
Table of links
Abstract
1 Introduction
2 Background and Related Work
2.1 Different Formulations of the Log-based Anomaly Detection Task
2.2 Supervised v.s. Unsupervised
2.3 Information within Log Data
2.4 Fix-Window Grouping
2.5 Related Works
3 A Configurable Transformer-based Anomaly Detection Approach
3.1 Problem Formulation
3.2 Log Parsing and Log Embedding
3.3 Positional & Temporal Encoding
3.4 Model Structure
3.5 Supervised Binary Classification
4 Experimental Setup
4.1 Datasets
4.2 Evaluation Metrics
4.3 Generating Log Sequences of Varying Lengths
4.4 Implementation Details and Experimental Environment
5 Experimental Results
5.1 RQ1: How does our proposed anomaly detection model perform compared to the baselines?
5.2 RQ2: How much does the sequential and temporal information within log sequences affect anomaly detection?
5.3 RQ3: How much do the different types of information individually contribute to anomaly detection?
6 Discussion
7 Threats to validity
8 Conclusions and References
5 Experimental Results
We organize this section by our research questions (RQs).
5.1 RQ1: How does our proposed anomaly detection model perform compared to the baselines?
5.1.1 Objective
This research question aims to assess the effectiveness of our proposed anomaly detection framework by evaluating its performance. We compare it against three baseline models. This research question also serves as a sanity test to ensure the validity of the results and findings of the subsequent RQs. As our objective is to check if our model works properly, we do not expect the model to outperform all the state-of-the-art methods, but it should be able to achieve competitive performance.
5.1.2 Methodology
In this research question, we evaluate the base form of the proposed Transformerbased model, which is trained without positional and temporal encoding against the baselines. According to a recent study [23], simple models can outperform complex DL ones in anomaly detection in both time efficiency and accuracy. The superior results achieved by sophisticated DL methods turn out to be misleading due to weak baseline comparisons and ineffective hyperparameter tuning. Hence, in this study, we employ simple machine learning methods, including K-Nearest Neighbor (KNN), Decision Tree (DT), and Multi-layer Perception (MLP) as baselines as in Yu et al.’s work [23]. We use the MCV as the input feature for the baseline models. We additionally conduct a grid search on the hyperparameters to strive for optimal performance for the baseline models. For the HDFS dataset, we use the Block ID to group the logs into sessions. For the datasets without a grouping identifier, the samples in the training and test sets are of varying lengths generated according to the process explained in Section 4.3.
5.1.3 Result
Table 3 shows the performance of the base form of the proposed Transformer-based model and our baseline models. Overall, our model achieves excellent performance on the studied datasets, with an F1 score ranging from 0.966 to 0.992. From the results, we can find that the base form of our model achieves competitive results against the baseline models on the HDFS dataset. However, across all other datasets, our model generally outperforms baseline models in terms of F1 scores and its performance is stable across different datasets. In the HDFS dataset, the grouping of log sequences by block ID likely results in more structured and homogeneous sequences, facilitating easier pattern recognition and classification for both the proposed Transformer-based method and the baseline models.
On the other hand, generating log sequences with varying lengths in the other datasets introduces additional challenges. When log sequences of varying lengths are transformed into MCVs, variations in the volume of message counts across sequences may arise, presenting challenges in modeling. This variability in sequence lengths may pose difficulties for simpler machine learning methods like KNN, Decision Trees, and MLP, which may struggle to effectively learn and generalize patterns from sequences of different lengths across the entire dataset. The superior and stable performance of the Transformer-based model in these datasets could be attributed to its inherent ability to handle variable-length sequences through mechanisms like self-attention, which allows the model to capture contextual information across sequences of different lengths effectively. The variability in baseline performances across datasets exhibits the sensitivity of simple machine learning methods to dataset characteristics and the varying lengths of log sequences.
5.2 RQ2: How much does the sequential and temporal information within log sequences affect anomaly detection?
5.2.1 Objective
A series of models (e.g., RNN, LSTM, Transformer) that are capable of catching the sequential or temporal information are employed for log-based anomaly detection. However, the significance of encoding these sequential or temporal information within log sequences is not clear, as there is no study that directly compares the performances with and without encoding the information. Moreover, recent studies show that anomaly detection models with log representations that ignore the sequential information can achieve competitive results compared with more sophisticated models [7]. In this research question, we aim to examine the role of sequential and temporal information in anomaly detection with our proposed transformer-based model.
5.2.2 Methodology
In this research question, we compare the performance of our proposed model on different combinations of input features of log sequences. We use the semantic embedding (as described in Sec 3.2) generated with log events in all the combinations. Additionally, we utilize three distinct inputs for the transformer-based model: pure semantic embedding, the combination of semantic embedding and positional encoding, and the combination of semantic embedding and temporal encoding. As the Transformer has no recurrent connections, it does not capture input token order like LSTM or GRU. It processes the whole input simultaneously with self-attention. Therefore, without positional and temporal encoding, the Transformer treats log sequences like bags of words (i.e., log events or messages), disregarding their order. This feature of the Transformer model enables us to evaluate the roles of positional and temporal information with the studied datasets in detecting anomalies. For temporal encoding, we explore two methods as outlined in Section 3.3.
5.2.3 Result
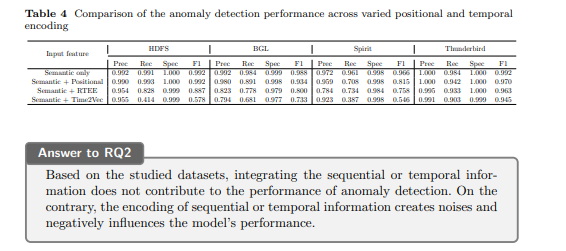
Table 4 shows the comparison of the performance when the model has different combinations of input features. From the results, we find that the model can achieve the best performance when the input is the semantic embedding of log events in all the datasets. In this case, the sequential information within log sequences is ignored by the model. The log sequences are like a “bag of log events” for the model. When the positional or temporal encoding is added to the semantic embedding of log events, the performance drops to some degree. The reason behind this may be explained by information loss induced by the addition operation: The positional or temporal encoding may not be too informative and could serve as noises, which influence the model to distinguish the log events that are associated with anomalies. From the analysis of the training curves, we also observe a slower convergence speed when incorporating positional or temporal encoding. Among the positional and temporal encodings, the positional encoding works better in all the cases. This can be explained by the fact that positional encoding conveys simpler sequential information while temporal encoding carries richer information.
However, the richer information may not be very helpful in detecting the anomalies within log sequences. The information redundancy further increases the learning difficulty of the model to master the occurrence patterns associated with anomalies within log data. Moreover, among the two methods of temporal encoding, the RTEE performs better than Time2Vec. This can be explained by the trainable characteristic of Time2Vec, which may demand more training efforts to reach the optimum results. The results reflect that the encoding of sequential and temporal information does not help the model achieve better performance in detecting anomalies in the four studied datasets. The occurrences of certain templates and semantic information within log sequences may be the most prominent indicators of anomalies.
5.3 RQ3: How much do the different types of information individually contribute to anomaly detection?
5.3.1 Objective From the RQ2, we find that the sequential and temporal information does not contribute to the performance of the anomaly detection model on the datasets. On the contrary, the encoding added to the semantic embedding may induce information loss for the Transformer-based model with the studied datasets. In this research question, our objective is to further analyze the different types of information associated with the anomalies in studied datasets. We aim to check how much semantic, sequential, and temporal information independently contributes to the identification of anomalies. This study may offer insight into the characteristics of anomalies within the studied datasets.
5.3.2 Methodology
In this research question, we utilize semantic embedding (generated with all-MiniLML6-v2 [26]) and random embedding to encode log events. The random embedding generates a unique feature vector for each log event. Therefore, when served only with random embedding, the model can only detect anomalies with the occurrence of log events in log sequences. That is to say, the model has no access to the anomalous information possibly provided by the semantics of the log messages. By comparing the performance of models using these two input features, we can grasp the significance of semantic information in the anomaly detection task. Moreover, we input only the temporal encoding to the model without the semantic embedding of the log events, with the aim of determining the degree to which anomalies can be detected solely by leveraging the temporal information provided by the timestamps of logs. We conduct the experiments with the two temporal encoding methods as in RQ2.
5.3.3 Result
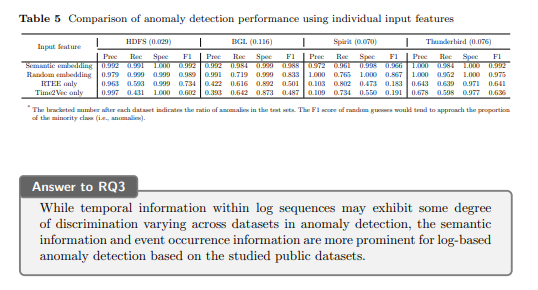
Table 5 illustrates the results of the comparative analysis of anomaly detection performance using single input features across various datasets.
Semantic Embedding vs. Random Embedding Utilizing semantic embedding as the input feature consistently yields high precision, recall, specificity, and F1 scores across all datasets. Conversely, employing random embedding results in slightly lower precision and recall, particularly noticeable in the BGL dataset, underscoring the significance of semantic information in anomaly detection tasks. On the other hand, the models utilizing random embedding of log events as input also demonstrate strong discrimination capabilities regarding anomalies. This underscores the substantial contribution of occurrence information of log events alone to the tasks of anomaly detection. Such results validate the efficacy of employing straightforward vectorization methods (e.g., MCV) for representing log sequences.
The role of temporal information
Analyzing the performance of models with temporal encodings as inputs across different datasets sheds light on the correlation between temporal information and anomalies in anomaly detection. Although there are variations in the numerical values, both temporal encoding methods consistently exhibit similar trends across datasets. Notably, the F1 scores of RTEE-only and Time2Vec-only models vary across datasets, indicating dataset-specific influences on anomaly detection. For instance, in the Spirit dataset, both RTEE-only and Time2Vec-only models exhibit lower F1 scores compared to other datasets, suggesting challenges in associating anomalies with the temporal patterns within the Spirit logs. In contrast, within the Thunderbird dataset, the temporal-only models demonstrate a discernible level of discriminatory capability towards anomalies, as evidenced by F1 scores of 0.641 and 0.636, indicating a more pronounced association between temporal data and annotated anomalies in this dataset.
From the results in RQ2, we find that the inclusion of temporal encoding to the input feature of the Transformer-based model induces a performance loss. However, the experimental results in this RQ demonstrate that the temporal information displays some degree of discrimination, albeit to varying extents across different datasets. The findings suggest that semantic information and event occurrence information are more prominent than temporal information in anomaly detection. Most anomalies within public datasets may not be associated with temporal anomalies and can be easily identified with log events concerned.
:::info
Authors:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info
This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::







{kind=link}