered near 50% accuracy. Thats not a typo. It means listeners were essentially guessing, unable to confidently separate human from machine.
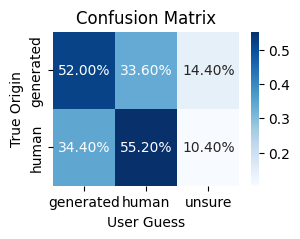
Confusion matrix from the musical Turing test showing listener accuracy in distinguishing AI-composed from human-composed pieces across all genres
The confusion matrix reveals something elegant: the model crossed a genuine threshold. Not because researchers found a clever trick, but because they systematically understood what actually moves the needle on the one metric that matters.
The problem with metrics that lie to you
But heres the uncomfortable truth that most music generation research glosses over: the quantitative metrics researchers have relied on for years dont predict what humans actually think.
Imagine youre evaluating music using a standard metric like prediction accuracy. The model learns to predict the next note correctly with high confidence. Thats measurable. Thats publishable. But high accuracy doesnt guarantee the music feels alive or interesting. It might just mean the model learned to play it safe, following familiar patterns. The best human composers break rules. They surprise listeners. Those surprises might actually lower the models prediction accuracy while raising its artistic value.
This gap between metrics and reality creates a trap: optimize for the wrong numbers and you build a model that scores well on paper but fails in practice. The research here cuts through that noise by comparing quantitative metrics directly against human judgments collected in the listening study. Which metrics actually correlate with listeners thinking the music sounds human? Which ones mislead you into optimizing the wrong thing?
This reframing changes how you should think about model development. Instead of treating all metrics equally, you can ask: does my model score higher on these metrics than lower-performing models? If not, that metric isnt measuring what I care about. If yes, I should probably care more about it. Its a simple idea but one thats missing from much of the music generation literature.
Three levers, three tradeoffs
Now comes the actual research question: what makes one music generation model better than another?
The researchers didnt build a single system and declare victory. They systematically varied three independent dimensions and compared results. First, model size. How many parameters does the transformer need? Second, training data. What dataset should you train on, and how much does diversity matter compared to curation? Third, training strategy. Should you train from scratch, or pre-train on one dataset then fine-tune on another?
Each lever has tradeoffs. Bigger models demand more compute. Larger datasets take longer to collect and clean. Different training strategies require different computational schedules. The real question isnt which lever is best in the abstract, but which gives you the most improvement for the effort and cost youre willing to spend.
This systematic approach separates this work from the typical narrative in deep learning research, where the implicit assumption is always bigger equals better. The researchers built many models, compared them carefully, and asked what actually matters. Thats methodologically sound, and it yields insights that directly help practitioners make real tradeoffs.
Why messy data beats curated perfection
Start with the data question. The researchers compared two main sources: MAESTRO, which is meticulously curated with about 200 hours of recordings and high-quality MIDI annotations, and Aria-Deduped, which is much larger and messier with around 80K MIDI files from diverse genres and sources.
The conventional wisdom in machine learning suggests you should invest in data quality. Carefully curated datasets reduce noise and bias. They represent gold standard examples. But the listening study results tell a different story. Models trained on the larger, more diverse Aria dataset outperformed models trained on the smaller MAESTRO dataset.
This is where the papers central insight emerges: bigger data beats bigger models. But thats only half the story. The critical detail is diversity. The Aria dataset contains piano music from many genres, styles, and recording conditions. Its messier precisely because its broader. A model trained on that breadth learns richer statistical patterns than one trained on pristine examples from a narrow slice of music.
Think about how language models develop intuition. They dont learn by studying 10,000 perfectly edited sentences in one style. They learn by reading millions of texts written by millions of people in different contexts, tones, and registers. The variety teaches the model what varies and what stays constant across language. The same principle applies to music. Diverse data teaches the model whats essential to the grammar of piano music versus whats incidental to a particular recording or performance style.
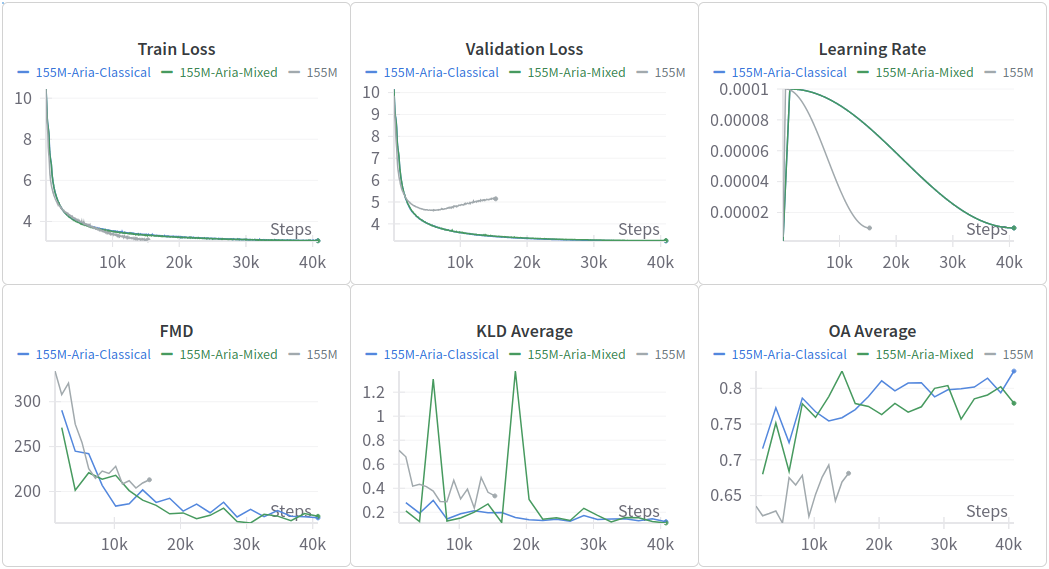
Training curves comparing models pre-trained on Aria-Deduped against the baseline model trained only on MAESTRO, showing faster convergence and better final performance from the larger dataset
The gap widens as you train longer. The model pre-trained on Aria continued improving on downstream tasks even with limited fine-tuning data, while the MAESTRO-only model plateaued earlier. This has a practical implication: if youre building a music generation system and you can either spend time curating a smaller dataset or gathering more diverse data (even if its rougher), choose the latter.
When bigger models hit diminishing returns
Model scaling is the gospel of modern deep learning. Build a bigger model, throw more compute at it, and performance improves. This has held true across language, vision, and many other domains. But even a good principle has limits.
The researchers compared transformers of different sizes, all trained on the same datasets. A 155M-parameter model. A 355M-parameter model. A 550M-parameter model. A 950M-parameter model. As youd expect, larger models generally performed better in pre-training. But the gains diminish. Each doubling of model size gives increasingly smaller improvements.
More importantly, the interaction between model size and data size matters. A 950M-parameter model trained on large, diverse data beats a smaller model trained on the same data. But a larger model trained on small, curated data doesnt dramatically outperform a smaller model trained on the same limited data. The model gets larger but has fewer diverse examples to learn from, so it ends up memorizing rather than generalizing. Youve wasted parameters on overfitting.
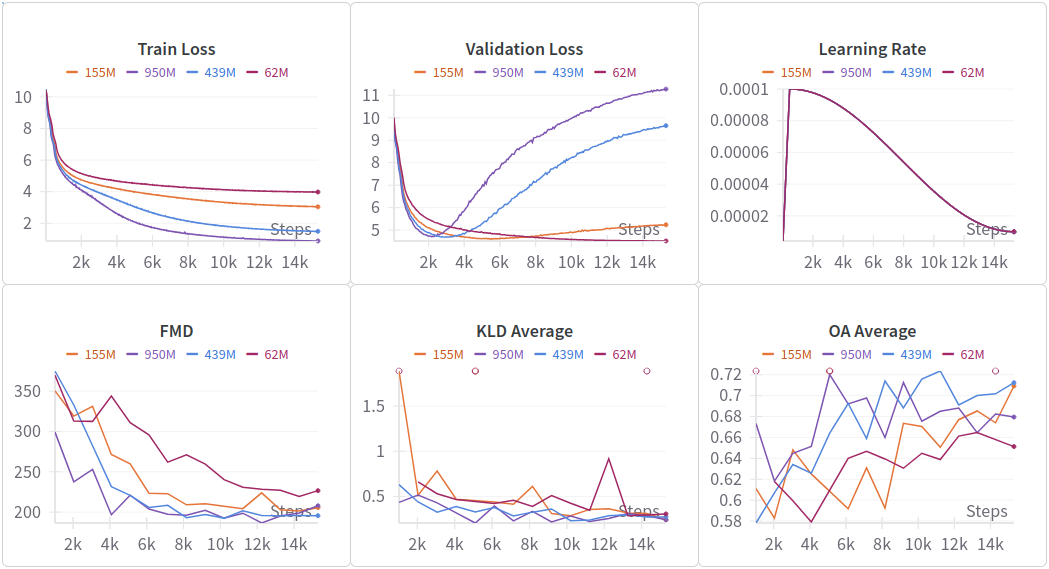
Training loss curves for MAESTRO models of different sizes, showing how performance gains diminish as model size increases when training data is limited
This tells you something crucial: find the sweet spot where your model has enough capacity to express patterns in your data without being so oversized that it memorizes. For the 80K Aria dataset, that sweet spot appears to be in the 950M range. A 155M model trained on the same data was close behind, suggesting the marginal benefit of going bigger is limited.
The practical insight: dont automatically assume you need to build the largest possible model. You need a model large enough that data diversity, not model capacity, is your bottleneck. Build bigger than that and youre spending compute on diminishing returns.
The efficiency of learning from experts after learning broadly
Training strategy introduces another variable. What if you didnt train only on one dataset? What if you pre-trained on large, diverse data to learn the fundamentals of piano music, then fine-tuned on smaller, curated expert data to learn the specific style or qualities you care about?
This is where the pre-training and fine-tuning paradigm reveals its power. A model trained only on MAESTRO learns from limited examples. Its slow to train because theres not much data. But a model pre-trained on the 80K Aria files, then fine-tuned on MAESTRO, learns rapidly. The pre-training phase captures broad patterns of piano music. The fine-tuning phase refines those patterns toward MAESTROs particular characteristics.
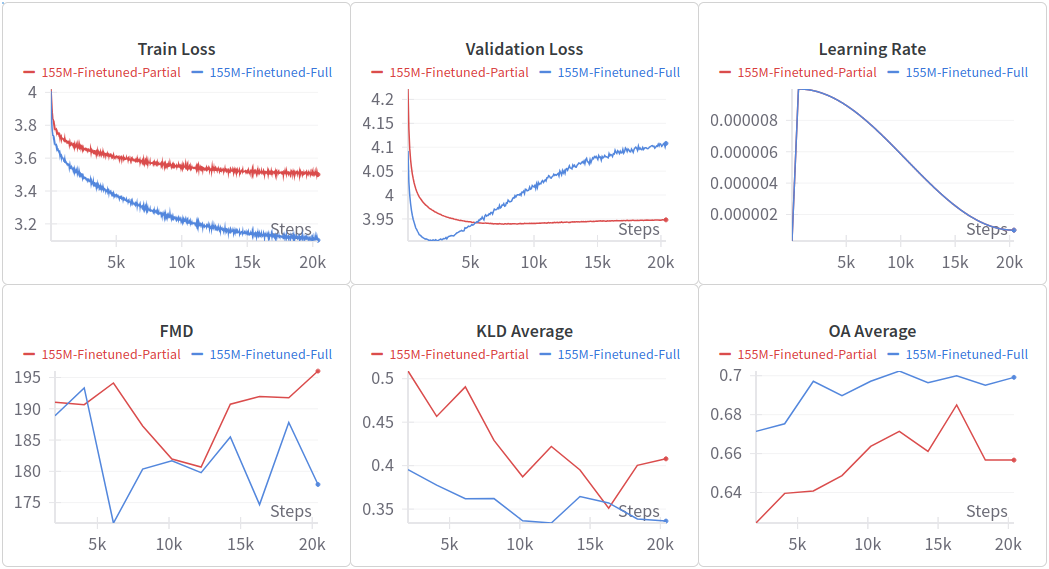
Training curves for models pre-trained on Aria-Deduped and fine-tuned on MAESTRO, showing rapid convergence and superior performance compared to training from scratch
This matters because it solves a real problem in music generation: the highest-quality datasets are small and expensive to create, while large datasets are often noisier. Pre-training lets you leverage both. You gather whatever diverse data you can find, train on it to establish a foundation, then apply limited expert data where it counts most.
The fine-tuning experiments with different context window sizes (how much previous music the model can see when generating the next note) further confirm this principle. A model that started with broader pre-training learned to use context windows more effectively during fine-tuning than a model starting from scratch.
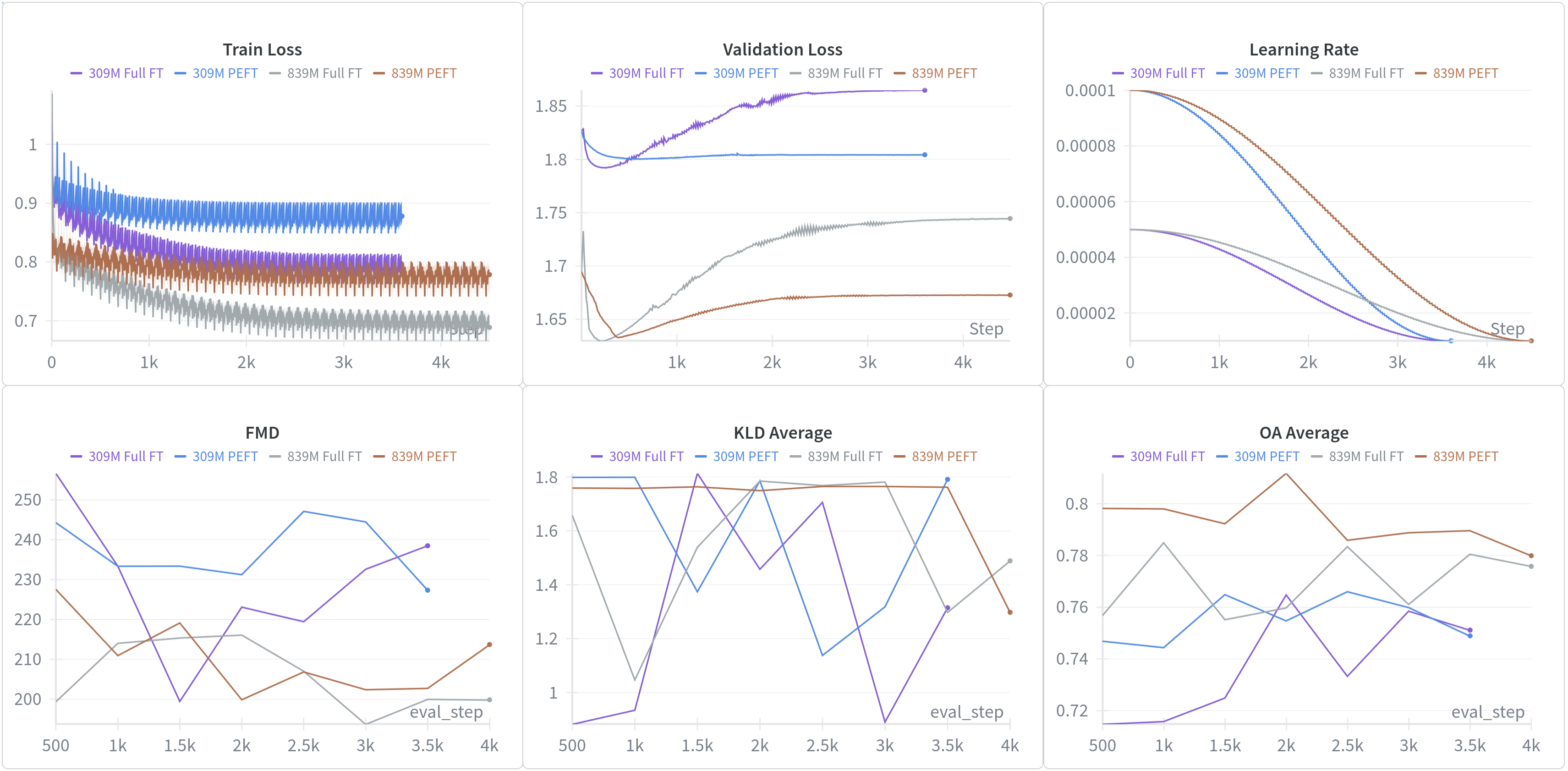
Fine-tuning curves for models with different context sizes, showing how architectural choices interact with training strategy
The practical takeaway: if you have access to limited high-quality data in a specific domain or style, dont waste it training from scratch. Pre-train broadly first, then fine-tune precisely. Youll converge faster and achieve better results with less total training time.
What humans actually hear
All these choices, all this careful ablation, point toward one question: can the best model actually fool human listeners?
The researchers collected human judgments through a listening study where participants heard pieces of piano music and had to classify each as human or AI-composed. They didnt tell listeners whether they were comparing against the best model or a baseline. They just asked: does this sound human?
The confusion matrix shows the results. The best-performing model, a 950M-parameter transformer trained on 80K diverse MIDI files, achieved near 50% accuracy in the classification task. Thats the threshold where humans cant reliably tell the difference.
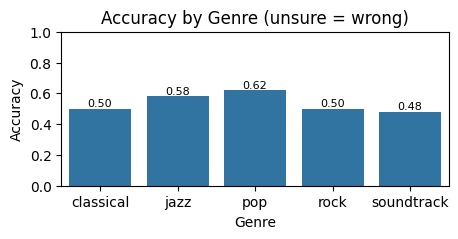
Accuracy of listener classifications broken down by genre, showing which genres the model fools most and least convincingly
But accuracy varies by genre. Some musical styles are easier to fool humans with than others. Looking at accuracy separated by both genre and whether the piece was AI or human reveals the models strengths and weaknesses.
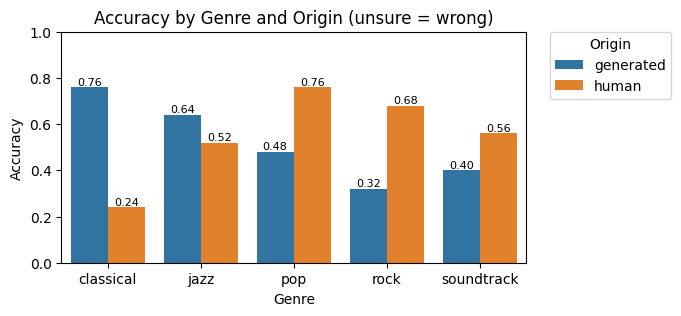
Performance broken down by both genre and origin, showing where the model excels and where listeners can still detect the AI
This variation is instructive. Its not that the model universally reaches human-level performance. Rather, it reaches human-level performance on some genres while still having tells on others. Classical perhaps. Jazz perhaps not. This reflects the training data composition, the diversity of examples the model saw during training.
The distribution of listener guesses shows whether people had an intrinsic bias to guess human or AI.
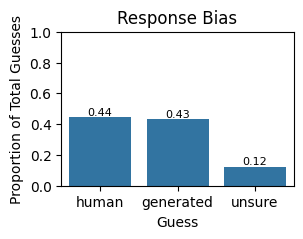
Response bias showing whether listeners tended to guess human or AI composition, which affects how to interpret the raw accuracy numbers
Humans dont classify randomly. They have biases, preferences, hunches. Some people might assume that anything unusual-sounding must be AI. Others might assume that complexity implies human authorship. Understanding these biases matters for interpreting what the 50% accuracy actually means. If people had a strong bias, 50% might actually represent strong model performance despite the bias pulling toward one label.
The listening study validates what the metrics couldnt quite capture on their own. The model produces something genuinely musical. Not just statistically plausible note sequences, but pieces that engage listeners the way human-composed music does.
The lesson beneath the technique
The full picture across all these decisions reveals a pattern. Success in music generation didnt come from finding one clever architectural innovation or discovering that one weird trick. It came from systematically understanding how three variables interact: how much capacity your model needs, how diverse your training data should be, and how to efficiently transfer learning from general to specific.
The best model wasnt the biggest. It was the one trained on the most diverse data, with enough capacity to express what it learned. Thats a lesson that extends far beyond piano music. Across domains where youre generating structured sequences, the same principle likely holds. Diversity in training data often outweighs curation. Pre-training on broad data before fine-tuning on specific data accelerates learning. And model size matters, but only until youve given the model enough room to express the patterns in your training data.
The real achievement here is methodological. By building many models and comparing them systematically against human judgment, the researchers created a framework for developing better music generation systems. They didnt declare that one architectural choice is optimal for all time. They showed how to ask the right questions and how to measure the answers in a way that actually corresponds to what matters in practice: whether the music sounds human.
Original post: Read on AIModels.fyi
Read More.
🧑💻 What happened in your world this week?
It’s been said that
writing can help consolidate technical knowledge,
establish credibility,
and contribute to emerging community standards.
Feeling stuck? We got you covered ⬇️⬇️⬇️
ANSWER THESE GREATEST INTERVIEW QUESTIONS OF ALL TIME
We hope you enjoy this worth of free reading material. Feel free to forward this email to a nerdy friend who’ll love you for it.See you on Planet Internet! With love,
The HackerNoon Team ✌️







{kind=link}