
Until now, Alibaba had a great open model for programming. It is based on Qwen3.5-397B-A17B, but the problem is that it was gigantic with its 397 billion parameters and 807 GB of disk (and memory) size. The Chinese company has done something surprising and announced these days the Qwen3.6-27B model, which in its quantized version weighs less than 17 GB. You would think that at that size he would be much worse than his older brother. But you would be wrong. It is proof that it is possible to give for much less.
A dense model. Most large open weights models in 2026 use Mixture-of-Experts (MoE) architecture: they have many parameters in total, but only activate a fraction of them when we use them. For example, the Qwen3.5-397B-A17B model precisely indicated that in its name: of the 397,000 million parameters, it only activated 17,000 million (hence the A17B) when using it.
With Qwen3.6-27B we have what is called a dense model: the 27 billion parameters are activated in each inference. Although it is somewhat less efficient, it has clear practical advantages. For example, there is no need to configure an expert router, and quantization is more predictable and compact. The idea has worked, and the results prove it.
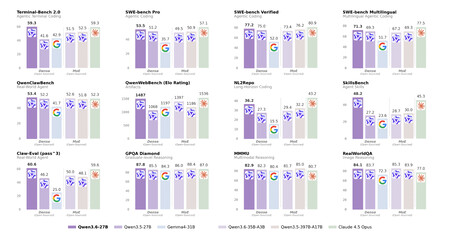
The performance of this “small” AI model is even higher than a much larger previous version.
Benchmarks don’t lie (too much). In SWE-bench Verified, the most popular benchmark for real programming tasks, Qwen3.6-27B achieves 77.2% score compared to 76.2% for the 397B model. In Terminal-Bench 2.0, which measures how well the model executes tasks in the command console, it achieved 59.3% compared to 2.5% for its rival. But in this test it achieves exactly the same score as Claude Opus 4.5, one of the best recent Anthropic models. That an “Open Source” model that can be easily used locally achieves something like this is unusual, but we must be cautious: the benchmarks are from Alibaba itself, and there is currently no independent verification, although those who are using it seem to be really satisfied with it.
Even Alibaba is surprised. What is striking about this launch is that the company that launched it is promoting it above its most ambitious model until recently. That they themselves compare both versions and recognize that the “small” one is the most powerful is significant. It’s like saying from the rooftops that the largest AI models have no competition, when they have just proven that this is not the case and that models like Qwen3.6-27B can be truly remarkable in behavior.

In
A young man has solved a mathematical problem that lasted 60 years in 80 minutes with ChatGPT. That’s the least interesting thing about the story.
24 GB of VRAM is “enough”. Thanks to its small size, it is possible to use this model on relatively accessible machines. Thus, the 24 GB of video memory of the RTX 3090 makes these graphics cards a perfect alternative to install and use Qwen3.6-27B with excellent performance. Dense models do not do so well on MacBook or Mac mini with unified memory, and although logically not everyone has access to graphics cards with 24 GB of RAM, access to really capable local models continues to improve.
The best essences, in small bottles. Alibaba is a steamroller of “small” AI models, and it demonstrated this in early March when it released several ranging from 0.8B to 9B. Fortunately there are varied alternatives in that segment of “Small Language Models” (SLMs) and here we have reference examples such as Gemma 4, recently launched by Google. Microsoft with Phi-4 (which needs an update, like gpt-oss-20b/120b) or Mistral with Devstral 2 are examples that Western companies are also making moves in this interesting field.
{“videoId”:”x9sjece”,”autoplay”:false,”title”:”CHINA is WINNING the TECH WAR because they planned it that way 10 YEARS AGO”, “tag”:”china”, “duration”:”721″}
But. According to benchmarks, Qwen3.6-27b is comparable in some benchmarks to Claude Opus 4.5, Anthropic’s most advanced model when it was launched in November 2025. That is surprising and confirms that open weight models from Chinese companies are, as Demis Hassabis said, between 6 and 12 months behind the most advanced models from Anthropic, OpenAI or Google. But to execute them a significant investment is still necessary, and although local AI models are very interesting in terms of privacy, if today one wants maximum speed and performance it still depends on commercial models in the cloud.
In | Google will invest up to $40 billion in Anthropic because the new normal for AI is investing in your enemy
(function() {
window._JS_MODULES = window._JS_MODULES || {};
var headElement = document.getElementsByTagName(‘head’)(0);
if (_JS_MODULES.instagram) {
var instagramScript = document.createElement(‘script’);
instagramScript.src=”https://platform.instagram.com/en_US/embeds.js”;
instagramScript.async = true;
instagramScript.defer = true;
headElement.appendChild(instagramScript);
}
})();
–
The news
US companies continue to pursue larger and larger AI models. Those from China continue to demonstrate that it is not necessary
was originally published in
by Javier Pastor.







{kind=link}