Authors:
(1) Mahdi Goldani;
(2) Soraya Asadi Tirvan.
Table of Links
Abstract and Introduction
Methodology
Dataset
Similarity methods
Feature selection methods
Measure the performance of methods
Result
Discussion
Conclusion and References
Discussion
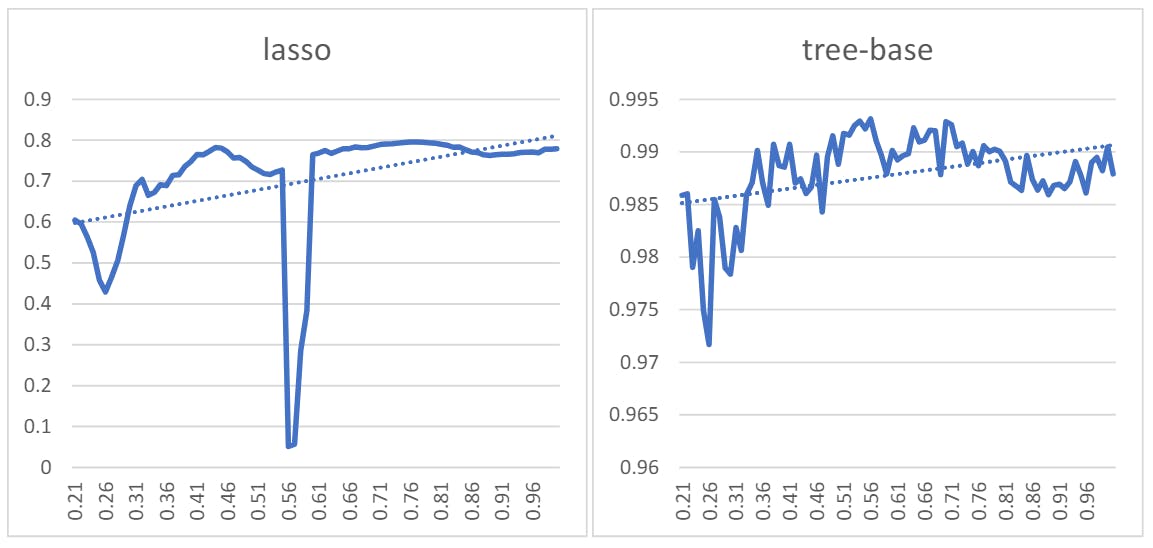
There are three main factors to choose the best method in this research; the value of r-squared, the sensitivity of methods to change in sample size, and fluctuation during change in sample size. Among the methods, on average, variance, stepwise, and correlation methods had the highest r-squared value. The mutual information, var, simulated, edit distance, and Hausdorff methods had less sensitivity to data size. The Variance, simulated, and edit distance had less fluctuation. According to these metrics, the var method had all three criteria. Among the similar methods, Hausdorff and edit distance had good performance in comparison to other methods.
This study focuses on improving the performance of the data-driven model by selecting the most appropriate features. However, it is important to acknowledge certain limitations of this study. First, many existing hybrid methods should be investigated. Second, the results presented may change as the dataset changes.
Conclusion
The aim of this study is to select feature selection techniques that have little sensitivity to low data size and select a subset of data that has high predictive performance in low data size. As mentioned in the results section, based on the dataset used in this study, the performance of standard feature selection methods fluctuates in different data volumes, which can reduce the level of confidence in these techniques. Among the ten standard feature selection methods, two variance and simulated methods are more stable than others. The graphs show that the similarity methods introduced as an alternative to the feature selection methods are less volatile than these methods, which increases the confidence in the results of these methods when the data size is different. Therefore, according to the first approach of this study, the similarity methods are more reliable than the usual feature selection methods. Of course, it is essential to note that these results are only related to one data set, and the results may change in other data sets.
The second and more critical approach that the article sought to test is to examine the sensitivity of the methods to the change in data size. Indeed, any method with the least minor sensitivity to data size change will be chosen. According to trendline results, the variance, correlation methods, simulated methods, edit distance, and Hausdorff are less sensitive to observation size. Considering that time series similarity methods had the most minor fluctuation among other feature selection methods, these methods can be used as reliable methods for feature selection. Similarity methods, such as the Hausdorff and edit distance approaches, emerged as the most stable among the various feature selection techniques evaluated. This robustness across different data sizes underscores their reliability and suitability for this research context. Their consistent performance indicates that they can effectively handle fluctuations in observation numbers without significant loss of predictive accuracy. This resilience is crucial in ensuring the robustness and generalizability of predictive models, particularly in dynamic environments such as financial markets. Consequently, these methods stand out as promising tools for feature selection, offering researchers a dependable approach to identifying relevant variables for predictive modeling tasks, such as forecasting Apple’s closing price.
References
-
E. W. Newell and Y. Cheng, (2016) Mass cytometry: blessed with the curse of dimensionality: Nature Immunology, 17: 890-895. https://doi.org/10.1038/ni.3485
-
B. Remeseiro and V. Bolon-Canedo, (2019) A review of feature selection methods in medical applications: Computers in biology and medicine. 112. https://doi.org/10.1016/j.compbiomed.2019.103375
-
Zhu X, Wang Y, Li Y, Tan Y, Wang G, Song Q. (2019)A new unsupervised feature selection algorithm using similaritybased feature clustering: Comput Intell. 35(1): 2-22. doi:10.1111/COIN.12192
-
Mitra, Pabitra, C. A. Murthy, and Sankar K. Pal. (2002) Unsupervised feature selection using feature similarity: IEEE Transactions on Pattern Analysis and Machine Intelligence 24, 3: 301-312. DOI: 10.1109/34.990133
-
Yu, Qiao, Shu-juan Jiang, Rong-cun Wang, and Hong-yang Wang. (2017) A feature selection approach based on a similarity measure for software defect prediction: Frontiers of Information Technology & Electronic Engineering 18, 11: 1744-1753. https://doi.org/10.1631/FITEE.1601322
-
Shi, Yuang, Chen Zu, Mei Hong, Luping Zhou, Lei Wang, Xi Wu, Jiliu Zhou, Daoqiang Zhang, and Yan Wang. (2022) ASMFS: Adaptive-similarity-based multi-modality feature selection for classification of Alzheimer’s disease: Pattern Recognition 126: 108566. https://doi.org/10.1016/j.patcog.2022.108566
-
Fu, Xuezheng, Feng Tan, Hao Wang, Yanqing Zhang, and Robert W. Harrison. (2006) Feature Similarity Based Redundancy Reduction for Gene Selection: In Dmin, pp. 357-360.
-
Vabalas, Andrius, Emma Gowen, Ellen Poliakoff, and Alexander J. Casson. (2019) Machine learning algorithm validation with a limited sample size: PloS one 14, 11: e0224365.
-
Perry, George LW, and Mark E. Dickson. (2018) Using machine learning to predict geomorphic disturbance: The effects of sample size, sample prevalence, and sampling strategy: Journal of Geophysical Research: Earth Surface 123(11): 2954-2970. https://doi.org/10.1029/2018JF004640
-
Cui, Zaixu, and Gaolang Gong. (2018) The effect of machine learning regression algorithms and sample size on individualized behavioral prediction with functional connectivity features: Neuroimage 178: 622-637. https://doi.org/10.1016/j.neuroimage.2018.06.001
-
Kuncheva, Ludmila I., Clare E. Matthews, Alvar Arnaiz-González, and Juan J. Rodríguez. (2020) Feature selection from high-dimensional data with very low sample size: A cautionary tale. arXiv preprint arXiv:2008.12025.
-
Kuncheva, Ludmila I., and Juan J. Rodríguez. (2018) On feature selection protocols for very low-sample-size data: Pattern Recognition, 81: 660-673. https://doi.org/10.1016/j.patcog.2018.03.012
-
J. Doak, (1992) An evaluation of feature selection methods and their application to computer security: Technical Report CSE-92-18.
-
H. Liu and L. Yu, (2005) Toward integrating feature selection algorithms for classification and clustering, IEEE Transactions on knowledge and data engineering. 17:491-502. 10.1109/TKDE.2005.66
-
C. F. Tsai and Y. T. Sung, (2020) Ensemble feature selection in high dimension, low sample size datasets: Parallel and serial combination approaches, Knowledge-Based Systems. 203. https://doi.org/10.1016/j.knosys.2020.106097
-
U. Mori, A. Mendiburu and J. A. Lozano, (2015) Similarity measure selection for clustering time series databases: IEEE Transactions on Knowledge and Data Engineering, 28:181-195. 10.1109/TKDE.2015.2462369
-
Goldani, Mehdi,( 2022) a review of time series similarity methods, the third international conference on innovation in business management and economics.
-
Palkhiwala, S., Shah, M. & Shah, M. (2022)Analysis of Machine learning algorithms for predicting a student’s grade. J. of Data, Inf. and Manag. 4, 329–341. https://doi.org/10.1007/s42488-022-00078-2
-
A.C. Rencher, W.F.(2012) Christensen, Methods of Multivariate Analysis, Wiley Series in Probability and Statistics, John Wiley & Sons. p. 19.
This paper is available on arxiv under CC BY-SA 4.0 by Deed (Attribution-Sharealike 4.0 International) license.






{kind=link}