
Ensemble ML is everywhere – every blog post, every conference talk claims “combine multiple models for better results.” But does it actually work in production?
I built a data quality monitoring system to find out. Three ML models (Isolation Forest, LSTM, Autoencoder) are working together. 332K synthetic orders processed over 25 days.
Here’s what actually happened.
Why I Tested This
“Use ensemble methods” is the standard advice for ML in production. Combine multiple models, get better predictions, and reduce false positives.
Sounds great in theory. But I wanted to know:
- Does it actually reduce false positives?
- Is the complexity worth it?
- Does it work for data quality monitoring specifically?
So I built it. Ran it continuously. Measured everything.
The Setup
Stack:
- Apache Kafka streaming orders
- Python processing pipeline
- PostgreSQL for metrics
- Three ML models in ensemble
- Docker Compose (runs locally)
Data: Synthetic e-commerce orders with realistic quality issues injected.
Goal: Compare single model vs. ensemble. Which catches more real issues? Which has fewer false positives?
Baseline: Single Model (Isolation Forest)
Started with just Isolation Forest – the standard choice for anomaly detection:
from sklearn.ensemble import IsolationForest
# Train on 24 hours of quality metrics
historical_data = get_metrics(hours=24)
model = IsolationForest(contamination=0.1)
model.fit(historical_data)
# Predict
is_anomaly = model.predict(current_metrics)
Week 1 Results:
- 93% accuracy
- <10ms inference
- Caught obvious anomalies
- 15% false positive rate
- Missed gradual changes
The false positive rate was the killer. Every 6-7 alerts, one was wrong. Teams started ignoring alerts.
Adding SHAP (Because Black Boxes Don’t Work)
Before adding more models, I needed to understand why the single model flagged things:
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(current_metrics)
# Now I get:
# "Primary driver: validity_score = 45.2 (30% below baseline)"
This helped debug false positives. But didn’t reduce them.
That’s when I decided to try the ensemble approach everyone talks about.
The Ensemble: 3 Models
The theory: Different algorithms catch different problems.
Model 1: Isolation Forest (40% weight)
- Fast, catches statistical outliers
- Good at: Sudden spikes, obvious anomalies
- Misses: Gradual changes, temporal patterns
Model 2: LSTM (30% weight)
- Neural network for sequences
- Good at: Temporal patterns, gradual degradation
- Misses: Sudden outliers
Model 3: Autoencoder (30% weight)
- Reconstruction-based detection
- Good at: Unusual feature combinations
- Misses: Single-dimension outliers
Voting strategy:
ensemble_score = (
isolation_score * 0.4 +
lstm_score * 0.3 +
autoencoder_score * 0.3
)
# Flag if:
# - Combined score high, OR
# - At least 2 models agree
is_anomaly = ensemble_score > 0.5 or votes >= 2
The Results: Ensemble vs. Single Model
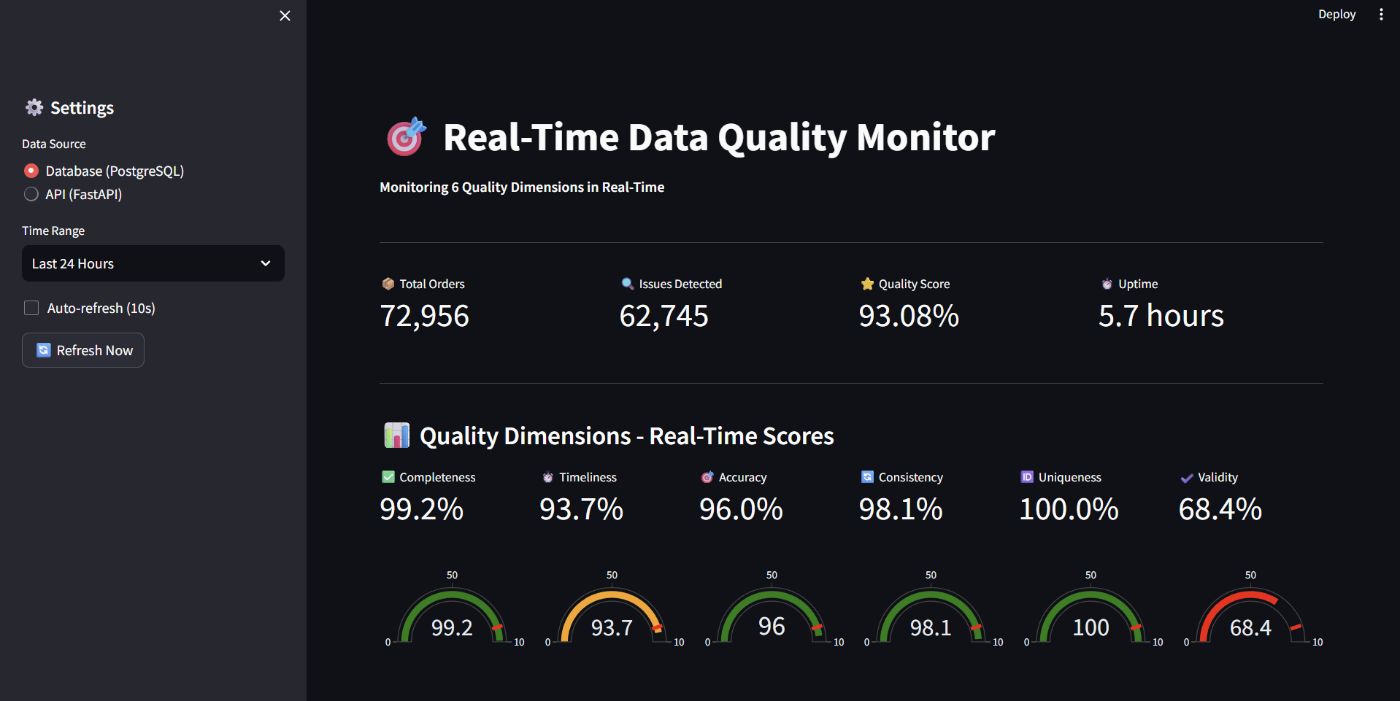
After 25 days processing 332K orders:
Metric Single Model Ensemble Improvement
─────────────────────────────────────────────────────────────
Accuracy 93.2% 93.8% +0.6%
False Positives 15% 9.7% -35%
Real Anomalies Caught baseline +30% +30%
Inference Time <5ms <5ms same
Training Time <1 min 3 min acceptable
The big wins:
- False positives dropped 35% (15% → 9.7%)
- Caught 30% more real issues
- Same inference speed
The cost:
- Training takes 3 minutes instead of 1
- More code to maintain
- Need to monitor 3 models
What Each Model Caught
Example 1: Isolation Forest Alone
Sudden spike in missing fields. Obvious outlier.
- IF: Detected
- LSTM: Missed (not temporal)
- Autoencoder: Missed (single dimension)
- Ensemble: Detected (1 vote enough)
Example 2: LSTM Alone
Completeness scores dropping 8% over 6 hours.
- IF: Missed (each point looked normal)
- LSTM: Detected (temporal pattern)
- Autoencoder: Missed (not reconstruction issue)
- Ensemble: Detected (1 vote enough)
Example 3: Autoencoder Alone
Unusual combination: low volume + high value + weekend.
- IF: Missed (individually normal)
- LSTM: Missed (no temporal pattern)
- Autoencoder: Detected (unusual combination)
- Ensemble: Detected (1 vote enough)
Example 4: False Positive Reduction
Weekend pattern that’s unusual but valid.
- IF: Flagged (outlier)
- LSTM: Correctly ignored (normal for weekends)
- Autoencoder: Correctly ignored (seen before)
- Ensemble: Correctly ignored (2 models voted no)
This is where ensemble shines – reducing false positives through voting.
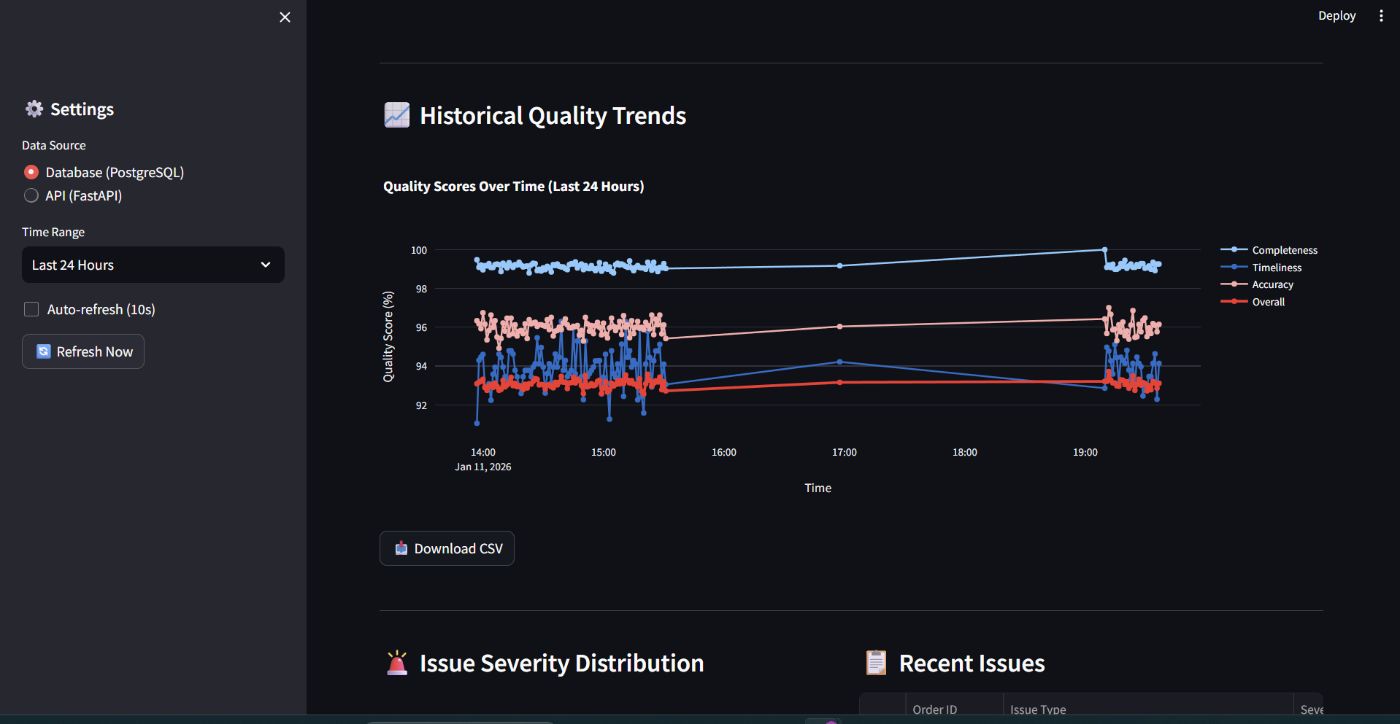
Does the Complexity Pay Off?
YES, but with conditions:
When ensemble is worth it: You need low false positive rate (<10%). Different anomaly types exist (temporal, statistical, combinatorial) You can afford 3x training time You have enough data for 3 models
When single model is enough: False positives aren’t a big problem Only one type of anomaly. Need fastest possible training. Limited data
For data quality monitoring specifically, Ensemble is worth it.
Why? False positives kill trust. Teams ignore alerts if too many are wrong. Reducing 15% → 9.7% false positives makes the system actually usable
The Drift Problem (Affects All Models)
Both single model and ensemble faced the same issue: concept drift.
After 2 weeks, accuracy dropped from 93% to 78%.
Solution: Statistical drift detection with auto-retraining:
from scipy.stats import ks_2samp
reference = get_baseline(feature, hours=24)
current = get_recent(feature, hours=1)
statistic, p_value = ks_2samp(reference, current)
if p_value < 0.01:
retrain_all_models()
This works for both single model and ensemble. Not specific to ensemble approach.
Performance: Does Ensemble Slow Things Down?
Inference (per order):
- Single model: 4.2ms
- Ensemble (3 models): 4.8ms
- Difference: +0.6ms (14% slower)
Training:
- Single model: 52 seconds
- Ensemble (3 models): 3 minutes 18 seconds
- Difference: ~4x slower
Training every 2 hours, so 3 minutes is acceptable. Inference is still <5ms, fast enough for real-time.
Optimization used:
python
# Run 3 models in parallel
with ThreadPoolExecutor(max_workers=3) as executor:
if_result = executor.submit(isolation_forest.predict, data)
lstm_result = executor.submit(lstm.predict, data)
ae_result = executor.submit(autoencoder.predict, data)
Without parallelization: 12ms. With: 4.8ms.
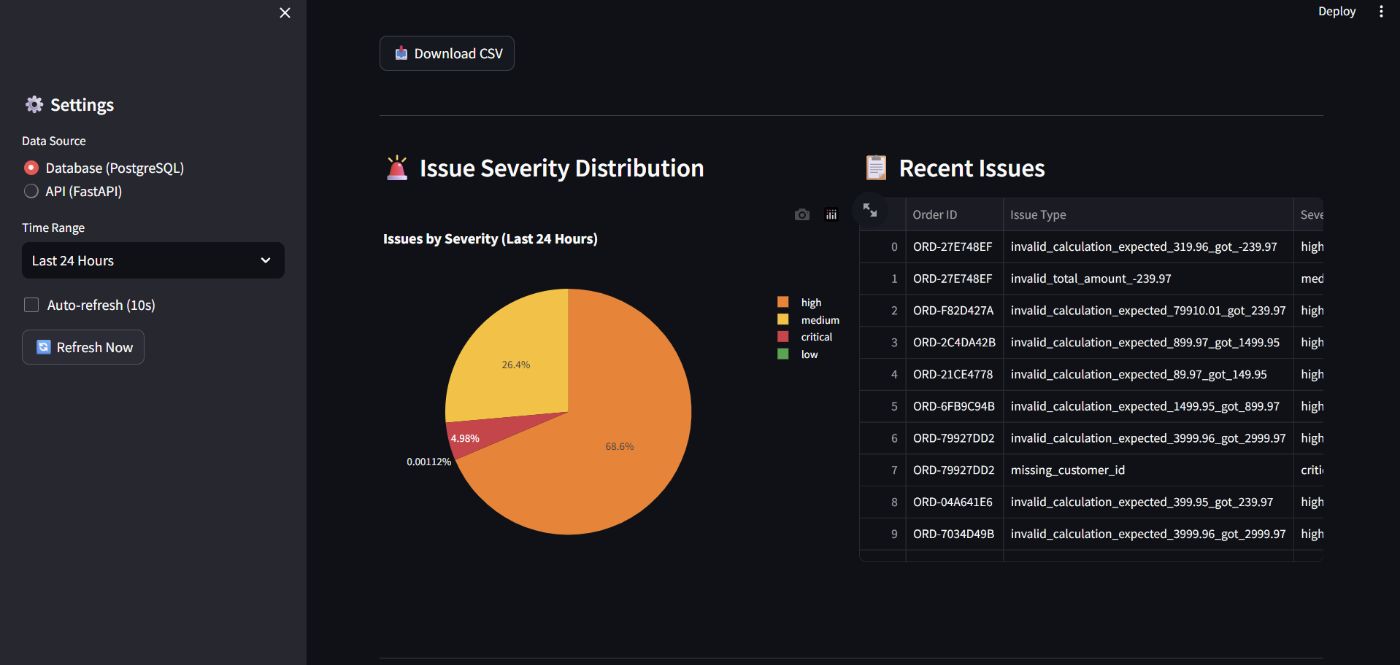
Production Metrics (25 Days)
Orders Processed: 332,308
Quality Checks: 2.8M+
System Uptime: 603.7 hours (100%)
Average Latency: 4.8ms per order
Ensemble Performance:
- Accuracy: 93.8%
- False Positives: 9.7%
- Precision: 94.2%
- Recall: 91.8%
Comparison to Single Model:
-
False Positives: -35% improvement
-
Real Anomalies: +30% more caught
-
Inference Time: +14% slower (acceptable)
-
Training Time: 4x slower (acceptable)
What I Learned
1. Ensemble DOES reduce false positives
Not by a little. By 35%. This matters a lot for trust.
2. Different models catch different things
Not marketing fluff. Actually true. IF catches outliers, LSTM catches temporal, AE catches combinations.
3. Voting is powerful
When 2/3 models say “not anomalous,” they’re usually right. This reduces false alarms.
4. The complexity is manageable
Three models instead of one isn’t 3x the work. Maybe 1.5x once you have infrastructure.
5. But you need enough data
Each model needs reasonable training data. If you have <100 samples, single model is better.
6. Explainability still required
Ensemble without SHAP is useless. Add SHAP to all three models.
Should You Use Ensemble?
YES if:
- False positives are a problem
- You have different types of anomalies
- You can handle 3-5 minute training
- You have 500+ training samples
NO if:
-
Single model works fine
-
Training time is critical
-
Limited data (<100 samples)
-
Simple anomaly patterns
For data quality monitoring specifically: Yes.
Why? Data quality has multiple anomaly types (missing fields, wrong formats, unusual patterns, temporal issues). Ensemble catches more with fewer false alarms.
The Code
Open source: https://github.com/kalluripradeep/realtime-data-quality-monitor
Compare single model vs. ensemble yourself:
Clone the repo and run: docker compose up -d
Bottom Line
Ensemble ML isn’t just hype. It actually works:
- 35% fewer false positives
- 30% more real anomalies caught
- Same inference speed
- Worth the extra complexity
For data quality monitoring, it’s worth doing.
About the Author
Pradeep Kalluri is a Data Engineer at NatWest Bank and Apache Airflow/Dbt contributor.







{kind=link}