I know, it looks impossible. Javascript is not a very performant language, mostly because of its single-threaded model. So if I tell you we’re going to compare 1.8 million votes in a fictional city election, right into the browser, you’ll probably think I’m crazy. A browser would freeze and crash — every time. Guess what? You’d be right. Here is the result with a very popular diff library:


Clearly, it’s not wow time. But with the right techniques — efficient memory management, a streaming architecture, web workers, and batch updates — you can do it. Here’s the proof:


As you can see, even with 1.8 millions objects processed in real time, the UI is perfectly responsive. Most importantly, by injecting small data batches over time, we’ve turned a wait for it delay into a watch it happen experience.
Alright, now let’s dive into the making process.
Challenges
We have three challenges to solve.
-
Achieving top performance.
-
Handling different input formats.
-
Being easy for developers to use.
Performance
The first thing is to avoid blocking the main thread at all costs. So we need asynchronous code, a worker to handle the heavy lifting, and a linear complexity O(n), which means that the execution time grows proportionally with the input size. Additionally, efficient memory management is crucial.
Efficient memory management requires freeing up memory as soon as some data is processed, and also progressively sending the data in chunks to minimize UI updates. For example, instead of sending one million object diffs in a row, we could send groups of a thousand. This would dramatically reduce the number of DOM updates.
Input Format
The second challenge is to handle different kind of input formats. We need to be versatile. We should accept arrays of objects, JSON files, and even data streams. So before starting the diff process, we need to convert everything into a single format: a readable stream.
Developer Experience
Finally, we need to provide a great developer experience. The function must be easy to use, easy to customize. Basically, the user will be able to give two lists to our function. We will compare them, and progressively send back the result.
The simplest way to do it is to expose an event listener, with three kind of events: ondata, onerror, onfinish. Easy peasy.


The ondata event will receive an array of object diffs, called a chunk. The diff should be clear, with a previous value, a current value, an index tracker, and a status — equal, updated, moved, or deleted.
And because I know most of you love TypeScript, we’ll also have autocompletion. Icing on the cake, users will be able to specify options to refine the output. Let’s see how the algorithm works.


Algorithm Walkthrough
For simplicity’ sake, the code we’re going through comes from the streamListDiff function of the @donedeal0/superdiff library.
Let’s take a look at the main function. It takes two lists to compare, a common key across all the objects, like an id for exemple, to match the objects between the two lists, and some options to refine the output.
In the function body, we can see it returns an event listener before starting the diff. The trick is to trigger the logic block asynchronously. Basically, the event loop will execute all synchronous code first, and only then start the real work.


Then, we convert our two lists to readable streams, using different methods for each input type (an array, a file, etc.).


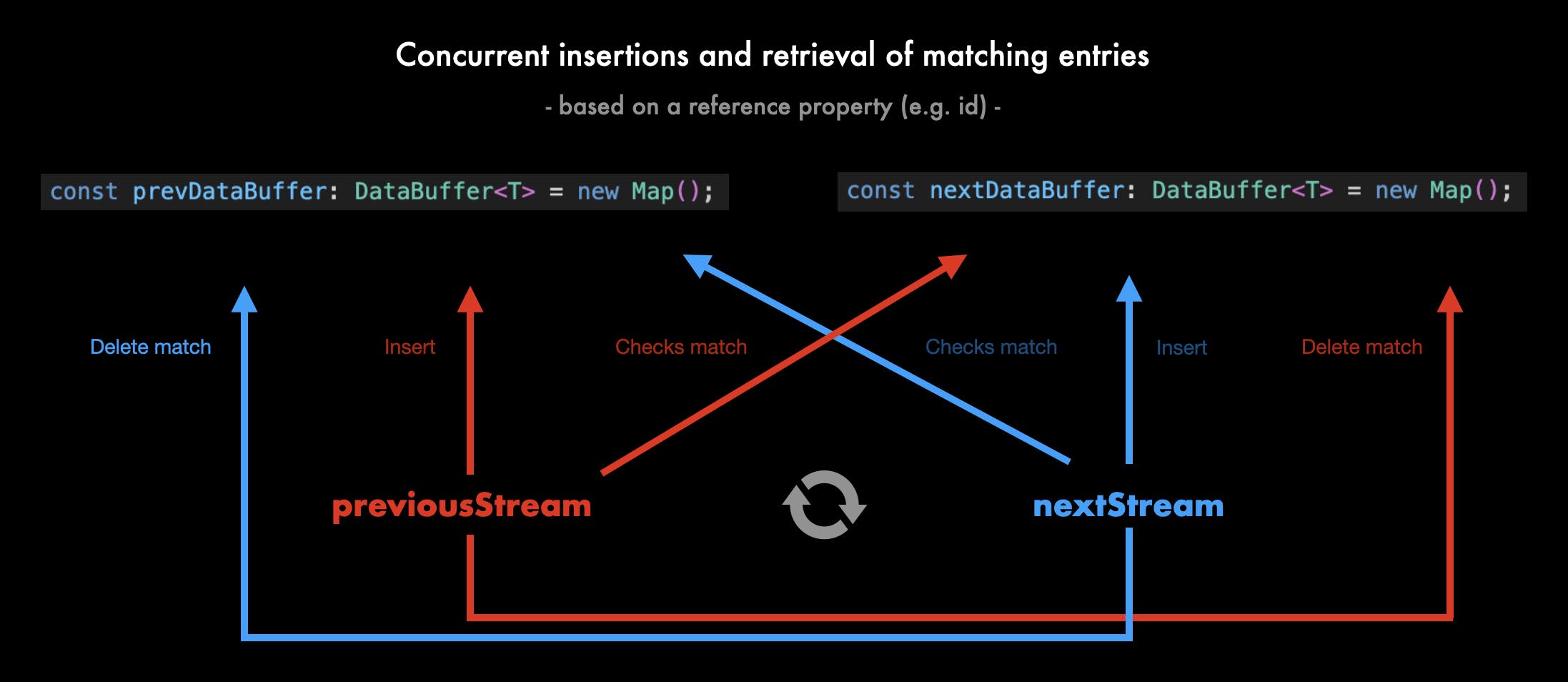
Once we have two valid streams, we iterate over both of them in parallel thanks to Promise.all(). At each iteration, we do two things: first, we check if the object is valid — if not, we emit an error message. Second, we check if an object with a similar reference property is already in the data buffer of the other list.


What’s a data buffer? There are two buffers, one for each list. The idea is to store the unmatched objects in a hashmap so that the other list, which is being parsed at the same moment, can check in real time if there is a match for its current object. This avoids doing two full iterations, with no results and high memory consumption, before starting the real diff. We don’t lose time, and we’re efficient.
We use a hashmap to store unmatched objects because it supports any kind of value as keys, is very performant and provides an iterator out of the box.


Long story short, if there is a match in the buffer, we immediately remove it to free up memory and compare it to the current object. Once we have the object diff, we immediately send it to the user. If we can’t do the comparaison, we insert the object in the relevant buffer, waiting to be compared. Afterward, we simply iterate over each buffer and process the remaining objects in the same way.


Now, you’re probably wondering why we don’t do a single iteration over the first list, and find its match in the second list. Well, if you have a million objects, a find() lookup will be highly inefficient, as it would lead to a huge number of iterations. But the data buffer method lets us retrieve the match with zero performance cost thanks to the has() method.


Earlier, I said we immediately send each object diff to the user. This is partially true. Imagine the user receives a million objects in a row — it could overload the main thread. What we do instead, is store the object diffs in another buffer. Once this buffer reaches a certain size, say a thousand objects, we flush it and send a single batch of data to the user.
To do it, we use a closure. Let’s take a look at the outputDiffChunk function. It has an array to store the diffs and returns two functions: handleDiffChunk and releaseLastChunks. handleDiffChunk receives an object diff and adds it to the buffer if it’s not full yet. If it’s full, it sends the batch to the user. Since we use a single instance of handleDiffChunk, the context of outputDiffChunk is preserved, which is why we can access the diff buffer each time we process a new object diff.


Finally, releaseLastChunks is self-explanatory. Once all diffs are processed, it flushes the diff buffer one last time and send the remaining data to the user.
Ultimately, we emit a finish event, and that’s all.
One more thing
The demo we saw earlier uses virtualized list to render massive amounts of items in the DOM, and also takes advantage of requestAnimationFrame to avoid updating it too often.
As a result, everything runs really smooth. It seems like John Doe has been elected, congratulation to him!
LINKS
Repository | Documentation | Npm




{kind=link}