Authors:
(1) Clemencia Siro, University of Amsterdam, Amsterdam, The Netherlands;
(2) Mohammad Aliannejadi, University of Amsterdam, Amsterdam, The Netherlands;
(3) Maarten de Rijke, University of Amsterdam, Amsterdam, The Netherlands.
Table of Links
Abstract and 1 Introduction
2 Methodology and 2.1 Experimental data and tasks
2.2 Automatic generation of diverse dialogue contexts
2.3 Crowdsource experiments
2.4 Experimental conditions
2.5 Participants
3 Results and Analysis and 3.1 Data statistics
3.2 RQ1: Effect of varying amount of dialogue context
3.3 RQ2: Effect of automatically generated dialogue context
4 Discussion and Implications
5 Related Work
6 Conclusion, Limitations, and Ethical Considerations
7 Acknowledgements and References
A. Appendix
4 Discussion and Implications
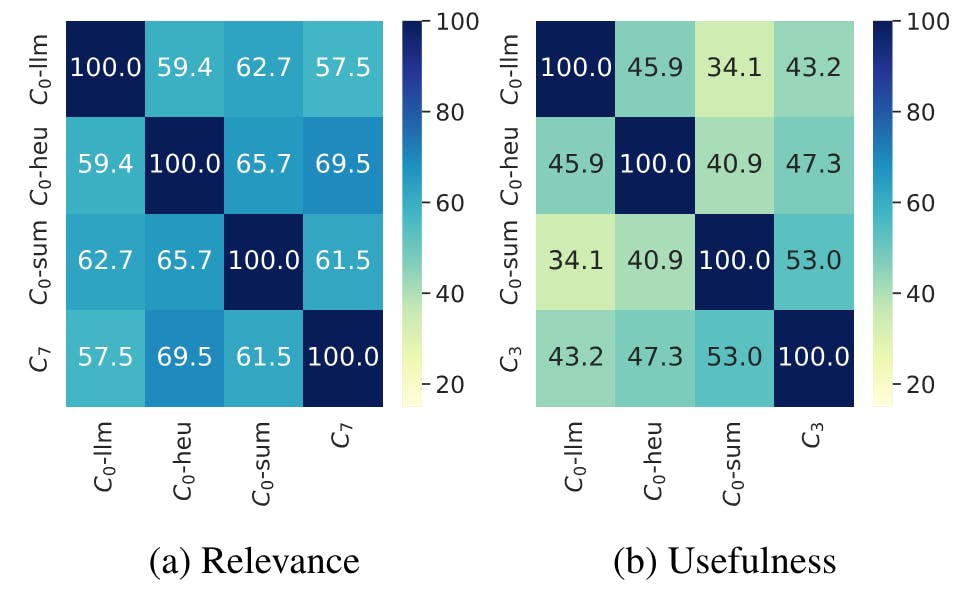
Our findings reveal intriguing insights into the impact of context size and type on crowdsourced relevance and usefulness labels for TDS. Expanding the dialogue context from C0 to C7 significantly improves agreement among annotators, indicating that annotators rely on comprehensive context to make more accurate assessments. This trend does not hold for usefulness, where we notice a decrease in agreement when all previous dialogue context is available. The optimal amount of context required for reliable labels relies on the aspect evaluated.


Consistent with prior work (Eickhoff, 2018; Kazai et al., 2011a), we observe an inconsistency in relevance labels across variations, with the same system response being rated differently depending on the context provided. Given the lack of label consistency across variations, future studies should carefully tailor their annotation task design and test various settings to ensure high-quality and consistent labels. Additionally, much care should be taken when comparing the performance of a system across several datasets when labels are crowdsourced with a different strategy to ensure a fair comparison as models similar to humans can be sensitive to the annotation strategy (Kadasi and Singh, 2023; Kern et al., 2023).
We also analyzed data from the open-ended question asking annotators about their experience with the annotation task. Annotators note that dialogue summaries fail to convey a user’s emotion, limiting their annotation process. Additionally, lower accuracy of the context generated by an LLM may lead to low agreement among annotators. This signifies the importance of carefully considering the quality and accuracy of generated content in the evaluation process. We provide examples in Section A.5 in the appendix. While there may be constraints in presenting user information need and dialogue summary as dialogue context, one key consideration to take into account is the cognitive load of annotators. Providing a shorter, focused context reduces the cognitive burden on annotators, allowing them to devote more attention to actually evaluating a response. This not only streamlines the annotation process but also helps maintain high-quality results. Reducing the amount of content to be assessed may lead to faster annotation times without compromising the quality of ratings (Santhanam et al., 2020). Another approach to using LLMs in annotation, is for researchers to consider co-annotation (Li et al., 2023) between humans and LLMs.
Optimal context varies by the aspect under evaluation, challenging the idea of a universal strategy. The consistent reliability of automatic methods suggests their potential as dependable tools for evaluation. This implies their use in generating supplementary context, eliminating the need for manual determination of context amounts. This streamlines evaluation, enhancing efficiency in context driven evaluations for TDS. For data lacking topic or preference shifts, heuristics perform effectively. However, LLMs are recommended for shifting conditions, showcasing adaptability not easily discernible with heuristics.
While our primary focus was limited to relevance and usefulness, the proposed experimental design can be extended to other aspects of TDSs evaluation. Moreover, our findings may be task or dataset-specific, prompting the need for further investigation into their generalizability. As to future work, we aspire to enhance the robustness of our findings by conducting studies on larger-scale datasets. In addition following previous work by Kazai et al. (2012, 2013), we would also want to understand the effect of annotator background: experience of interacting with conversational system or prior experience in doing the annotation task on label consistency for TDSs.
We review related work not covered in the paper so far. Several user-centric dialogue evaluation metrics (Ghazarian et al., 2019; Huang et al., 2020; Mehri and Eskenazi, 2020) have been proposed. For TDSs, high-level dimensions such as user satisfaction (Al-Maskari et al., 2007; Kiseleva et al., 2016) and fine-grained metrics such as relevance and interestingness (Siro et al., 2022) have gained interest. Due to the ineffectiveness of standard evaluation metrics such as ROUGE (Lin, 2004), BLEU (Papineni et al., 2002), which show poor correlation with human judgments (Deriu et al., 2021), a significant amount of research on these metrics relies on crowdsourcing dialogue evaluation labels to improve correlation with actual user ratings. Crowdsourcing ground-truth labels has gained momentum in information retrieval (IR) for tasks like search relevance evaluation (Alonso et al., 2008) and measuring user satisfaction in TDS. A major challenge is ensuring quality and consistency of crowdsourced labels. Task design and annotators’ behavioral features and demographics can affect the quality of the collected labels (Hube et al., 2019; Kazai et al., 2012; Pei et al., 2021). Kazai et al. (2013) examine how effort and incentive influence the quality of labels provided by assessors when making relevance judgments. Other factors such as judgment scale (Novikova et al., 2018; Roitero et al., 2021), annotator background (Kazai et al., 2011b; Roitero et al., 2020), and annotators’ demographics (Difallah et al., 2018) have also been studied. Most studies focus on search systems, not dialogue systems. Closer to our work, Santhanam et al. (2020) study the effect of cognitive bias in the evaluation of dialogue systems. Providing an anchor to annotators introduces anchoring bias, where annotators’ ratings are close to the anchor’s numerical value. Like Santhanam et al. (2020), we focus on the effect of task design on the evaluation of TDSs. In particular, we investigate how the amount and type of dialogue context provided to annotators affect the quality and consistency of evaluation labels and the annotator experience during the evaluation task.







{kind=link}